Redis做为缓存的几个问题
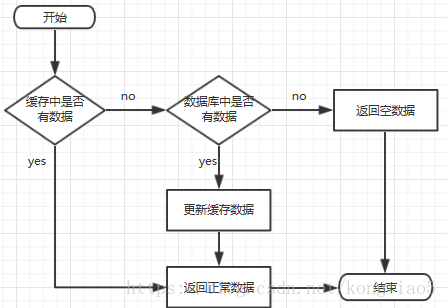
缓存理流程:
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。
1.缓存雪崩

解决方案3:如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
解决方案4:设置热点数据永远不过期。
2.缓存穿透
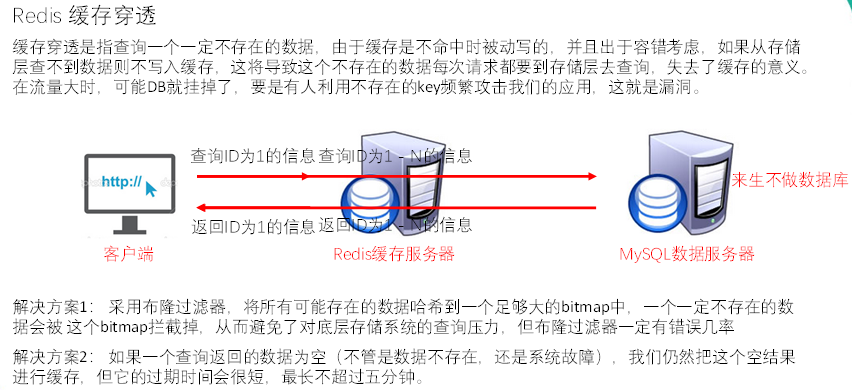
解决方案3:接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
解决方案4:从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。 这样可以防止攻击用户反复用同一个id暴力攻击
3.缓存击穿

解决方案2:设置热点数据永远不过期
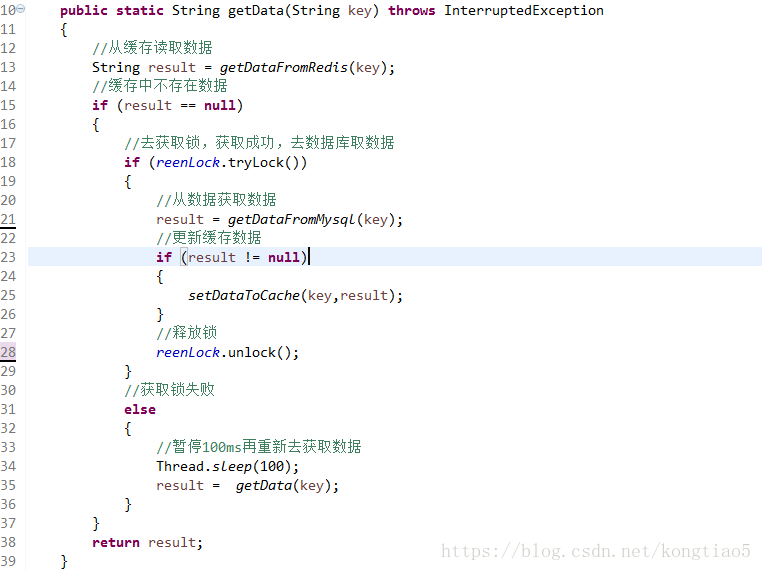
注--------其实,大多数情况下这种爆款很难对数据库服务器造成压垮性的压力。达到这个级别的公司没有几家的。所以,务实主义的小编,对主打商品都是早早的做好了准备,让缓存永不过期。即便某些商品自己发酵成了爆款,也是直接设为永不过期就好了。
大道至简,mutex key互斥锁真心用不上。
4.缓存预热
描述:
新的缓存系统没有任何缓存数据,缓存预热就是系统上线后,在缓存重建数据的过程中,系统性能和数据库负载都不太好,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决方案
1、数据量不大,可以在项目启动的时候自动进行加载
2、定时刷新缓存
5.缓存热备
描述:
缓存热备即当一台缓存服务器不可用时能实时切换到备用缓存服务器,不影响缓存使用。集群模式下,每个主节点都会有一个或多个从节点来当备用,一旦主节点挂点,从节点立即充当主节点使用。
解决方案:
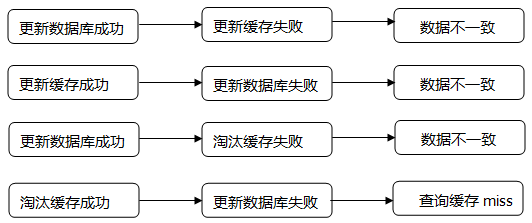
6.缓存一致性问题
当数据时效性要求很高时,需要保证缓存中的数据与数据库中的保持一致,而且需要保证缓存节点和副本中的数据也保持一致,不能出现差异现象。
这就比较依赖缓存的过期和更新策略。一般会在数据发生更改的时,主动更新缓存中的数据或者移除对应的缓存。
7.缓存无底洞问题
该问题由 facebook 的工作人员提出的, facebook 在 2010 年左右,memcached 节点就已经达3000 个,缓存数千 G 内容。
