GPT大语言模型引爆强化学习与语言生成模型的热潮、带你了解RLHF。
GPT大语言模型引爆强化学习与语言生成模型的热潮、带你了解RLHF。

随着 ChatGPT 的爆火,强化学习(Reinforcement Learning)和语言生成模型(Language Model)的结合开始变得越来越受人关注。
有关 ChatGPT 的视频讲解可以参考这里。
该项目的详细介绍可以参考这里。

在这个项目中,我们将通过开源项目 trl 搭建一个通过强化学习算法(PPO)来更新语言模型(GPT-2)的几个示例,包括:
基于中文情感识别模型的正向评论生成机器人(No Human Reward)
基于人工打分的正向评论生成机器人(With Human Reward)
基于排序序列(Rank List)训练一个奖励模型(Reward Model)
排序序列(Rank List)标注平台
1. 基于中文情感识别模型的正向评论生成机器人(No Human Reward)
考虑现在我们有一个现成的语言模型(示例中选用中文的GPT2),通过一小段 prompt,模型能够继续生成一段文字,例如:
prompt: 刚收到货,感觉有
output 1: 刚收到货,感觉有 点 不 符 合 预 期 ,不 好
output 2: 刚收到货,感觉有 挺 无 奈 的 送 货 速 度 不 太 行
...
我们现在希望语言模型能够学会生成「正向情感」的好评,而当前的 GPT 模型是不具备「情绪识别」能力的,如上面两个生成结果都不符合正面情绪。
为此,我们期望通过「强化学习」的方法来进化现有 GPT 模型,使其能够学会尽可能的生成「正面情感」的评论。
在强化学习中,当模型生成一个结果时,我们需要告知模型这个结果的得分(reward)是多少,即我们为模型的每一个生成结果打分,例如:
output 1: 刚收到货,感觉有 点 不 符 合 预 期 ,不 好 -> 0.2 分
output 2: 刚收到货,感觉有 挺 无 奈 的 送 货 速 度 不 太 行 -> 0.1 分
output 3: 刚收到货,感觉有 些 惊 喜 于 货 物 质 量 -> 0.9 分
...
如果依靠人工为每一个输出打分,这将是一个非常漫长的过程(在另一个示例中我们将实现该功能)。
因此,我们引入另一个「情绪识别模型」来模拟人工给出的分数。
「情绪识别模型」我们选用 transformers 中内置的 sentiment-analysis pipeline 来实现。
该模型基于网络评论数据集训练,能够对句子进行「正向、负向」的情绪判别,如下所示:
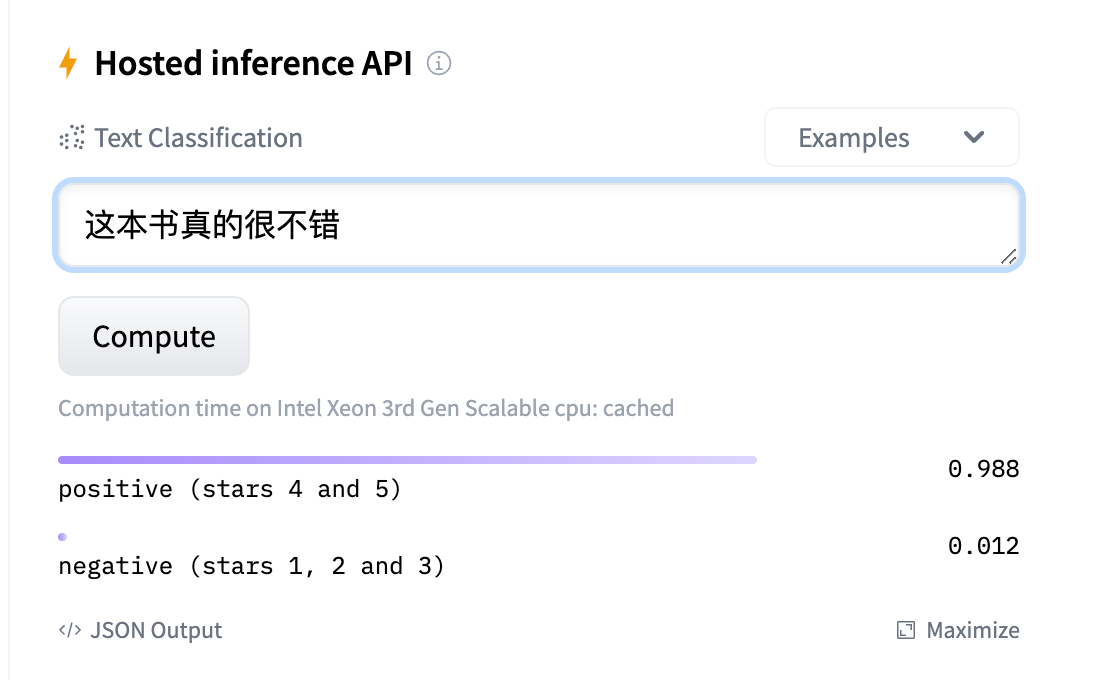
