python中不同方法的按索引读取数组的性能比较——哪种按索引读取数组的性能更好
写python代码这么多年,从来也没有想过不同方式的读取python数组会有什么太大的性能差距,不过这段时间写代码突然发现这个差别还挺大,于是就多研究了一下。
本文研究的是使用不同方式来对python数组进行按索引读取的性能差别。下面分别使用4种按索引读取数组的方法(不同方法中的数组都是相同形态的):
第一种,按索引读取一维的numpy数组;
第二种,按索引读取多维的numpy数组;
第三种,按索引读取一维的python列表;
具体代码:
import numpy as np
import time total = 16**6
data_0 = np.arange(0,16**6)
data_1 = data_0.reshape(16, 16, 16, 16, 16, 16)
data_2 = data_0.tolist()
data_3 = data_1.tolist() num = 3*(10**6)
indexes_list_0 = np.random.randint(total, size=(num,)).tolist()
indexes_list_1 = []
for _ in range(num):
indexes_list_1.append(np.random.randint(16, size=(6,)).tolist())
indexes_list_2 = indexes_list_0
indexes_list_3 = indexes_list_1 a_time = time.time()
for index in indexes_list_0:
ans = data_0[index]
b_time = time.time()
print(b_time-a_time) a_time = time.time()
for a,b,c,d,e,f in indexes_list_1:
ans = data_1[a,b,c,d,e,f]
b_time = time.time()
print(b_time-a_time) a_time = time.time()
for index in indexes_list_2:
ans = data_2[index]
b_time = time.time()
print(b_time-a_time) a_time = time.time()
for a,b,c,d,e,f in indexes_list_3:
ans = data_3[a][b][c][d][e][f]
b_time = time.time()
print(b_time-a_time)
运行性能:
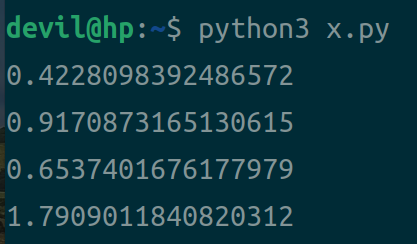
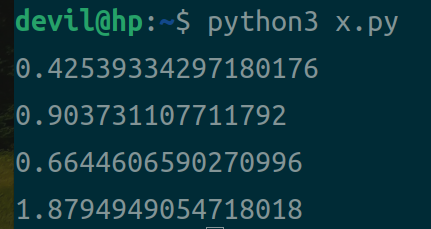
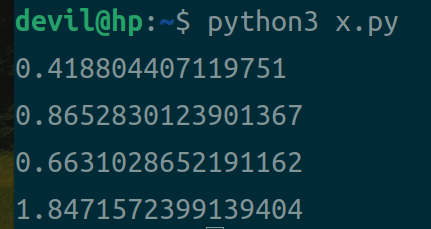
分析:
从上面可以看到:
1. 不论是对numpy数组还是list列表,使用一维索引的性能往往要高于多维索引的2倍以上性能;
2. 相同形式下使用索引方式读取数组,numpy数组的读取性能要由于list列表性能;
3. 性能排序,一维索引读取numpy数组性能 > 一维索引读取list性能 > 多维索引读取numpy数组性能 > 多维索引读取list性能。
=======================================
在上面的例子中,我们对一维数据的读取都是直接有索引号的,但是如果我们对一维数据索引时索引号和对多维数据读取时一样都是多维索引号,那么性能又该如何呢?
在对一维数组读取时使用多维索引号,将多维索引号转为一维索引后再对一维数组读取。
代码:
import numpy as np
import time total = 16**6
data_0 = np.arange(0,16**6)
data_1 = data_0.reshape(16, 16, 16, 16, 16, 16)
data_2 = data_0.tolist()
data_3 = data_1.tolist() num = 3*(10**6)
indexes_list_0 = np.random.randint(total, size=(num,)).tolist()
indexes_list_1 = []
for _ in range(num):
indexes_list_1.append(np.random.randint(16, size=(6,)).tolist())
indexes_list_2 = indexes_list_0
indexes_list_3 = indexes_list_1 a_time = time.time()
for a,b,c,d,e,f in indexes_list_1:
index = (16**5)*a+(16**4)*b+(16**3)*c+(16**2)*d+16*e+f
ans = data_0[index]
b_time = time.time()
print(b_time-a_time) a_time = time.time()
for a,b,c,d,e,f in indexes_list_1:
ans = data_1[a,b,c,d,e,f]
b_time = time.time()
print(b_time-a_time) a_time = time.time() for a,b,c,d,e,f in indexes_list_1:
index = (16**5)*a+(16**4)*b+(16**3)*c+(16**2)*d+16*e+f
ans = data_2[index]
b_time = time.time()
print(b_time-a_time) a_time = time.time()
for a,b,c,d,e,f in indexes_list_3:
ans = data_3[a][b][c][d][e][f]
b_time = time.time()
print(b_time-a_time)
运行性能:

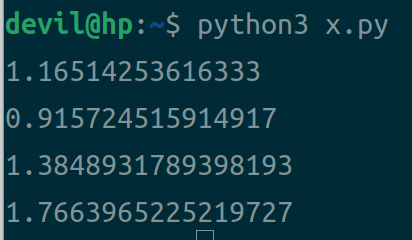
分析:
发现当对一维数组读取时,加入了将多维索引号转为一维索引号的操作后,运行性能急剧的下降。最后,我们可以发现,当加入索引号转换操作后,性能最高的读取方式为numpy的多维数组索引读取。
在很多运行情况中,我们往往都是直接获得多维索引号,而这个时候使用numpy的多维索引是性能最好的。
====================================================
python中不同方法的按索引读取数组的性能比较——哪种按索引读取数组的性能更好的更多相关文章
- C# 字符串拼接性能探索 c#中+、string.Concat、string.Format、StringBuilder.Append四种方式进行字符串拼接时的性能
本文通过ANTS Memory Profiler工具探索c#中+.string.Concat.string.Format.StringBuilder.Append四种方式进行字符串拼接时的性能. 本文 ...
