PySpark 入门:通过JDBC连接数据库(DataFrame)
这里以关系数据库MySQL为例。首先,本博客教程(Ubuntu 20.04 安装MySQL 8.X),在Linux系统中安装好MySQL数据库。这里假设你已经成功安装了MySQL数据库。下面我们要新建一个测试Spark程序的数据库,数据库名称是“spark”,表的名称是“student”
请执行下面命令在Linux中启动MySQL数据库,并完成数据库和表的创建,以及样例数据的录入:
service mysql start
mysql -u root -p
# 屏幕会提示你输入密码
输入密码后,你就可以进入“mysql>”命令提示符状态,然后就可以输入下面的SQL语句完成数据库和表的创建:
mysql> create database spark;
mysql> use spark;
mysql> create table student (id int(4), name char(20), gender char(4), age int(4));
mysql> alter table student change id id int auto_increment primary key;
mysql> insert into student values(1,'Xueqian','F',23);
mysql> insert into student values(2,'Weiliang','M',24);
mysql> select * from student;
上面已经创建好了我们所需要的MySQL数据库和表,下面我们编写Spark应用程序连接MySQL数据库并且读写数据。
Spark支持通过JDBC方式连接到其他数据库获取数据生成DataFrame。
首先,请进入Linux系统(本教程统一使用hadoop用户名登录),打开火狐(FireFox)浏览器,下载一个MySQL的JDBC驱动(下载)。
JDBC 驱动下载方法一:
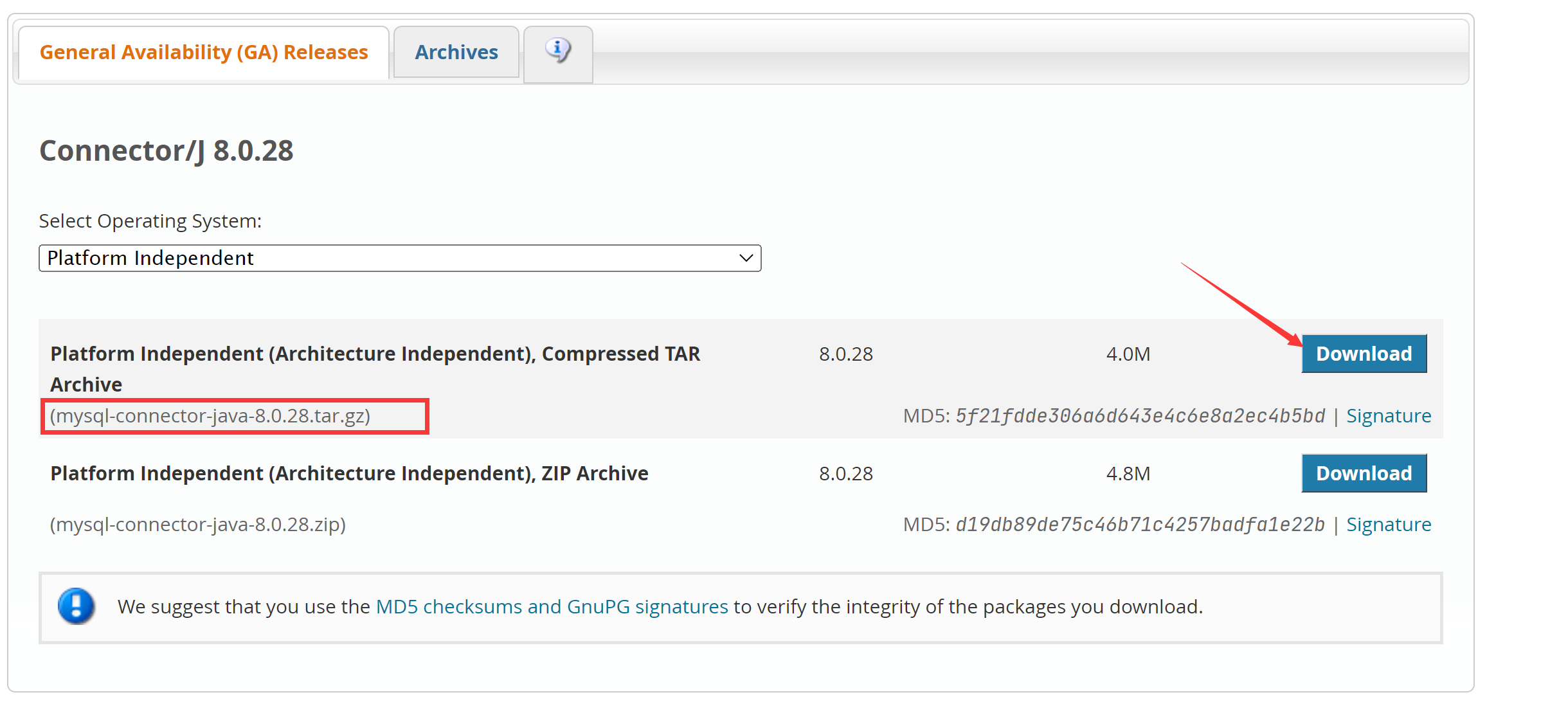
解压,把 mysql-connector-java-8.0.28.jar 粘贴到 /usr/local/spark/jars 中,这样便完成了驱动的导入
JDBC 驱动下载方法二:
在火狐浏览器中下载时,一般默认保存在hadoop用户的当前工作目录的“下载”目录下,所以,可以打开一个终端界面,输入下面命令查看:
cd ~
cd Downloads
就可以看到刚才下载到的MySQL的JDBC驱动程序,文件名称为 mysql-connector-java-8.0.28.tar.gz(你下载的版本可能和这个不同)。现在,使用下面命令,把该驱动程序拷贝到 Spark 的安装目录下:
sudo tar -zxf ~/Downloads/mysql-connector-java-8.0.28.tar.gz -C /usr/local/spark/jars
cd /usr/local/spark/jars
ls
这时就可以在/usr/local/spark/jars目录下看到这个驱动程序文件所在的文件夹 mysql-connector-java-8.0.28,进入这个文件夹,就可以看到驱动程序文件 mysql-connector-java-8.0.28.jar。
请输入下面命令启动已经安装在Linux系统中的mysql数据库(如果前面已经启动了MySQL数据库,这里就不用重复启动了)。
service mysql start
下面,我们要启动一个pyspark,而且启动的时候,要附加一些参数。启动pyspark时,必须指定mysql连接驱动jar包。
cd /usr/local/spark
./bin/pyspark \
--jars /usr/local/spark/jars/mysql-connector-java-8.0.28.jar
上面的命令行中,在一行的末尾加入斜杠\,是为了告诉spark-shell,命令还没有结束。
启动进入pyspark以后,可以执行以下命令连接数据库,读取数据,并显示:
jdbcDF = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/spark").option("driver","com.mysql.cj.jdbc.Driver").option("dbtable", "student").option("user", "root").option("password", "password").load()
下面我们再来看一下如何往MySQL中写入数据。
为了看到MySQL数据库在Spark程序执行前后发生的变化,我们先在Linux系统中新建一个终端,使用下面命令查看一下MySQL数据库中的数据库spark中的表student的内容:
mysql> use spark;
Database changed
mysql> select * from student;
//上面命令执行后返回下面结果
+------+----------+--------+------+
| id | name | gender | age |
+------+----------+--------+------+
| 1 | Xueqian | F | 23 |
| 2 | Weiliang | M | 24 |
+------+----------+--------+------+
现在我们开始在pyspark中编写程序,往spark.student表中插入两条记录。
下面,我们要启动一个pyspark,而且启动的时候,要附加一些参数。启动pyspark时,必须指定mysql连接驱动jar包(如果你前面已经采用下面方式启动了pyspark,就不需要重复启动了):
cd /usr/local/spark
./bin/pyspark \
--jars /usr/local/spark/jars/mysql-connector-java-8.0.28.jar
上面的命令行中,在一行的末尾加入斜杠\,是为了告诉spark-shell,命令还没有结束。
启动进入pyspark以后,可以执行以下命令连接数据库,写入数据,程序如下(你可以把下面程序一条条拷贝到pyspark中执行)
>>> from pyspark.sql.types import Row
>>> from pyspark.sql.types import StructType
>>> from pyspark.sql.types import StructField
>>> from pyspark.sql.types import StringType
>>> from pyspark.sql.types import IntegerType
>>> studentRDD = spark.sparkContext.parallelize(["3 Rongcheng M 26","4 Guanhua M 27"]).map(lambda line : line.split(" "))
//下面要设置模式信息
>>> schema = StructType([StructField("name", StringType(), True),StructField("gender", StringType(), True),StructField("age",IntegerType(), True)])
>>> rowRDD = studentRDD.map(lambda p : Row(p[1].strip(), p[2].strip(),int(p[3])))
//建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
>>> studentDF = spark.createDataFrame(rowRDD, schema)
>>> prop = {}
>>> prop['user'] = 'root'
>>> prop['password'] = 'password'
>>> prop['driver'] = "com.mysql.cj.jdbc.Driver"
>>> studentDF.write.jdbc("jdbc:mysql://localhost:3306/spark",'student','append', prop)
在pyspark中执行完上述程序后,我们可以看一下效果,看看MySQL数据库中的spark.student表发生了什么变化。请在刚才的另外一个窗口的MySQL命令提示符下面继续输入下面命令:
mysql> select * from student;
+------+-----------+--------+------+
| id | name | gender | age |
+------+-----------+--------+------+
| 1 | Xueqian | F | 23 |
| 2 | Weiliang | M | 24 |
| 3 | Rongcheng | M | 26 |
| 4 | Guanhua | M | 27 |
+------+-----------+--------+------+
4 rows in set (0.00 sec)
PySpark 入门:通过JDBC连接数据库(DataFrame)的更多相关文章
- JDBC连接数据库经验技巧(转)
Java数据库连接(JDBC)由一组用 Java 编程语言编写的类和接口组成.JDBC 为工具/数据库开发人员提供了一个标准的 API,使他们能够用纯Java API 来编写数据库应用程序.然而各个开 ...