我们利用该「情感识别模型」的判别结果(0.0~1.0)作为 GPT 生成模型的 reward,以指导 GPT 模型通过强化学习(PPO)算法进行迭代更新。
1.1 训练流程
整个 PPO + GPT2 的训练流程如下所示:
随机选择一个
prompt,如:"这部电影很"GPT 模型根据
prompt生成答案,如:"这部电影很 好 看 哦 ~ "将 GPT 的生成答案喂给「情绪识别」模型,并得到评分(reward),如:0.9
利用评分(reward)对 GPT 模型进行优化。
重复该循环,直到训练结束为止。
1.2 开始训练
本项目基于 pytorch + transformers 实现,运行前请安装相关依赖包:
pip install -r ../requirements.txt
运行训练脚本:
python ppo_sentiment_example.py
正常启动训练后,终端会打印如下数据:
...
epoch 0 mean-reward: 0.7271811366081238
Random Sample 5 text(s) of model output:
1. 刚收到货,感觉不 错 , 会 冒 充 收 银 员 在 果 盘 盘 底 , 就
2. 说实话,真的很般 般 , 一 般 都 是 饭 点 去 , 没 办 法 我 现
3. 说实话,真的很怪 不 得 刚 开 的 没 多 久 , 现 在 上 海 这 个
4. 这部电影很啊 , 所 以 , 也 算 一 个 抛 砖 引 玉 。 昨 天
5. 这次购物总的来说体验很[SEP] ~ 满 意 谢 谢 送 货 很 快 [SEP] 为 什 么 输 出
1%|▋ | 1/157 [00:55<2:23:53, 55.34s/it]
epoch 1 mean-reward: 0.7439988851547241
Random Sample 5 text(s) of model output:
1. 这次购物总的来说体验很我 不 知 道 表 盘 这 是 男 人 的? 听 说 女 人
2. 这部电影很金 士 顿 鉴 定 和 暗 暗 [SEP] 正 品 。 是 正 品 这
3. 刚收到货,感觉是 有 些 人 吃 不 尽 的 名 字 ! ~ 世 界 几 大
4. 说实话,真的很对 不 起 这 个 价 钱 , 可 能 是 因 为 做 出 来
5. 说实话,真的很非 电 。 31. 可 说 是 食 堂 , 没 怎 么 规 划
1%|█▎ | 2/157 [01:51<2:24:31, 55.95s/it]
epoch 2 mean-reward: 0.8219242691993713
...
