python中不同方法的按索引读取数组的性能比较——哪种按索引读取数组的性能更好
写python代码这么多年,从来也没有想过不同方式的读取python数组会有什么太大的性能差距,不过这段时间写代码突然发现这个差别还挺大,于是就多研究了一下。
本文研究的是使用不同方式来对python数组进行按索引读取的性能差别。下面分别使用4种按索引读取数组的方法(不同方法中的数组都是相同形态的):
第一种,按索引读取一维的numpy数组;
第二种,按索引读取多维的numpy数组;
第三种,按索引读取一维的python列表;
具体代码:
import numpy as np
import time total = 16**6
data_0 = np.arange(0,16**6)
data_1 = data_0.reshape(16, 16, 16, 16, 16, 16)
data_2 = data_0.tolist()
data_3 = data_1.tolist() num = 3*(10**6)
indexes_list_0 = np.random.randint(total, size=(num,)).tolist()
indexes_list_1 = []
for _ in range(num):
indexes_list_1.append(np.random.randint(16, size=(6,)).tolist())
indexes_list_2 = indexes_list_0
indexes_list_3 = indexes_list_1 a_time = time.time()
for index in indexes_list_0:
ans = data_0[index]
b_time = time.time()
print(b_time-a_time) a_time = time.time()
for a,b,c,d,e,f in indexes_list_1:
ans = data_1[a,b,c,d,e,f]
b_time = time.time()
print(b_time-a_time) a_time = time.time()
for index in indexes_list_2:
ans = data_2[index]
b_time = time.time()
print(b_time-a_time) a_time = time.time()
for a,b,c,d,e,f in indexes_list_3:
ans = data_3[a][b][c][d][e][f]
b_time = time.time()
print(b_time-a_time)
运行性能:
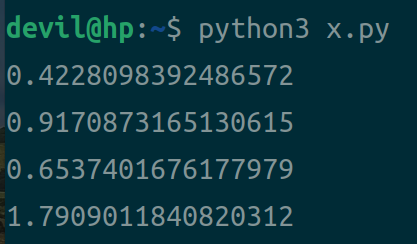
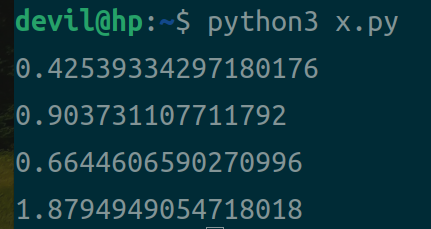
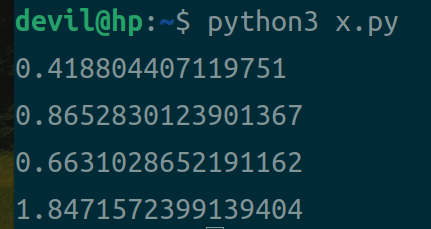
分析:
从上面可以看到:
1. 不论是对numpy数组还是list列表,使用一维索引的性能往往要高于多维索引的2倍以上性能;
2. 相同形式下使用索引方式读取数组,numpy数组的读取性能要由于list列表性能;
3. 性能排序,一维索引读取numpy数组性能 > 一维索引读取list性能 > 多维索引读取numpy数组性能 > 多维索引读取list性能。
=======================================
在上面的例子中,我们对一维数据的读取都是直接有索引号的,但是如果我们对一维数据索引时索引号和对多维数据读取时一样都是多维索引号,那么性能又该如何呢?
在对一维数组读取时使用多维索引号,将多维索引号转为一维索引后再对一维数组读取。
代码:
import numpy as np
import time total = 16**6
data_0 = np.arange(0,16**6)
data_1 = data_0.reshape(16, 16, 16, 16, 16, 16)
data_2 = data_0.tolist()
data_3 = data_1.tolist() num = 3*(10**6)
indexes_list_0 = np.random.randint(total, size=(num,)).tolist()
indexes_list_1 = []
for _ in range(num):
indexes_list_1.append(np.random.randint(16, size=(6,)).tolist())
indexes_list_2 = indexes_list_0
indexes_list_3 = indexes_list_1 a_time = time.time()
for a,b,c,d,e,f in indexes_list_1:
index = (16**5)*a+(16**4)*b+(16**3)*c+(16**2)*d+16*e+f
ans = data_0[index]
b_time = time.time()
print(b_time-a_time) a_time = time.time()
for a,b,c,d,e,f in indexes_list_1:
ans = data_1[a,b,c,d,e,f]
b_time = time.time()
print(b_time-a_time) a_time = time.time() for a,b,c,d,e,f in indexes_list_1:
index = (16**5)*a+(16**4)*b+(16**3)*c+(16**2)*d+16*e+f
ans = data_2[index]
b_time = time.time()
print(b_time-a_time) a_time = time.time()
for a,b,c,d,e,f in indexes_list_3:
ans = data_3[a][b][c][d][e][f]
b_time = time.time()
print(b_time-a_time)
运行性能:

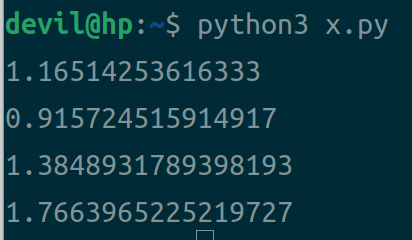
分析:
发现当对一维数组读取时,加入了将多维索引号转为一维索引号的操作后,运行性能急剧的下降。最后,我们可以发现,当加入索引号转换操作后,性能最高的读取方式为numpy的多维数组索引读取。
在很多运行情况中,我们往往都是直接获得多维索引号,而这个时候使用numpy的多维索引是性能最好的。
====================================================
python中不同方法的按索引读取数组的性能比较——哪种按索引读取数组的性能更好的更多相关文章
- C# 字符串拼接性能探索 c#中+、string.Concat、string.Format、StringBuilder.Append四种方式进行字符串拼接时的性能
本文通过ANTS Memory Profiler工具探索c#中+.string.Concat.string.Format.StringBuilder.Append四种方式进行字符串拼接时的性能. 本文 ...
