使用OpenMP与AVX优化矩阵乘法
使用OpenMP与AVX优化矩阵乘法
由于课设内容做的太过简(mo)单(yu),于是在去年12月初的时候就计划写三篇博客随笔作为实验报告,前两篇简单介绍了OpenMP和SIMD指令进行铺垫,本篇将会介绍他的应用场景——优化矩阵乘法。
前两篇的传送门:
1.循环顺序调整
先来看看最基本的矩阵乘法。
void MatrixMul(int **A, int **B, int **C, int size)
{
for (int i = 0; i < size; i++)
for (int j = 0; j < size; j++)
for (int k = 0; k < size; k++)
C[i][j] += A[i][k] * B[k][j];
}
这是一个普通的方阵的乘法函数,用于计算矩阵C = A x B。
线性代数中的矩阵乘法原理告诉我们,只要遵循下面这个原则进行计算就能得到正确结果。
C[i][j] += A[i][k] * B[k][j]
所以,改变循环中ijk的遍历顺序并不会影响结果的正确性。又因为后续使用AVX时需要载入一段连续的内存空间,当前ijk的顺序下最内层循环改变的是k,这就导致B是逐行也就是非连续访问。这既不利于AVX载入数据,也不利于Cache访问。因此我们这里将循环顺序改为ikj,这样就能实现内存的连续访问。
void MatrixMul(int **A, int **B, int **C, int size)
{
// 改为ikj的循环顺序
for (int i = 0; i < size; i++)
for (int k = 0; k < size; k++)
for (int j = 0; j < size; j++)
C[i][j] += A[i][k] * B[k][j];
}
2.使用AVX指令优化
2.1分析
在开始之前,若是不熟悉AVX指令的用法的话,可以先回顾上一篇的内容SSE与AVX指令基础介绍与使用。
在上一步进行调整循环顺序之后,内部已经能够连续访问数据了。现在我们就需要分析,如何用AVX将多次循环合并以提升效率。
for (int j = 0; j < size; j++)
C[i][j] += A[i][k] * B[k][j];
我们可以看到,循环最内层的操作有两步。第一步,将A[i][k]乘上B[k][0]B[k][size-1]。第二部,将第一步乘法的结果加到C[i][0]C[i][size-1]中。
2.2乘法优化
由于最内层循环中A[i][k]并没有改变,所以只需要在循环开始的时候进行一次载入。并且每个数字B[k][j]都是与相同的A[i][k]相乘,所以每个单元都要写入相同的A[i][k],这就需要使用_mm256_set1_epi32方法进行复制型的加载。
__m256i ra = _mm256_set1_epi32(A[i][k]);
A[i][k]加载完毕后就需要加载B矩阵的内容,这里使用上篇介绍的类型转换就能完成。
// 两种取址方法
__m256i rb = *(__m256i *)(B[k] + j);
__m256i rb = *(__m256i *)(&B[k][j]);
乘法方面注意要使用mullo才能得到每一位相乘的结果。mullo是保存每一个结果的低位,mulhi是保存高位,而mul则是用双倍的空间同时保存低位和高位,这样会导致只能保存一半的乘法结果。
rb = _mm256_mullo_epi32(ra, rb);
2.3加法优化
加法和乘法同理,读取C矩阵的内容。
// 两种取址方法
__m256i rc = *(__m256i *)(C[i] + j);
__m256i rc = *(__m256i *)(&C[i][j]);
和乘法的结果相加。
rc = _mm256_add_epi32(rb, rc);
最后用类型转换的方式写回。
*(__m256i *)(C[i] + j) = rc;
2.4最终结果
AVX一次处理256位数据,也就是8个int,因此循环的步进也需要改为8。另外为了防止越界访问,还需要判断剩余的数据是否大于8个,当内容不足8个时则使用普通的逐个相乘计算。
综上所属,初步的优化结果如下。别忘了32位内存对齐!