其中 mean-reward 代表该 epoch 下模型的平均得分(来自「情绪识别模型」的反馈),Random Sample 代表该模型在当前 epoch 生成的句子样例。
在 logs/PPO-Sentiment-Zh.png 下会保存模型训练过程中的各个指标变化(包括 reward 变化曲线):
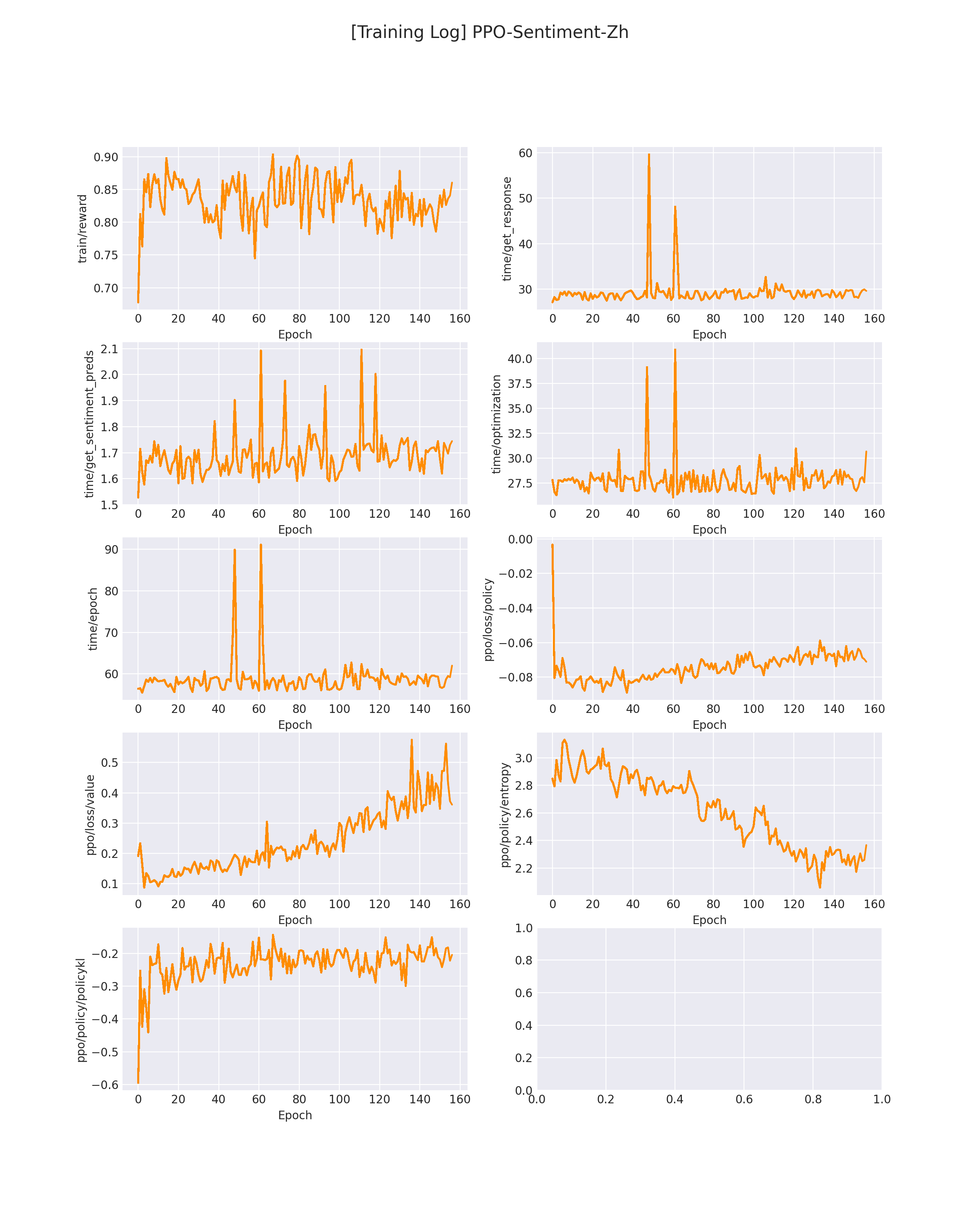
在模型刚开始训练的时候,GPT 会生成一些比较随机的答案,此时的平均 reward 也不会很高,会生成一些「负面」情绪的评论(如下所示):

随着训练,GPT 会慢慢学会偏向「正面」的情绪评论(如下所示):

2. 基于人工打分的评论生成机器人(With Human Reward)
在第一个示例中,模型的 reward 来自于另一个模型。
在该示例中,我们将制作一个平台来支持人工进行打分。
我们启动标注平台:
python terminal_main.py