他们发现了一个问题---memcached 连接频率,效率下降了,于是加 memcached 节点,添加了后,发现因为连接频率导致的问题,仍然存在,并没有好转,称之为”无底洞现象”。
目前主流的数据库、缓存、Nosql、搜索中间件等技术栈中,都支持“分片”技术,来满足“高性能、高并发、高可用、可扩展”等要求。有些是在client端通过Hash取模(或一致性Hash)将值映射到不同的实例上,有些是在client端通过范围取值的方式映射的。当然,也有些是在服务端进行的。但是,每一次操作都可能需要和不同节点进行网络通信来完成,实例节点越多,则开销会越大,对性能影响就越大。
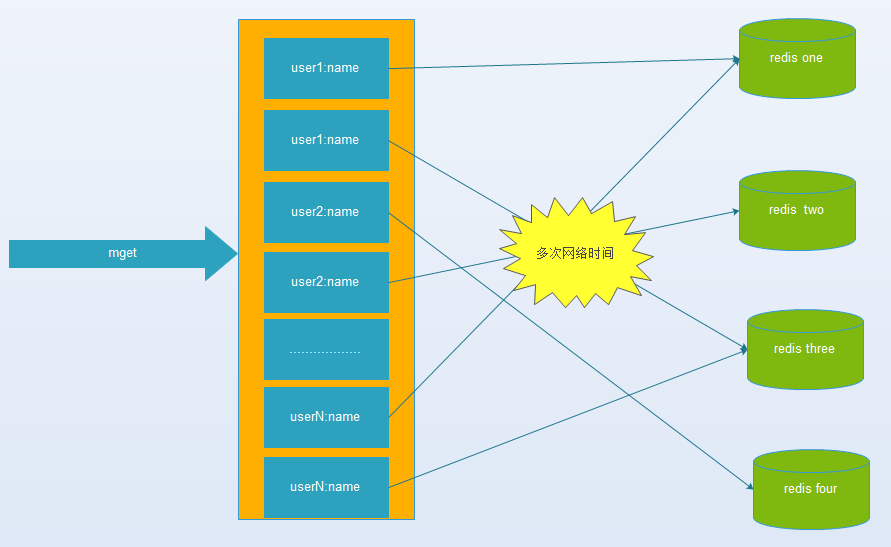
主要可以从如下几个方面避免和优化:
1. 数据分布方式
有些业务数据可能适合Hash分布,而有些业务适合采用范围分布,这样能够从一定程度避免网络IO的开销。
2. IO优化
可以充分利用连接池,NIO等技术来尽可能降低连接开销,增强并发连接能力。
3. 数据访问方式
一次性获取大的数据集,会比分多次去获取小数据集的网络IO开销更小。
当然,缓存无底洞现象并不常见。在绝大多数的公司里可能根本不会遇到。
8.说明
作为一个并发量较大的应用,在使用缓存时有三个目标:
第一,加快用户访问速度,提高用户体验。
第二,降低后端负载,减少潜在的风险,保证系统平稳。
第三,保证数据“尽可能”及时更新。下面将按照这三个维度对上述两种解决方案进行分析。
互斥锁 (mutex key):
这种方案思路比较简单,但是存在一定的隐患,如果构建缓存过程出现问题或者时间较长,可能会存在死锁和线程池阻塞的风险,但是这种方法能够较好的降低后端存储负载并在一致性上做的比较好。
永远不过期
这种方案由于没有设置真正的过期时间,实际上已经不存在热点 key 产生的一系列危害,但是会存在数据不一致的情况,同时代码复杂度会增大。
Redis做为缓存的几个问题的更多相关文章
- Spring Boot使用redis做数据缓存
1 添加redis支持 在pom.xml中添加 <dependency> <groupId>org.springframework.boot</groupId> & ...
- spring boot:使用caffeine+redis做二级缓存(spring boot 2.3.1)
一,为什么要使用二级缓存? 我们通常会使用caffeine做本地缓存(或者叫做进程内缓存), 它的优点是速度快,操作方便,缺点是不方便管理,不方便扩展 而通常会使用redis作为分布式缓存, 它的优点 ...
