Redis系列24:Redis使用规范
Redis系列1:深刻理解高性能Redis的本质
Redis系列2:数据持久化提高可用性
Redis系列3:高可用之主从架构
Redis系列4:高可用之Sentinel(哨兵模式)
Redis系列5:深入分析Cluster 集群模式
追求性能极致:Redis6.0的多线程模型
追求性能极致:客户端缓存带来的革命
Redis系列8:Bitmap实现亿万级数据计算
Redis系列9:Geo 类型赋能亿级地图位置计算
Redis系列10:HyperLogLog实现海量数据基数统计
Redis系列11:内存淘汰策略
Redis系列12:Redis 的事务机制
Redis系列13:分布式锁实现
Redis系列14:使用List实现消息队列
Redis系列15:使用Stream实现消息队列
Redis系列16:聊聊布隆过滤器(原理篇)
Redis系列17:聊聊布隆过滤器(实践篇)
Redis系列18:过期数据的删除策略
Redis系列19:LRU内存淘汰算法分析
Redis系列20:LFU内存淘汰算法分析
Redis系列21:缓存与数据库的数据一致性讨论
Redis系列22:Redis 的Pub/Sub能力
Redis系列23:性能优化指南
1 Redis 操作规范
1.1 缓存的使用时机判断
- 【建议】系统为单体系统,整体QPS小于200的,不建议草率引入缓存,应该有更多的办法进行效率提升
缓存的引入根据系统的业务流量、应用规模而定,对于系统规模小低并发低流量的应用而言,引入缓存并不会带来性能的显著提升,反而会带来应用的复杂度以及较高的运维成本。 - 【建议】响应能力,数据响应的正常容忍度为0.5s,临界容忍度为2s,当我们发现响应时间超建议值,并没有太大优化空间的时候,可以考虑加入缓存。
说明:建立在对数据具有高效响应的需求的时候,缓存是基于内存映射的,相对于磁盘存取来说会快很多。 - 【建议】热点数据,这边指的是同一个系统中的相对热点数据,20%的数据占据了整个请求周期(比如24小时)的80%的流量,那就建议在这20%的流量上做缓存。
对于热点信息被频繁读取,为避免数据库超载的IO操作的情况下,可以适当使用缓存进行缓冲。 - 【建议】读写比例,缓存应该建立在多读少写(高频读取、低频修改)的业务场景中。
一般读写比要达到 9 : 1,读比例越高越好,这样建立缓存的价值比较大。
1.2 缓存类型的使用建议
1.2.1 数据类型
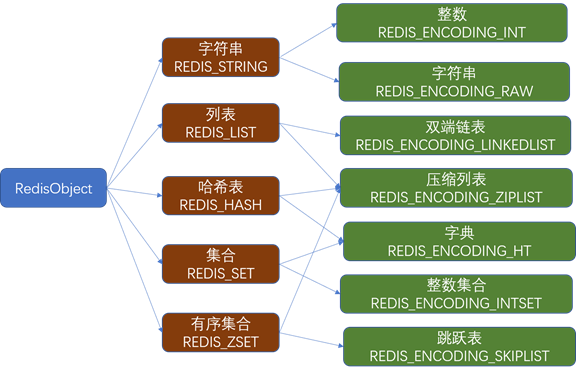
1.2.2 字符文本(REDIS_STRING) 适用场景建议
- 【建议】选型为简易文本类缓存 :比如普通的字符、文本、Json结构 ,通常能起到加速读写和降低后端压力的作用。
- 【建议】计数场景:用于对数值进行增减,同样适用于分布式系统的增量和减量计算
- incr/decr key // 自增1
- incrby/decrby key increment // 增加指定数值
- incrbyfloat/decrbyfloat key increment // 增加一个浮点数
- 【建议】共享Session:在分布式系统中,用户的每次请求会访问到不同的服务器,这就会导致 session 不同步的问题。
1.2.3 列表(REDIS_LIST)适用场景建议
- 【建议】消息队列:列表用来存储多个有序的字符串,既然是有序的,那么就满足消息队列的特点。使用lpush+rpop或者rpush+lpop实现消息队列。
- 【建议】栈:由于列表存储的是有序字符串,满足队列的特点,也就能满足栈先进后出的特点,使用lpush+lpop或者rpush+rpop实现栈。
- 【建议】有序的对象列表:列表的元素不但是有序的,而且还支持按照索引范围获取元素。比如我们可以使用命令
lrange key 0 9分页获取文章列表。
说明:朋友圈的点赞列表、评论列表、排行榜:lpush命令和lrange命令能实现最新列表的功能,每次通过lpush命令往列表里插入新的元素,然后通过lrange命令读取最新的元素列表。