随后我们可以在终端看到模型的生成结果,通过人工输入 reward 以迭代模型:
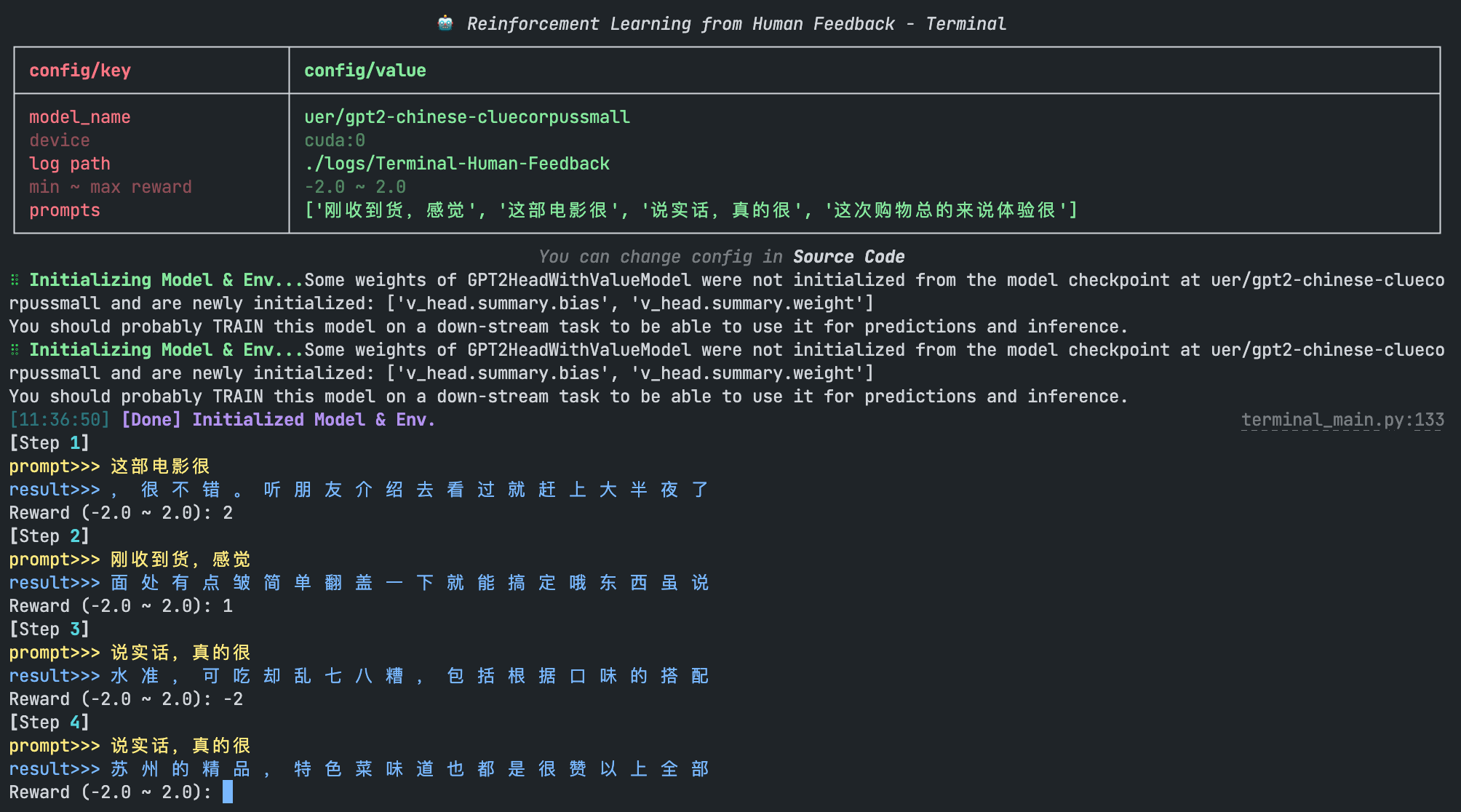
3. 基于人工排序训练 Reward Model
通过排序序列训练打分模型。
训练数据集在 data/reward_datasets/sentiment_analysis,每一行是一个排序序列(用\t符号隔开)。
排在越前面的越偏「正向情绪」,排在越后面越「负向情绪」。
1.买过很多箱这个苹果了,一如既往的好,汁多味甜~ 2.名不副实。 3.拿过来居然屏幕有划痕,顿时就不开心了 4.什么手机啊!一台充电很慢,信号不好!退了!又买一台竟然是次品。
1.一直用沙宣的洗发露!是正品!去屑止痒润发护发面面俱到! 2.觉得比外买的稀,好似加了水的 3.非常非常不满意,垃圾。 4.什么垃圾衣服,买来一星期不到口袋全拖线,最差的一次购物
...