- JDBC连接数据库
JDBC连接数据库 1.加载JDBC驱动程序. Class.forName("com.mysql.jdbc.Driver"); 建立连接,. Connection conn = D ...
- java开发中JDBC连接数据库代码和步骤
JDBC连接数据库 •创建一个以JDBC连接数据库的程序,包含7个步骤: 1.加载JDBC驱动程序: 在连接数据库之前,首先要加载想要连接的数据库的驱动到JVM(Java虚拟机), 这通过java.l ...
- java开发JDBC连接数据库详解
JDBC连接数据库 好文一定要让大家看见 •创建一个以JDBC连接数据库的程序,包含7个步骤: 1.加载JDBC驱动程序: 在连接数据库之前,首先要加载想要连接的数据库的驱动到JVM(Java虚拟机) ...
- 【转】Java开发中JDBC连接数据库代码和步骤总结
(转自:http://www.cnblogs.com/hongten/archive/2011/03/29/1998311.html) JDBC连接数据库 创建一个以JDBC连接数据库的程序,包含7个 ...
- 使用配置文件来配置JDBC连接数据库
1.管理数据库连接的Class 代码如下: package jdbcTest;import java.sql.Connection;import java.sql.DriverManager;impo ...
- Java中JDBC连接数据库代码和步骤详解总结
JDBC连接数据库 •创建一个以JDBC连接数据库的程序,包含7个步骤: 1.加载JDBC驱动程序: 在连接数据库之前,首先要加载想要连接的数据库的驱动到JVM(Jav ...
- 完整java开发中JDBC连接数据库代码和步骤
JDBC连接数据库 •创建一个以JDBC连接数据库的程序,包含7个步骤: 1.加载JDBC驱动程序: 在连接数据库之前,首先要加载想要连接的数据库的驱动到JVM(Java虚拟机), 这通过java.l ...
- JDBC连接数据库(PreparedStatement)
PreparedStatement是在数据库端防止SQL注入漏洞的SQL方法这里演示了一些基本使用方法同样使用Oracle数据库,之前已经手动建立了一张t_account表数据库代码参见上一篇< ...
- JDBC连接数据库演示
今天重新学习了JDBC连接数据库,使用的数据库是Oracle,在运行前已经手动建立了一张t_user表,建表信息如下: create table t_user( card_id ) primary k ...
随机推荐
- 通用串口modbus转PROFIBUS DP网关PM-160在汽车行业的应用案例
通用串口modbus转PROFIBUS DP网关PM-160在汽车行业的应用案例 摘要: PM-160 是泗博公司生产的,可以实现串口与 PROFIBUS DP 协议数据通信的网关.此案例讲述的是通过 ...
- 使用reposync工具将yum安装包保存到本地的方法
使用reposync工具将yum安装包保存到本地的方法 版权声明:原创作品,谢绝转载!否则将追究法律责任. ----- 作者:kirin Anolis7/centos7 1.reposync 1.1. ...
- Centos离线安装JDK+Tomcat+MySQL8.0+Nginx
一.安装JDK 注:以下命令环境在Xshell中进行. 1.查询出系统自带的OpenJDK及版本 rpm -qa | grep jdk 2.如果显示已安装openjdk则对其进行卸载. #卸载 rpm ...
- 【GKCTF 2020】ez三剑客
[GKCTF 2020]ez三剑客 收获 gopher协议SSRF 多利用github搜索已存在的函数漏洞 CMS审计的一些方法 1. ezweb 打开题目给了一个输入框,能够向输入的url发送htt ...
- [编程] AI助力软件项目正向生成,注释编写的革命
引言 软件项目质量直接影响着用户体验和企业效益.随着软件的应用范围不断扩大,提高软件质量的重要性也日益凸显.传统上,软件工程师通常采用自下而上的开发模式,自行设计实现代码并进行测试,这给质量把控带来一 ...
- CoreFlex框架发布 `0.1.1`
CoreFlex框架发布 0.1.1 框架描述 CoreFlex是一个支持.NET 6,.NET 7,.NET 8的快速开发框架,也提供MasaFramework相关框架的集成提供更多功能模块, 集成 ...
- [ABC317G] Rearranging
Problem Statement There is a grid with $N$ rows and $M$ columns. The square at the $i$-th row from t ...
- Scrapy-settings.py常规配置
# Scrapy settings for scrapy_demo project # # For simplicity, this file contains only settings consi ...
- Windows 监控配置
1:Windows2003服务器 2:Windows Sever 2008安装snmp 3:Windows Sever 2012安装snmp 4:Windows 10安装snmp 服务配置 双击打开[ ...
- 神经网络优化篇:理解mini-batch梯度下降法(Understanding mini-batch gradient descent)
理解mini-batch梯度下降法 使用batch梯度下降法时,每次迭代都需要历遍整个训练集,可以预期每次迭代成本都会下降,所以如果成本函数\(J\)是迭代次数的一个函数,它应该会随着每次迭代而减少, ...