1.2.4 哈希表(REDIS_HASH)适用场景建议
- 【建议】key、field、value结构场景,如购物车:
hset [key] [field] [value]命令, 可以实现以用户Id,商品Id为field,商品数量为value,恰好构成了购物车的3个要素。 - 【建议】对象存储场景:hash类型的(key, field, value)的结构与对象的(对象id, 属性, 值)的结构相似,也可以用来存储对象。
说明:Redis 中的Hash和 Java 的HashMap更加相似,是数组+链表的结构,当发生 hash 碰撞时将会把元素追加到链表上,值得注意的是在Redis的Hash中value只能是字符串。
1.2.5 集合(REDIS_SET)适用场景建议
说明:Redis 中的 Set和Java中的HashSet 类似,内部的键值对是无序、唯一 的。相当于一个特殊的字典,字典中所有的value默认都是一个NULL值。当集合中最后一个元素被移除之后,数据结构被自动删除,内存被回收。
- 【建议】通用的HashSet 集合使用场景,对于Set中的取值、判断、统计,添加跟移出都有很便利的支持。
比如社交领域的 好友、关注、粉丝、感兴趣的人 等场景:- sinter 命令可以获得A和B两个用户的共同好友;
- sismember 命令可以判断A是否是B的好友;
- scard 命令可以获取好友数量;
- 关注时,smove 命令可以将B从A的粉丝集合转移到A的好友集合
- 【建议】Set具备随机获取能力,建议在一些对集合值随机取数场景使用。
类似首页展示随机:美团首页有很多推荐商家,但是并不能全部展示,set类型适合存放所有需要展示的内容,而 srandmember 命令则可以从中随机获取几个。 - 【建议】Set具备Single能力,建议在一些对集合值需要去重的场景中使用。
类似存储某活动中中奖的用户ID ,因为有去重功能,可以保证同一个用户不会中奖两次。
1.2.6 有序集合(REDIS_ZSET)适用场景建议
说明:zset也叫SortedSet,一方面保证了内部 value 的唯一性,另方面它可以给每个 value 赋予一个score,代表这个value的排序权重,所以又具备排序功能。
- 【建议】带排序条件的列表集合,比如排行榜场景,但是和list不同的是zset它能够实现动态的排序,例如: 可以用来存储粉丝列表,value 值是粉丝的用户 ID,score 是关注时间,我们可以对粉丝列表按关注时间进行排序。
另外如 存储学生的成绩, value 值是学生的 ID, score 是他的考试成绩。 我们对成绩按分数进行排序就可以得到他的名次。
1.3 缓存的定义和使用规范
1.3.1 Key 定义规范
- 【必须】key的命名需遵循小写原则,且不允许重复key,否则会产生覆盖情况。
- 【必须】建议使用 “平台缩写“+“”+“项目名”+“”+“业务含义” 的英文作为key的前缀,防止key冲突,用下划线"_" 、":" 或 "." 作为间隔,字符包含A-Z,a-z,0-9,提高可读性和可维护性。
如mt_shop_order、bidu_istio_userinfo - 【必须】禁止使用redis保留字命名key。参考这边
- 【建议】合理控制key的长度,避免使用过长的key或者过简单的key,减少内存消耗并增加易读性,一般key长度不建议超过30字符;
- 【必须】禁止使用特殊字符:如空格、换行符、单双引号及其他转义字符等;
- 【建议】避免使用超大field的复杂类型对象,超大类型的field需要进行切割;
1.3.2 Value 使用规范
- 【必须】禁止使用bigkey,防止网卡流量过载和慢查询,如:string类型控制在10KB以内,hash、list、set、zset 元素个数不要超过5000;