开启训练脚本:
sh train_reward_model.sh
成功开始训练后,终端会打印以下信息:
...
global step 10, epoch: 1, loss: -0.51766, speed: 0.21 step/s
global step 20, epoch: 1, loss: -0.55865, speed: 0.22 step/s
global step 30, epoch: 1, loss: -0.60930, speed: 0.21 step/s
global step 40, epoch: 1, loss: -0.65024, speed: 0.21 step/s
global step 50, epoch: 1, loss: -0.67781, speed: 0.22 step/s
Evaluation acc: 0.50000
best F1 performence has been updated: 0.00000 --> 0.50000
global step 60, epoch: 1, loss: -0.69296, speed: 0.20 step/s
global step 70, epoch: 1, loss: -0.70710, speed: 0.20 step/s
...
在 logs/reward_model/sentiment_analysis/ERNIE Reward Model.png 会存放训练曲线图:
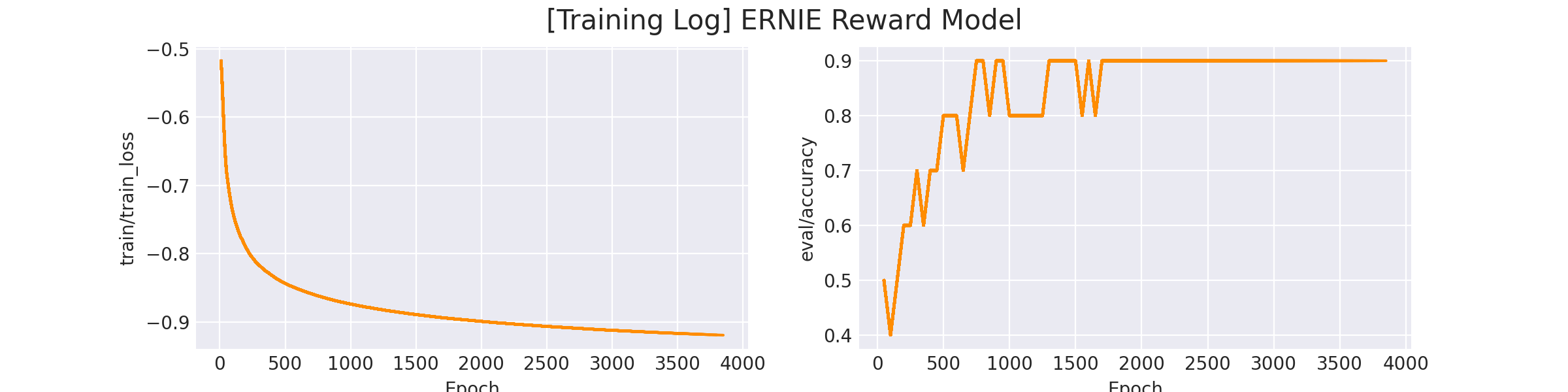
完成训练后,我们运行预测脚本,可以看到训练后的模型的打分效果:
python inference_reward_model.py
我们输入两句评论句子:
texts = [
'买过很多箱这个苹果了,一如既往的好,汁多味甜~',
'一台充电很慢,信号不好!退了!又买一台竟然是次品。。服了。。'
]
>>> tensor([[10.6989], [-9.2695]], grad_fn=<AddmmBackward>)
可以看到「正向评论」得到了 10.6 分,而「负向评论」得到了 -9.26 分。