- python中快速获取本地时区当天0点时间戳的一种方法
如下所示,看了网上的几种方法,这种方法算是代码量比较小的,同时可以保证求的是本地时区的0点时间戳,返回的是浮点数,需要的话自己转一下int In [1]: import time In [2]: fr ...
- Python学习笔记整理(四)Python中的字符串..
字符串是一个有序的字符集合,用于存储和表现基于文本的信息. 常见的字符串常量和表达式 T1=‘’ 空字符串 T2="diege's" 双引号 T3=""&quo ...
- 《python解释器源码剖析》第4章--python中的list对象
4.0 序 python中的list对象,底层对应的则是PyListObject.如果你熟悉C++,那么会很容易和C++中的list联系起来.但实际上,这个C++中的list大相径庭,反而和STL中的 ...
- python中的常用数据类型
python中的常用数据类型 以下是个人总结的python中常见的数据类型,话不多说,我们直接步入正题: 数字类型 整型类:int类可以表示任意大小的整数值,在python中没有像JAVA或者C那样的 ...
- python中的文件的读写
python中的 w+ 的使用方法:不能直接 write() 后,在进行读取,这样试读不到数据的,因为数据对象到达的地方为文件最后,读取是向后读的,因此,会读到空白,应该先把文件对象移到文件首位. f ...
- Python中通过open()操作文件时的文件中文名乱码问题
最近在用Python进行文件操作的时候,遇到创建中文文件名的乱码问题. Python默认是不支持中文的,一般我们在程序的开头加上#-*-coding:utf-8-*-来解决这个问题,但是在我用open ...
- python中栈的实现
栈是一种线性数据结构,用先进后出或者是后进先出的方式存储数据,栈中数据的插入删除操作都是在栈顶端进行,常见栈的函数操作包括 empty() – 返回栈是否为空 – Time Complexity : ...
- Python 中的枚举类型~转
Python 中的枚举类型 摘要: 枚举类型可以看作是一种标签或是一系列常量的集合,通常用于表示某些特定的有限集合,例如星期.月份.状态等. 枚举类型可以看作是一种标签或是一系列常量的集合,通常用于表 ...
- 【转】Python中的赋值、浅拷贝、深拷贝介绍
这篇文章主要介绍了Python中的赋值.浅拷贝.深拷贝介绍,Python中也分为简单赋值.浅拷贝.深拷贝这几种"拷贝"方式,需要的朋友可以参考下 和很多语言一样,Python中 ...
随机推荐
- mysql报错 a foreign key constraint fails(外键约束错误)
报错信息如下: (pymysql.err.IntegrityError) (1452, u'Cannot add or update a child row: a foreign key constr ...
- Asp.net Core 经过nginx代理后获取不到真实ip和scheme的问题
背景 我最近在一个Asp.net core Web 程序在经过nginx代理后 ,总是获取不到用户真实i和scheme(HttpContext.Request.Scheme),挠头: 我们一般从请求头 ...
- ecnuoj 5042 龟速飞行棋
5042. 龟速飞行棋 题目链接:5042. 龟速飞行棋 赛中没过,赛后补题时由于题解有些抽象,自己写个题解. 可以发现每次转移的结果只跟后面两个点的胜负状态有关. 不妨设 \(f_{u,a,b}\) ...
- 使用 GPU 进行 Lightmap 烘焙 - 简单 demo
作者:i_dovelemon 日期:2024-06-16 主题:Lightmap, PathTracer, Compute Shader 引言 一直以来,我都对离线 bake lightmap 操作很 ...
- spark内核架构深度剖析
- vulnhub - w1r3s.v1.0.1
vulnhub - w1r3s.v1.0.1 高质量视频教程 - b站红队笔记 靶机下载 本地环境 本机ip:192.168.157.131 w1r3s虚拟机设置NAT模式 信息收集 扫描网段得到攻击 ...
- Windows安装OnlyOfiice教程
1.OnlyOffice介绍 OnlyOffice 是一个在线创建.编辑和协作文档的服务. 2.Docker介绍 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移 ...
- VUE商城项目 - 项目优化上线 - 手稿
- js-内置函数-手稿
- yb课堂之用户登陆校验拦截器开发 《十一》
开发对应的登陆拦截器 开发loginInterceptor 登陆校验成功放行 登陆不成功返回json数据 LoginInterceptor.java package net.ybclass.onlin ...