- 【建议】非字符串的bigkey,尽量避免使用整体 del删除,使用hscan、sscan、zscan方式渐进式删除,可pipeline加速,同时要注意防止bigkey过期时间自动删除问题导致的性能损耗;
- 【建议】选择合适的数据类型,节省内存,提高性能; 我们在数据类型的使用规范建议那边有提出了建议。
1.3.3 实例及资源使用规范
- 【建议】单一职责原则:一个业务使用一个实例,避免多个业务共用一个实例;
这个是指做Redis实例拆分的时候,尽量按照业务领域去拆分。并不是指一个业务程序只能调用一个缓存实例。
做隔离一方面是避免业务相互影响,另一方面避免单实例膨胀,并能在故障时降低影响面,快速恢复。 - 【建议】单个实例最大内存占用率使用不能超过实体机的80% 。 指标:保证 ≤ 80%, ≤ 50% 优
- 【建议】单个实例最大CPU占用率使用不能超过实体机的70% 。指标:保证 ≤ 70%以内,≤ 50 % 优
- 【建议】按业务线合理预估内存使用大小(一般为6个月 - 24个月);
- 【建议】分析缓存命中率,缓存的命中率应该高达80%以上,至少不低于 60%,否则需检查是否有不合理的缓存使用。
- 【建议】为缓存实例指定对应的服务应用,同一个服务下的不同实例可以直连访问。其它服务需要访问则要通过接口进行访问。
1.3.4 垃圾回收及失效规范
- 【必须】提前评估数据的生命周期,合理设置数据过期时间和实效策略,如无特殊情况,所有key必须均设置过期时间;
- 【必须】避免使用系统自带的自动过期时间机制;
- 【建议】定期手动清理数据空间,避免僵尸缓存占用空间;
- 【建议】批量建立的缓存需要打散过期时间,防止集中过期导致数据不可恢复带来的影响; 一般我们采用 n * 3/4 + n * random() 。所以,如果是8小时,就是6小时 + 0~2小时的随机值。

- 【必须】尽量避免将缓存持久化,这也是Redis官方的建议,需要将缓存持久化的项(无论是AOF还是RDB)或者无过期时间的项,均需严格报备评审并做记录,无用时需严格销毁。
1.3.5 命令使用规范
- 【建议】控制列表长度N的数量,一般控制在1W以内,有遍历的需求可以使用hscan、sscan、zscan代替;
一个列表最多可以包含 2^32 - 1 个元素 (4294967295, 每个列表超过40亿个元素),但是如果列表太长,就跟它高速缓存的目标相悖 - 【必须】禁止使用keys、flushall、flushdb等操作;
- KEYS:该命令需要对 Redis 的全局哈希表进行全表扫描,严重阻塞 Redis 主线程;(应该使用 scan 来代替,分批返回符合条件的键值对,避免主线程阻塞)
- FLUSHALL:删除 Redis 实例上的所有数据,如果数据量很大,会严重阻塞 Redis 主线程;
- FLUSHDB,删除当前数据库中的数据,如果数据量很大,同样会阻塞 Redis 主线程。(加上 ASYNC 选项,让 FLUSHALL,FLUSHDB 异步执行)
- 【建议】使用批量操作,提高效率,控制一次性操作元素个数,建议为500;
说明:获取集合中的元素(HASH 类型的 hgetall、List 类型的 lrange、Set 类型的 smembers、zrange 等命令)。如果全量或大量操作会对整个底层数据结构进行全量扫描 ,导致阻塞 Redis 主线程。 - 【建议】减少事务的使用(redis暂时不支持事务回滚);
- 【必须】扫描涉及元素数量比较大且设置过期时间的禁止使用scan;
2 Redis 高可用操作规范
说明:本标准以业内现有的主流分布式数据存储服务能力 为参考,建议读者在设计具备高可用缓存服务的时候,可以通过以下几个部分进行衡量。
2.1 高可用集群模式设计
主要包含三种模式:常规的主从模式,哨兵模式,和高扩展的分布式集群,配合使用。读者在在设计的时候,根据业务规模和具体实现情况进行选择。
- 【必须】最低要求,主从集群模式下,需保证如果主库发生故障,能够识别到即对主从进行切换,并利用心跳包进行探活并恢复。