4. 人工排序(RankList)标注平台
对于第三步 Reward Model 训练,若想自定义的排序数据集,可以使用该项目中提供的标注工具:
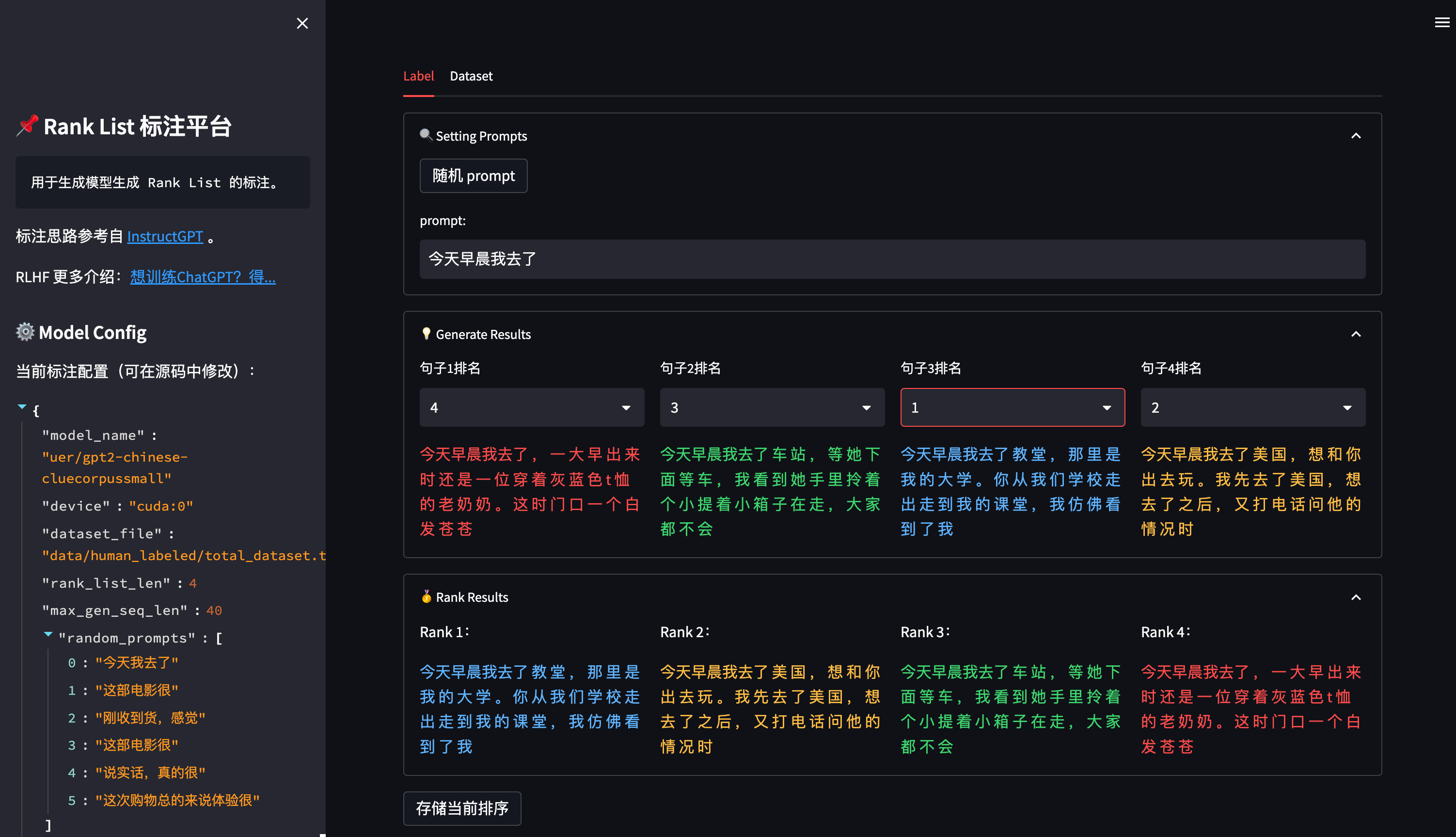
平台使用 streamlit 搭建,因此使用前需要先安装三方包:
pip install streamlit==1.17.0
随后,运行以下命令开启标注平台:
sh start_ranklist_labler.sh
在浏览器中访问 ip + 端口(默认8904, 可在 sh start_ranklist_labler.sh 中修改端口号)即可打开标注平台。
点击 随机 prompt 按钮可以从 prompt池 中随机选择一个 prompt(prompt池可以在 ranklist_labeler.py 中修改 MODEL_CONFIG['random_prompts'])。
通过对模型生成的 4 个答案进行排序,得到从高分到低分的排序序列,点击底部的 存储当前排序 按钮将当前排序存入本地数据集中。
数据集将存储在 data/human_labeled/total_dataset.tsv 中(可在 ranklist_labeler.py 中修改 MODEL_CONFIG['dataset_file'] 参数),每一行是一个 rank_list,用 \t 分割:
今天早晨我去了 一 趟 酒 店 , 在 check in 的 时 候 我 也 在 , 但 是 那 位 前 任 不 让 我 进 去 , 直 接 说 了 一 句 今天早晨我去了 中 介 的 办 公 楼 , 看 了 我 的 婚 纱 照 , 拍 的 时 候 已 经 是 晚 上 十 一 点 有 点 累 了 , 我 今天早晨我去了 天 津 , 因 为 天 气 真 是 糟 糕 , 天 都 是 蓝 色 的 , 但 我 在 一 个 山 坡 上 , 因 为 时 间 短 今天早晨我去了 你 们 工 作 室 , 一 片 混 乱 , 有 什 么 问 题 都 没 有 , 还 有 一 些 工 作 人 员 乱 来 乱 走 ,
...