void MatrixMul(int **A, int **B, int **C, int size)
{
for (int i = 0; i < size; i++)
for (int k = 0; k < size; k++)
{
int j = 0;
// AVX优化
__m256i ra = _mm256_set1_epi32(A[i][k]);
for (; j <= size - 8; j += 8)
{
// 乘法
__m256i rb = *(__m256i *)(B[k] + j);
rb = _mm256_mullo_epi32(ra, rb);
// 加法
__m256i rc = *(__m256i *)(C[i] + j);
rc = _mm256_add_epi32(rb, rc);
// 写回
*(__m256i *)(C[i] + j) = rc;
}
// 处理余下内容
for(;j<size;j++)
C[i][j] += A[i][k] * B[k][j];
}
}
上面的代码为了表述思路用了很多不必要的中间步骤和变量,为了提高运行效率还能进一步压行简化。
void MatrixMul(int **A, int **B, int **C, int size)
{
for (int i = 0; i < size; i++)
for (int k = 0; k < size; k++)
{
int j = 0;
// AVX优化
__m256i ra = _mm256_set1_epi32(A[i][k]);
for (; j <= size - 8; j += 8)
{
// 简化版
*(__m256i *)(C[i] + j) = _mm256_add_epi32(*(__m256i *)(C[i] + j), _mm256_mullo_epi32(*(__m256i *)(B[k] + j), ra));
}
// 处理余下内容
for (; j < size; j++)
C[i][j] += A[i][k] * B[k][j];
}
}
接下来看看优化前后的性能差距。
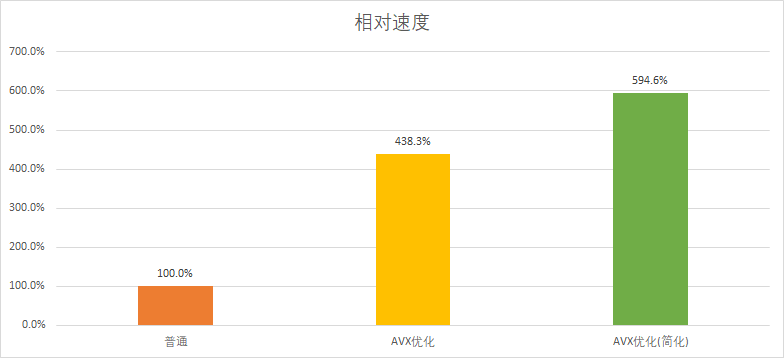
最后得到了近6倍的性能提升,提升幅度还是非常大的。这时候有读者可能会好奇,明明数据吞吐量是原来的8倍,为什么性能却只能提升6倍呢?这其实从简化前后的性能提升也可以看出原因,简化版减少了过程的中间变量,也就是减少了额外的读写开销,但这种开销并不能完全避免,CPU最终还是需要将数据先载入到256位寄存器中计算,然后再从中读取内容写回内存,这种的无法避免额外开销导致了程序始终无法达到8倍的性能提升。
3.使用OpenMP优化
相较于AVX,OpenMP在使用方面就简单了许多,第一篇中我们也对其进行了简单的介绍OpenMP优化for循环的基础运用。
在这里只需要在最外层循环上放加上一句#pragma omp parallel for 即可,当然也可以在末尾加上num_threads(N)设置使用的线程数为N。
void MatrixMul(int **A, int **B, int **C, int size)
{
#pragma omp parallel for num_threads(4) // 设置为4线程
for (int i = 0; i < size; i++)
for (int k = 0; k < size; k++)
for (int j = 0; j < size; j++)