- python中快速获取本地时区当天0点时间戳的一种方法
如下所示,看了网上的几种方法,这种方法算是代码量比较小的,同时可以保证求的是本地时区的0点时间戳,返回的是浮点数,需要的话自己转一下int In [1]: import time In [2]: fr ...
- Python学习笔记整理(四)Python中的字符串..
字符串是一个有序的字符集合,用于存储和表现基于文本的信息. 常见的字符串常量和表达式 T1=‘’ 空字符串 T2="diege's" 双引号 T3=""&quo ...
- 《python解释器源码剖析》第4章--python中的list对象
4.0 序 python中的list对象,底层对应的则是PyListObject.如果你熟悉C++,那么会很容易和C++中的list联系起来.但实际上,这个C++中的list大相径庭,反而和STL中的 ...
- python中的常用数据类型
python中的常用数据类型 以下是个人总结的python中常见的数据类型,话不多说,我们直接步入正题: 数字类型 整型类:int类可以表示任意大小的整数值,在python中没有像JAVA或者C那样的 ...
- python中的文件的读写
python中的 w+ 的使用方法:不能直接 write() 后,在进行读取,这样试读不到数据的,因为数据对象到达的地方为文件最后,读取是向后读的,因此,会读到空白,应该先把文件对象移到文件首位. f ...
- Python中通过open()操作文件时的文件中文名乱码问题
最近在用Python进行文件操作的时候,遇到创建中文文件名的乱码问题. Python默认是不支持中文的,一般我们在程序的开头加上#-*-coding:utf-8-*-来解决这个问题,但是在我用open ...
- python中栈的实现
栈是一种线性数据结构,用先进后出或者是后进先出的方式存储数据,栈中数据的插入删除操作都是在栈顶端进行,常见栈的函数操作包括 empty() – 返回栈是否为空 – Time Complexity : ...
- Python 中的枚举类型~转
Python 中的枚举类型 摘要: 枚举类型可以看作是一种标签或是一系列常量的集合,通常用于表示某些特定的有限集合,例如星期.月份.状态等. 枚举类型可以看作是一种标签或是一系列常量的集合,通常用于表 ...
- 【转】Python中的赋值、浅拷贝、深拷贝介绍
这篇文章主要介绍了Python中的赋值.浅拷贝.深拷贝介绍,Python中也分为简单赋值.浅拷贝.深拷贝这几种"拷贝"方式,需要的朋友可以参考下 和很多语言一样,Python中 ...
随机推荐
- JavaScript将类数组转换为数组的三种方法
// 类数组转换为数组 const list = [] // 假定为类数组 const arr1 = Array.from(list); const arr2 = Array.prototype.sp ...
- Linux设置时区
引言 在linux安装好了过后,如果时区不正确,需要手动地对它设置我们需要的时区 设置 控制台输入tzselect,回车 tzselect 2.然后选择 5 "Asia" 亚州,回 ...
- Thread.sleep 延时查询或延时查询前更新es缓存数据
Thread.sleep 延时查询或延时查询前更新es缓存数据 MQ消息的顺序性,或发送MQ的发送端未严格事务处理,可能存在数据未落库的情况,而导致接收端处理MQ消息的时候,查询为空. //demo1 ...
- MySQL查询关于区分字母大小写问题
前段时间在工作中测试提出了一个BUG,让我把根据ID查询区分大小写的功能去掉,大小写都随便查,然后我在SQL的位置加上了UPPER(id) = UPPER(#{id})的写法,而同事知道这个问题后的反 ...
- MySQL自定义函数(User Define Function)开发实例——发送TCP/UDP消息
开发背景 当数据库中某个字段的值改为特定值时,实时发送消息通知到其他系统. 实现思路 监控数据库中特定字段值的变化可以用数据库触发器实现.还需要实现一个自定义的函数,接收一个字符串参数,然后将这个字符 ...
- setsocket、getsocket 函数详解
背景 以前用到socket的时候会调用setsocket进行设置,现在整理有关的笔记的时候,重新查阅资料发现有点奇怪,发现大家比较少使用到这个. setsocket/getsocket #includ ...
- C#数据结构与算法入门教程,值得收藏学习!
前言 最近看到DotNetGuide技术社区交流群有不少小伙伴提问:想要系统化的学习数据结构和算法,不知道该怎么入门,有无好的教程推荐的?,今天大姚给大家推荐2个开源.免费的C#数据结构与算法入门教程 ...
- 【Python】基于动态规划和K聚类的彩色图片压缩算法
引言 当想要压缩一张彩色图像时,彩色图像通常由数百万个颜色值组成,每个颜色值都由红.绿.蓝三个分量组成.因此,如果我们直接对图像的每个像素进行编码,会导致非常大的数据量.为了减少数据量,我们可以尝试减 ...
- 【ClickHouse】6:clickhouse集群高可用
背景介绍: 有四台CentOS7服务器安装了ClickHouse HostName IP 安装程序 程序端口 shard(分片) replica(备份) centf8118.sharding1.db ...
- Mac Docker设置国内镜像加速器
安装docker 点我直达 设置国内加速镜像 { "experimental": false, "features": { "buildkit&quo ...