也可以点击标注页面上方的 Dataset 按钮,可以查看当前已存储的数据集:
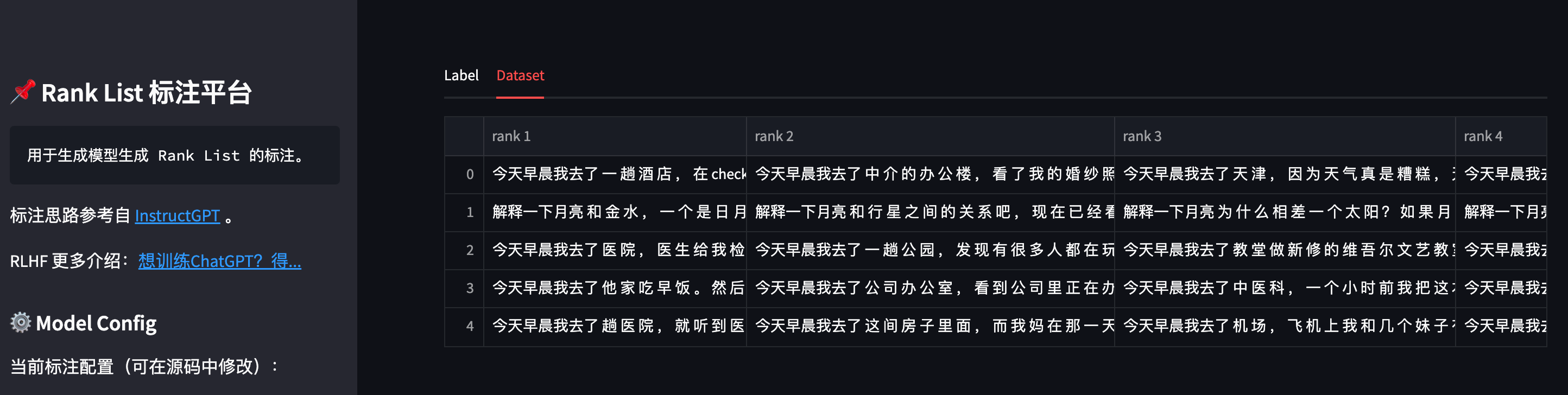
数据标注完成后,即可参照第三步训练一个自定义的 Reward Model。
参考链接:
https://mp.weixin.qq.com/s/1v4Uuc1YAZ9MRr1UWMH9xw
https://zhuanlan.zhihu.com/p/595579042
https://zhuanlan.zhihu.com/p/606328992
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。


GPT大语言模型引爆强化学习与语言生成模型的热潮、带你了解RLHF。的更多相关文章
- 强化学习之 免模型学习(model-free based learning)
强化学习之 免模型学习(model-free based learning) ------ 蒙特卡罗强化学习 与 时序查分学习 ------ 部分节选自周志华老师的教材<机器学习> 由于现 ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- 强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)
在强化学习(十七) 基于模型的强化学习与Dyna算法框架中,我们讨论基于模型的强化学习方法的基本思路,以及集合基于模型与不基于模型的强化学习框架Dyna.本文我们讨论另一种非常流行的集合基于模型与不基 ...