- Mybatis的二级缓存、使用Redis做二级缓存
目录 什么是二级缓存? 1. 开启二级缓存 如何使用二级缓存: userCache和flushCache 2. 使用Redis实现二级缓存 如何使用 3. Redis二级缓存源码分析 什么是二级缓存? ...
- Redis做LRU缓存
当Redis用作缓存时,通常可以让它在添加新数据时自动逐出旧数据. 这种行为在开发人员社区中非常有名,因为它是流行的memcached系统的默认行为. LRU实际上只是支持的驱逐方法之一. 本页介绍了 ...
- 使用redis做mysql缓存
应用Redis实现数据的读写,同时利用队列处理器定时将数据写入mysql. 同时要注意避免冲突,在redis启动时去mysql读取所有表键值存入redis中,往redis写数据时,对redis主键自增 ...
- spring-boot-route(十二)整合redis做为缓存
redis简介 redis作为一种非关系型数据库,读写非常快,应用十分广泛,它采用key-value的形式存储数据,value常用的五大数据类型有string(字符串),list(链表),set(集合 ...
- redis 做为缓存服务器 注项!
作为缓存服务器,如果不加以限制内存的话,就很有可能出现将整台服务器内存都耗光的情况,可以在redis的配置文件里面设置: # maxmemory <bytes> #限定最多使用1.5GB内 ...
- Python的Flask框架使用Redis做数据缓存的配置方法
flask配置redis 首先得下载flask的缓存插件Flask-Cache,使用pip下载. sudo pip install flask_cache 为应用扩展flask_cache app ...
- SSM+redis整合(mybatis整合redis做二级缓存)
SSM:是Spring+Struts+Mybatis ,另外还使用了PageHelper 前言: 这里主要是利用redis去做mybatis的二级缓存,mybaits映射文件中所有的select都会刷 ...
随机推荐
- nginx下通过子路径配置多个vue单页应用的方法
千辛万苦在Stack Overflow上找来的,记下吧. https://stackoverflow.com/q/31519505/13651734 我的需求是 首页:/ 项目a:/aaa 项目 b: ...
- js 不同时间格式介绍以及相互间的转换
首先必须要提到的是 Date 对象,它用来处理时间和日期. 使用 new Date() 语句可创建 Date 对象,创建出来的时间格式如下(后面提到的标准时间都是指该格式): Wed Jul 17 2 ...
- Spring之多数据源切换的应用
这不是一个新的知识点扩展,顶多算是,Spring的AOP特性的一个应用.那么下面开始今天的学习之旅! 场景 数据库读写分离,或者分库,总之多数据源的场景,怎么样实现自动切换(PS:不考虑各种分库分表的 ...
- pip 安装使用国内镜像
pip国内的一些镜像 阿里云 https://mirrors.aliyun.com/pypi/simple/中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple ...
- 检查*.ldf为何这么大
testdb,只是个测试用文件,备份时突然发现*.ldf怎么这么大,当硬盘不要花银子买啊......--可随意删除...,有空再检查,累了休息... 如批量生成数据.或导入那个来自MySQL的Empl ...
- Java中泛型的继承
最新在抽取公共方法的时候,遇到了需要使用泛型的情况,但是在搜索了一圈之后,发现大部分博客对于继承都说的不太清楚,所幸还有那么一两篇讲的清楚的,在这里自己标记下. 以我自己用到的代码举例,在父类中使用了 ...
- WPS2016ProPlus_normal 安装包+序列号
WPS OFFICE 2016 安装 链接:https://pan.baidu.com/s/1dfjNFDxcl1n2fvYTt9c86A 提取码: ij8e 下载解压:.txt是序列号,.exe是安 ...
- Android学习笔记数组资源文件
在android中我们可以通过数组资源文件,定义数组元素. 数组资源文件是位于values目录下的 array.xml <?xml version="1.0" encodin ...
- 使用addEventListener绑定事件是关于this和event记录
DOM元素使用addEventListener绑定事件的时候经常会碰到想把当前作用域传到函数内部,可以使用以下两种放下: var bindAsEventListener=function (objec ...
- 新老单点的改造——-理解Cookie、Session、Token
近期参与了新老单点的改造,一直想总结一下,发现这篇文章比较贴切. 整理了如下: 随着交互式Web应用的兴起,像在线购物网站,需要登录的网站等等,马上就面临一个问题,那就是要管理会话,必须记住哪些人登录 ...