- 【建议】尽量满足,哨兵模式下,会有对应的竞选机制,对故障进行下线,对新主机进行竞选。
- 【建议】尽量满足,分布式集群下,支持对集群的 负载均衡、强事务、故障离群和恢复能力。
★设计建议参考业内竞品作为准入标准,如DBProxy 包含 Sentinal进程,为探活、故障离群和故障恢复提供很好的帮助。
2.2 安全建设能力设计
设计时需要保证如下基本要求:
- 【必须】对于敏感数据进行加密,如身份证、电话、用户住址等,密码类需保证不可逆。
- 【必须】支持IP黑白名单配置,避免非法IP的恶意访问。
- 【必须】对于SQL入侵、注入有比较好的检测和隔离,非法字符的过滤和转义,这个需要武装到程序级别上,业内已经有很标准的方案了。
准入的标准就是拦截率超过 95%,准确率99.9%(需避免误拦截正确的请求)以上。 - 【必须】核心模块有标准的操作记录(如 操作模块、操作人员、操作时间、数据变动、说明),支持SQL安全审计。
2.3 备份与恢复能力设计
- 【必须】支持定时自动备份(编写备份脚本自动执行 或者 任务服务去定时执行)和手动备份
- 【必须】支持定期的全量备份 Week级别、Month级别 ,和定期 Day级别 的增量备份
- 【必须】有完整的灾备恢复操作文档 和 定期演练机制,保证 恢复速度10G/min ,数据完整性99.99%,恢复成功率:99.99%。
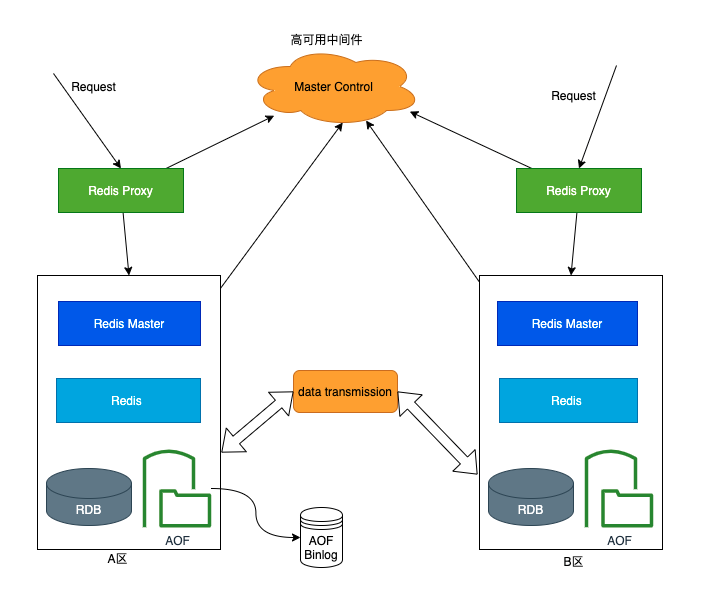
2.4 高可用架构-异地多活
异地多活
- 【建议】异地多活,多IDC,能保证非强同步(即异步同步),也就是说数据保持最终一致性,并非强一致性。
- 【建议】多主之间需保证支持至少 1W TPS传输峰值达到 10M/s。
- 【建议】机房具备容灾:建议多IDC部署,避免单个机房掉电、火灾、网络故障 导致整个系统不可用。
- 【建议】需保证单机房异交换机部署方式,具备一定的高可用能力。可以部署多个节点,部分节点挂掉后不影响业务;
数据节点支持多副本,单节点挂掉后,不影响业务,管理节点具备高可用性,支持多个节点部署。 - 【建议】异地机房如果只是用作备服,异步同步可以允许有些许数据延迟,延迟时间不应超过5分钟。
异地的数据中心 主 - 主 同步采用的是异步同步,如下图所示,是异步获取的,会因为延迟导致的数据暂时不一致性。
2.5 缓存击穿、缓存雪崩、缓存穿透预防设计
2.5.1 随机过期时间(参考1.3.4 第 4点做法)
2.5.2 大数据集合场景启用BloomFilter
参考这篇:布隆过滤器
2.5.3 短暂降级:空初始值
参考这篇:再聊缓存击穿,面试是一场博弈
2.5.4 计算服务层或数据服务层降级、限流
完整策略参考这篇:缓存的雪崩预防设计
3 流程上的约束
- 建立严格的代码评审机制和刷库评审机制。操作Redis的代码提交合并或者脚本提交刷库执行之前需要上级评审/交叉评审。
- 引入开源评审工具。增加扫描工具、脚本进行定期检查MySQL、Redis。
Redis系列24:Redis使用规范的更多相关文章
- Redis系列(二):Redis的数据类型及命令操作
原文链接(转载请注明出处):Redis系列(二):Redis的数据类型及命令操作 Redis 中常用命令 Redis 官方的文档是英文版的,当然网上也有大量的中文翻译版,例如:Redis 命令参考.这 ...
- Redis系列(一):Redis的简介与安装
原文链接(转载请注明出处):Redis系列(一):Redis的简介与安装 什么是 Redis Redis 是一个使用ANSI C 编写的开源.支持网络协议.基于内存.可选持久性的键值对数据库,它是一个 ...
- Redis系列一 Redis安装
Redis系列一 Redis安装 1.安装所使用的操作系统为Ubuntu16.04 Redis版本为3.2.9 软件一般下载存放目录为/opt,以下命令操作目录均为/opt root@ubunt ...
