【五】强化学习之Sarsa、Qlearing详细讲解----PaddlePaddlle【PARL】框架{飞桨}
相关文章:
【一】飞桨paddle【GPU、CPU】安装以及环境配置+python入门教学
代码链接:码云:https://gitee.com/dingding962285595/parl_work ;github:https://github.com/PaddlePaddle/PARL
1.TD更新:
 会找到能获取reward最大的路径。
会找到能获取reward最大的路径。
对应数学公式:

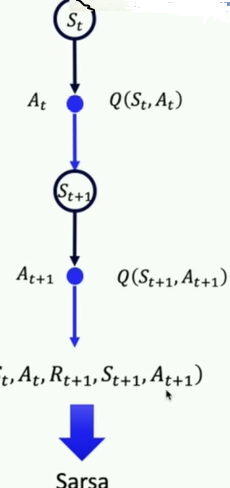
对应流程:

下一步Q值更新当前Q值。
软更新方式,设置权重a每次更新一点点,类似学习率。这样最后Q值都会逼近目标值。

2.Sarsa

部分代码:
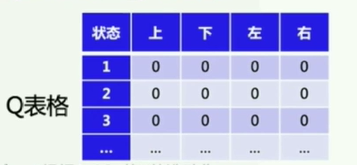
建立的Q表格
初始化Q表格:四列n行
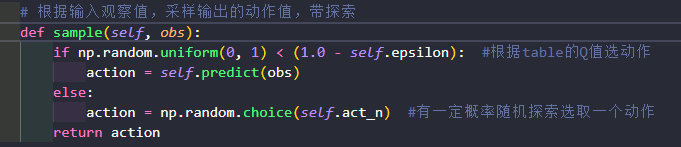
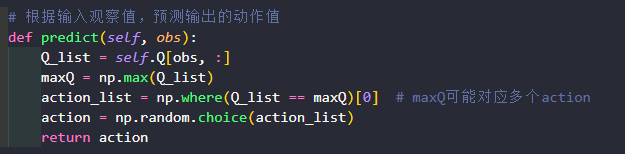
Agent是和环境environment交互的主体。predict()方法:输入观察值observation(或者说状态state),输出动作值sample()方法:再predict()方法基础上使用ε-greedy增加探索learn()方法:输入训练数据,完成一轮Q表格的更新
提取出状态s的这一行,然后得到最大Q值的下标。
当对应Q值存在多个动作时,避免每次都获取第一个动作,np.where从最大q值里随机挑选一个动作。
对应代码最后两行
如果 done 为true 则为episode最后一个状态,下一个时刻就没有状态了;
run_episode():agent在一个episode中训练的过程,使用agent.sample()与环境交互,使用agent.learn()训练Q表格。test_episode():agent在一个episode中测试效果,评估目前的agent能在一个episode中拿到多少总reward。
测试一下算法效果
跑一个episode 只取动作最优的,每个step都延迟了0.5s,动态图显示会稍微慢点的。
得到的结果发现在到达终点过程中距离悬崖远远的,因为程序中有个探索的过程,如果离得太近,下一步会掉下悬崖,重新开始拿到reward-100
reward计算







3.Qlearning
Q-learning也是采用Q表格的方式存储Q值(状态动作价值),决策部分与Sarsa是一样的,采用ε-greedy方式增加探索。Q-learning跟Sarsa不一样的地方是更新Q表格的方式。
Sarsa是on-policy的更新方式,先做出动作再更新。Q-learning是off-policy的更新方式,更新learn()时无需获取下一步实际做出的动作next_action,并假设下一步动作是取最大Q值的动作。Q-learning的更新公式为:
两者区别在于target不同,Qlearing默认下下一个动作为最优的策略,不受探索的影响。
除了learn其余代码都一样
效果比sarsa好






4.策略结果比较:

【五】强化学习之Sarsa、Qlearing详细讲解----PaddlePaddlle【PARL】框架{飞桨}的更多相关文章
- node+vue进阶【课程学习系统项目实战详细讲解】打通前后端全栈开发(1):创建项目,完成登录功能
第一章 建议学习时间8小时·分两次学习 总项目预计10章 学习方式:详细阅读,并手动实现相关代码(如果没有node和vue基础,请学习前面的vue和node基础博客[共10章]) 视频教程地 ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
- 打通前后端全栈开发node+vue进阶【课程学习系统项目实战详细讲解】(3):用户添加/修改/删除 vue表格组件 vue分页组件
第三章 建议学习时间8小时 总项目预计10章 学习方式:详细阅读,并手动实现相关代码(如果没有node和vue基础,请学习前面的vue和node基础博客[共10章] 演示地址:后台:demo ...
- 分布式缓存技术redis学习(二)——详细讲解redis数据结构(内存模型)以及常用命令
Redis数据类型 与Memcached仅支持简单的key-value结构的数据记录不同,Redis支持的数据类型要丰富得多,常用的数据类型主要有五种:String.List.Hash.Set和Sor ...
- 强化学习之Sarsa (时间差分学习)
上篇文章讲到Q-learning, Sarsa与Q-learning的在决策上是完全相同的,不同之处在于学习的方式上 这次我们用openai gym的Taxi来做演示 Taxi是一个出租车的游戏,把顾 ...
- 李宏毅强化学习完整笔记!开源项目《LeeDeepRL-Notes》发布
Datawhale开源 核心贡献者:王琦.杨逸远.江季 提起李宏毅老师,熟悉强化学习的读者朋友一定不会陌生.很多人选择的强化学习入门学习材料都是李宏毅老师的台大公开课视频. 现在,强化学习爱好者有更完 ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- 详解 Facebook 田渊栋 NIPS2017 论文:深度强化学习研究的 ELF 平台
这周,机器学习顶级会议 NIPS 2017 的论文评审结果已经通知到各位论文作者了,许多作者都马上发 Facebook/Twitter/Blog/ 朋友圈分享了论文被收录的喜讯.大家的熟人 Faceb ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- 谷歌推出新型强化学习框架Dopamine
今日,谷歌发布博客介绍其最新推出的强化学习新框架 Dopamine,该框架基于 TensorFlow,可提供灵活性.稳定性.复现性,以及快速的基准测试. GitHub repo:https://git ...
随机推荐
- 视频云AI时代,穿越市场第一,想象更多
国际权威数据公司IDC发布<中国视频云市场跟踪(2023 H1)>报告:自2018年至今,阿里云持续保持中国视频云整体市场第一,整体市场占比达24.4%. 01 第一之外,低谷之上 近期, ...
- CJ88 DUMP The ASSERT condition was violated
一.CJ88运行某个项目时DUMP,其他项目正常 The ASSERT condition was violated. 源代码位置为交易货币为空导致DUMP 经过长时间的源码调试,也只定位在查询语句这 ...
- 题解 CF1550C. Manhattan Subarrays (思维)
来源:Educational Codeforces Round 111 (Rated for Div. 2) 不难但很好的思维题 设 \(d(p,q)\) 为 \(p,q\) 两点之间的曼哈顿距离 给 ...
- Codeforces Round #719 (Div. 3) A~E题解
51鸽了几天,有几场比赛的题解还没发布,今天晚上会补上的 1520A. Do Not Be Distracted! 问题分析 模拟,如果存在已经出现的连续字母段则输出NO using ll = lon ...
- 七、java操作swift对象存储(动态大对象)
系列导航 一.swift对象存储环境搭建 二.swift添加存储策略 三.swift大对象--动态大对象 四.swift大对象--静态态大对象 五.java操作swift对象存储(官网样例) 六.ja ...
- kubernetes 资源管理概述
本文转载自 Cizixs 的博客 kubernetes 资源管理概述 kubernetes 资源简介 什么是资源? 在 kubernetes 中,有两个基础但是非常重要的概念:node 和 pod.n ...
- 260. 只出现一次的数字 III
1.题目介绍 2.题解 2.1 快排+遍历 思路 同本系列前几题一样 代码 class Solution { public: std::vector<int> singleNumber(s ...
- 【ArgParse】一个开源的入参解析库
项目地址:argtable3 本地验证: 编译构建 新增验证 // examples/skull.c #include "argtable3.h" int main(int arg ...
- C# 线程本地存储 为什么线程间值不一样
一:背景 1. 讲故事 有朋友在微信里面问我,为什么用 ThreadStatic 标记的字段,只有第一个线程拿到了初始值,其他线程都是默认值,让我能不能帮他解答一下,尼玛,我也不是神仙什么都懂,既然问 ...
- 通过宿主机查看K8S或者是容器内的Java程序的简单方法
通过宿主机查看K8S或者是容器内的Java程序的简单方法 背景 最近一个项目的环境出现了 cannot create native process 的错误提示 出现这个错误提示时, docker ex ...