C[i][j] += A[i][k] * B[k][j];
}
接下来我们来测试一下OpenMP在不同线程下的性能变化,测试平台使用的是4C/8T的CPU。
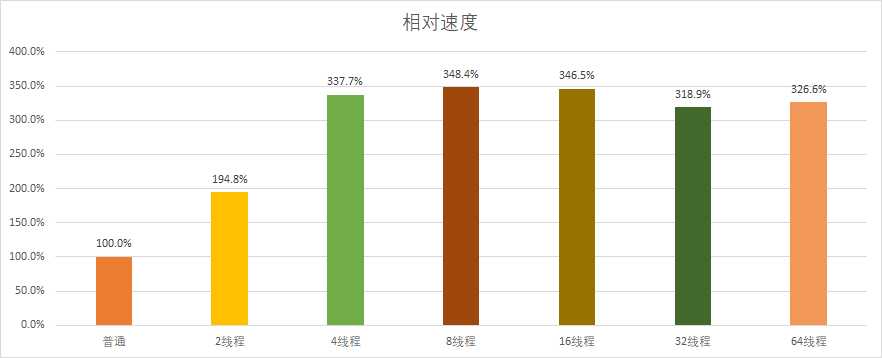
可以看到,OpenMP在2和4线程时性能提升最大,8线程达到顶峰,后续开始出现下降。其中2线程时最接近理论性能提升,到4线程时则开始和理论性能差距拉大。这是由于多线程任务需要系统进行调度,线程调度和开关的损耗会随着则线程数增加而增长,并且当线程数超过物理CPU规模时也无法达到实际的并行效果,从而使提升速度放缓乃至出现下降。
4.综合OpenMP与AVX
在前面分别使用了OpenMP和AVX之后,现在我们来将二者同时运用起来,只需要在AVX的基础上在最外层循环上方加上OpenMP指令即可。
void MatrixMul(int **A, int **B, int **C, int size)
{
#pragma omp parallel for num_threads(4) // OpenMP优化(4线程)
for (int i = 0; i < size; i++)
for (int k = 0; k < size; k++)
{
int j = 0;
// AVX优化
__m256i ra = _mm256_set1_epi32(A[i][k]);
for (; j <= size - 8; j += 8)
{
// 简化版
*(__m256i *)(C[i] + j) = _mm256_add_epi32(*(__m256i *)(C[i] + j), _mm256_mullo_epi32(*(__m256i *)(B[k] + j), ra));
}
// 处理余下内容
for (; j < size; j++)
C[i][j] += A[i][k] * B[k][j];
}
}
然后来看看同时运用上OpenMP和AVX后的性能变化。
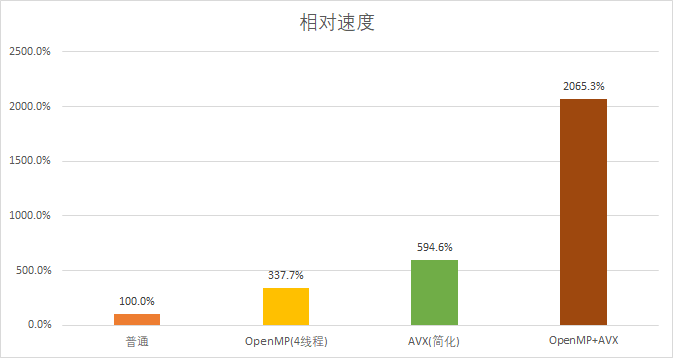
最后的提升基本就是二者实际提升的结果相乘,还是挺理想的。
5.实际应用(图像翻转程序)
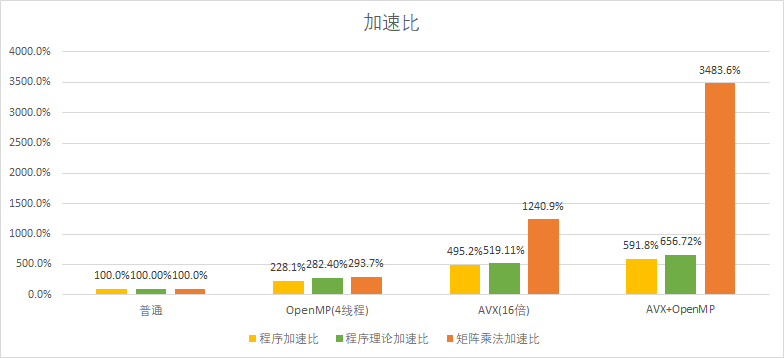
最后来看一个实际应用,这里使用的是一个图像翻转程序,实现原理就是先读取图像的rgb值并用矩阵保存,之后再将图像矩阵乘一个转置矩阵实现翻转效果。而本次实验的内容,就是通过加速矩阵乘法的方式加速图像翻转程序。
图像的rgb值分别用3个char矩阵保存,但是由于Intel的SIMD指令集中并没有epi8的乘法指令,所以最低只能使用16位的short数组进行AVX加速,所以本次的AVX优化的for循环步进提升到了一次16个数据。
本文发布于2023年1月4日
最后修改于2023年1月4日
使用OpenMP与AVX优化矩阵乘法的更多相关文章
- OpenACC 优化矩阵乘法
▶ 按书上的步骤使用不同的导语优化矩阵乘法 ● 所有的代码 #include <iostream> #include <cstdlib> #include <chrono ...
- Strassen优化矩阵乘法(复杂度O(n^lg7))
按照算法导论写的 还没有测试复杂度到底怎么样 不过这个真的很卡内存,挖个坑,以后写空间优化 还有Matthew Anderson, Siddharth Barman写了一个关于矩阵乘法的论文 < ...