- Redis系列四 Redis常见配置
redis.conf常见配置 参数说明redis.conf 配置项说明如下:1. Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程 daemonize no2. ...
- redis系列:redis介绍与安装
前言 这个redis系列的文章将会记录博主学习redis的过程.基本上现在的互联网公司都会用到redis,所以学习这门技术于你于我都是有帮助的. 博主在写这个系列是用的是目前最新版本4.0.10,虚拟 ...
- 【Redis 系列】redis 学习十六,redis 字典(map) 及其核心编码结构
redis 是使用 C 语言编写的,但是 C 语言是没有字典这个数据结构的,因此 C 语言自己使用结构体来自定义一个字典结构 typedef struct redisDb src\server.h 中 ...
- 深入剖析Redis系列: Redis集群模式搭建与原理详解
前言 在 Redis 3.0 之前,使用 哨兵(sentinel)机制来监控各个节点之间的状态.Redis Cluster 是 Redis 的 分布式解决方案,在 3.0 版本正式推出,有效地解决了 ...
- Redis系列之----Redis的两种持久化机制(RDB和AOF)
Redis的两种持久化机制(RDB和AOF) 什么是持久化 Redis的数据是存储在内存中的,内存中的数据随着服务器的重启或者宕机便会不复存在,在生产环境,服务器宕机更是屡见不鲜,所以,我们希望 ...
- redis 系列24 哨兵Sentinel (中)
四. 检测下线状态 对于Redis的Sentinel中关于下线有两个不同的概念:(1)主观下线(Subjectively Down, 简称 Sdown) 指的是单个 Sentinel 实例对服务器做出 ...
- Redis系列(三)-Redis发布订阅及客户端编程
阅读目录 发布订阅模型 Redis中的发布订阅 客户端编程示例 0.3版本Hredis 发布订阅模型 在应用级其作用是为了减少依赖关系,通常也叫观察者模式.主要是把耦合点单独抽离出来作为第三方,隔离易 ...
随机推荐
- 9.3 Django框架
Django 是一个非常流行的 Python Web 开发框架,它是完整且强大的,适用于构建大型 Web 应用.在这一章节中,我们将详细介绍 Django 的基本概念.组件和用法.为了便于理解,我们将 ...
- go语言字符与字符串相关
ASCII ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁 字母的一套单字节编码系统 字符 本质上来 ...
- 使用 ProcessBuilder API 优化你的流程
ProcessBuilder 介绍 Java 的 Process API 为开发者提供了执行操作系统命令的强大功能,但是某些 API 方法可能让你有些疑惑,没关系,这篇文章将详细介绍如何使用 Proc ...
- 一次性掌握innodb引擎如何解决幻读和不可重复读
了解mysql的都知道,在mysql的RR(可重复)隔离级别下解决了幻读和不可重复.你知道RR下是怎么解决的吗,很多人会回答是通过MVCC和next-key解决的,具体是怎么解决的,今天来重点分析下. ...
- 手机号码吉利数PHP检测算法代码,超级实用
手机号码吉利数理预测解读:将手机号码末尾的四个数字,先除以八十,再减去整数部分,只使用剩下的小数(小数点反面的数字)乘以八十,然后将所得结果,对表查阅,就知道吉凶.(换句话说就是余数)例如:手机尾号是 ...
- RabbitMQ 多消费者 使用单信道和多信道区别
RabbitMQ 多个消费者共用一个信道实例 与 每个消费者使用不同的信道实例 区别: 1. 多个消费者共用一个信道实例:这种方式下,多个消费者共享同一个信道实例来进行消息的消费. 优点:这样可以减少 ...
- 从零配置Webpack项目
webpack.config.js基本配置 webpack.config.js是webpack的配置文件,在此文件中对项目入口,项目的输出,loader,插件以及环境等进行简单的配置 首先来对webp ...
- Codeforces Round #888 (Div. 3) A-G
比赛链接 A 代码 #include <bits/stdc++.h> using namespace std; using ll = long long; bool solve() { i ...
- Unity UGUI的PointerEventData的介绍及使用
Unity UGUI的PointerEventData的介绍及使用 1. 什么是PointerEventData? PointerEventData是Unity中UGUI系统中的一个重要组件,用于处理 ...
- WPF 中WebBrowser 控件的“允许阻止的内容”修复(引用本地的html页)
解决方法:(个人理解:导致原因就是iE安全机制的问题吧).在你的HTML里面第一行加: <!-- saved from url=(0014)about:internet -->具体原因可以 ...