- EMNLP 2018 | 用强化学习做神经机器翻译:中山大学&MSRA填补多项空白
人工深度学习和神经网络已经为机器翻译带来了突破性的进展,强化学习也已经在游戏等领域取得了里程碑突破.中山大学数据科学与计算机学院和微软研究院的一项研究探索了强化学习在神经机器翻译领域的应用,相关论文已 ...
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
- 深度强化学习day01初探强化学习
深度强化学习 基本概念 强化学习 强化学习(Reinforcement Learning)是机器学习的一个重要的分支,主要用来解决连续决策的问题.强化学习可以在复杂的.不确定的环境中学习如何实现我们设 ...
- 【资料总结】| Deep Reinforcement Learning 深度强化学习
在机器学习中,我们经常会分类为有监督学习和无监督学习,但是尝尝会忽略一个重要的分支,强化学习.有监督学习和无监督学习非常好去区分,学习的目标,有无标签等都是区分标准.如果说监督学习的目标是预测,那么强 ...
- 深度强化学习资料(视频+PPT+PDF下载)
https://blog.csdn.net/Mbx8X9u/article/details/80780459 课程主页:http://rll.berkeley.edu/deeprlcourse/ 所有 ...
- (待续)【转载】 DeepMind发Nature子刊:通过元强化学习重新理解多巴胺
原文地址: http://www.dataguru.cn/article-13548-1.html -------------------------------------------------- ...
随机推荐
- C++11实用特性2
1 可调用对象包装器.绑定器 1可调用对象 C++中的可调用对象分为四类: 函数指针: 任何一个函数都可以抽象成一个函数指针 int print(int a, double b) { cout < ...
- Linux 下 Docker 操作遭到守护程序套接字时访问权限被拒绝
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker. ...
- #2102:A计划(DFS和BFS剪枝搜索)
题意: 有几个比较坑的地方总结一下, 很容易误解: 遇到#就必须走 #不消耗时间 #对面如果也是#也不能走, 要不然无限循环了 最短路径剪枝时, 发现不能走的#是要把两步都标注为-1并跳出 题解: 一 ...
- HDU--1166--单点更新
敌兵布阵 HDU - 1166 多组输入,注意清除tr数组 维护一个前缀数组,耗时有点大 #include <cstdio> #include <cstring> using ...
- Educational Codeforces Round 108 (Rated for Div. 2) (A思维,Bmath,C前缀和,D枚举)
1519A. Red and Blue Beans 问题简述 给定 \(r\) 个红豆,\(b\) 个蓝豆,差值 \(d\) ,要求我们进行为红蓝豆分组,使得红豆和蓝豆绝对值差值不大于 \(d\) , ...
- freeswitch配置SBC实例
概述 freeswitch 是一款好用的开源软交换平台. 随着voip客户的发展和运营商网络的升级换代,SBC在对接测试中的应用场景越来越多. freeswitch通过简单的安装配置即可满足大部分SB ...
- apicloud(沉浸式导航篇) - 手机状态栏 有黑边的解决办法
在 index.html 的 apiready 中加上 第一种 : 可设置全屏 api.setFullScreen({ fullScreen: true }); 第二种:设置状 ...
- 百度网盘(百度云)SVIP超级会员共享账号每日更新(2023.12.11)
一.百度网盘SVIP超级会员共享账号 可能很多人不懂这个共享账号是什么意思,小编在这里给大家做一下解答. 我们多知道百度网盘很大的用处就是类似U盘,不同的人把文件上传到百度网盘,别人可以直接下载,避免 ...
- 【面试题精讲】Java Stream排序的实现方式
首发博客地址 系列文章地址 如何使用Java Stream进行排序 在Java中,使用Stream进行排序可以通过sorted()方法来实现.sorted()方法用于对Stream中的元素进行排序操作 ...
- [转帖]OceanBase 中租户管理
https://zhuanlan.zhihu.com/p/464504887 概述 租户的概念类似于传统数据库的数据库实例.租户也叫实例,拥有一定的资源能力(如CPU.内存和空间).租户下可以建立数据 ...