- poj3613:Cow Relays(倍增优化+矩阵乘法floyd+快速幂)
Cow Relays Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 7825 Accepted: 3068 Descri ...
- 利用Cayley-Hamilton theorem 优化矩阵线性递推
平时有关线性递推的题,很多都可以利用矩阵乘法来解决. 时间复杂度一般是O(K3logn)因此对矩阵的规模限制比较大. 下面介绍一种利用利用Cayley-Hamilton theorem加速矩阵乘法的方 ...
- [转]OpenBLAS项目与矩阵乘法优化
课程内容 OpenBLAS项目介绍 矩阵乘法优化算法 一步步调优实现 以下为公开课完整视频,共64分钟: 以下为公开课内容的文字及 PPT 整理. 雷锋网的朋友们大家好,我是张先轶,今天主要介绍一下我 ...
- 基于OpenMP的矩阵乘法实现及效率提升分析
一. 矩阵乘法串行实现 例子选择两个1024*1024的矩阵相乘,根据矩阵乘法运算得到运算结果.其中,两个矩阵中的数为double类型,初值由随机数函数产生.代码如下: #include <i ...
- [BZOJ 1009] [HNOI2008] GT考试 【AC自动机 + 矩阵乘法优化DP】
题目链接:BZOJ - 1009 题目分析 题目要求求出不包含给定字符串的长度为 n 的字符串的数量. 既然这样,应该就是 KMP + DP ,用 f[i][j] 表示长度为 i ,匹配到模式串第 j ...
- bzoj 3240: [Noi2013]矩阵游戏 矩阵乘法+十进制快速幂+常数优化
3240: [Noi2013]矩阵游戏 Time Limit: 10 Sec Memory Limit: 256 MBSubmit: 613 Solved: 256[Submit][Status] ...
- HDU 4914 Linear recursive sequence(矩阵乘法递推的优化)
题解见X姐的论文 矩阵乘法递推的优化.仅仅是mark一下. .
- 矩阵乘法优化DP
本文讲一下一些基本的矩阵优化DP的方法技巧. 定义三个矩阵A,B,C,其中行和列分别为$m\times n,n \times p,m\times p$,(其中行是从上往下数的,列是从左往右数的) $C ...
随机推荐
- 使用Java线程同步工具类CyclicBarrier
如何使用 java.util.concurrent.CyclicBarrier是Java并发并发编程中的线程同步工具类,基于java.util.concurrent.locks.ReentrantLo ...
- 记一个 Andorid 生成文件失败的bug
Android生成文件失败:java.lang.IllegalStateException:Failed to build unique file: /storage/emulated/0/... 1 ...
- vue upload 图片转base64、转二进制数组,保存编码数据到文件
功能需求 1.图片转base64 2.base 64 转二进制数组 3.保存二进制数据到文件下载到本地 解决方法 问题1: 参考资料 vue element upload图片 转换成base64 具体 ...
- [Linux] ubuntu系统使用zfs记录
关于zfs 之前从B站视频里面了解到了btrfs这个文件系统,说是能够实现cow,然后我第一时间觉得这是个极好的特性,结果后来才发现,使用的时候并不多,而且只能通过cp --reflink的方式使用, ...
- spring源码手写aop
AOP: aop切面编程,其实就是spring增强器的一个扩展,就是通过beanPostProcessor的after后置方式实现的,其中在after中把需要的bean通过放射+动态代理完 ...
- 精贴总结 - Serverless 的承诺都兑现了吗
原文 - Serverless 的承诺都兑现了吗? 一.个人看法 serverless根本目的是降低成本,所以baas是核心 冷启动是关键的技术难点,也限制了faas的作用域 供应商锁定是个坑,标准化 ...
- SqlServer复制和订阅(实现主从同步)
SqlServer复制和订阅 注意: 1.登录必须是服务器名称不能是ip 2.订阅服务器不需要提前创建数据库 复制 1.展开要发布的数据库节点,找到复制下的本地发布 2.右击本地发布,选择本地发布 3 ...
- 基于Linux的DockerFile添加中文字体
FROM openjdk:8u332-oraclelinux7 #RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.aliyun.com/g' /etc/apk ...
- jquery之ajax中文乱码解决方案
$.ajax({ dataType : 'json',type : 'POST',url : 'http://localhost/test/test.do',data : {id: 1, type: ...
- linux kernel 中进程间描述符的传递方法及原理
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...