【赵渝强老师】大数据工作流引擎Oozie

一、什么是工作流?
工作流(WorkFlow)就是工作流程的计算模型,即将工作流程中的工作如何前后组织在一起的逻辑和规则在计算机中以恰当的模型进行表示并对其实施计算。工作流要解决的主要问题是:为实现某个业务目标,在多个参与者之间,利用计算机,按某种预定规则自动传递。下面我们以“员工请假的流程”为例,来为大家介绍什么是工作流。
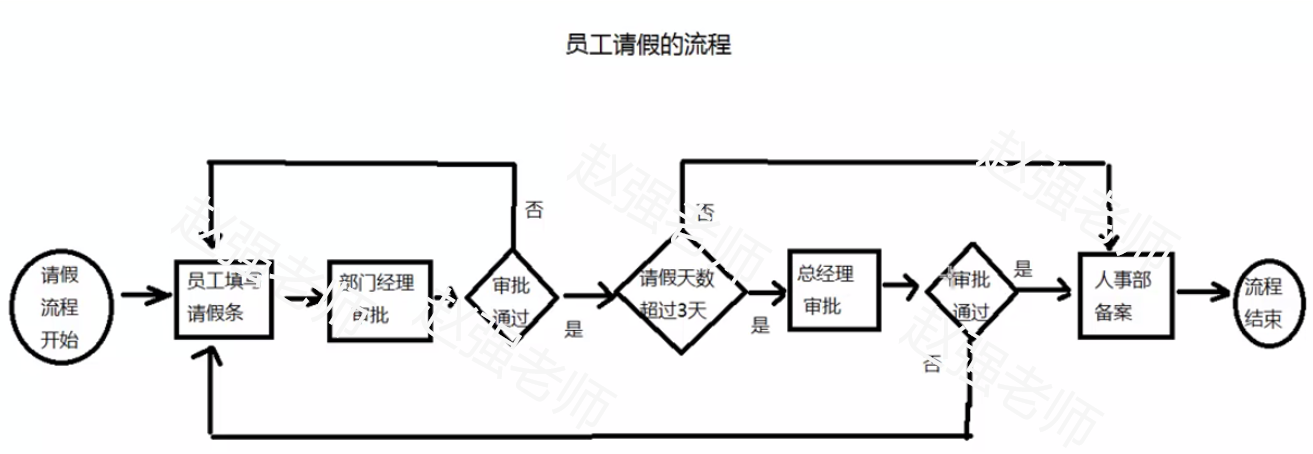
这个例子包含了一个完整的员工请假流程。从“请假流程开始”,到“员工填写请假条”,再到“部门经理审批”,如果审批不通过,流程回到“员工填写请假条”;如果部门经理审批通过,则流程进入下一个节点;直到最后的流程结束。在Java中,我们可以使用一些框架帮助我们来实现这样的过程。Java的三大主流工作流引擎分别是:Shark,osworkflow,JBPM
二、什么是Oozie?
关于什么是Oozie,其实Oozie是服务于Hadoop生态系统的工作流调度工具,Job运行平台是区别于其他调度工具的最大的不同。但其实现的思路跟一般调度工具几乎完全相同。Oozie工作流通过HPDL(一种通过XML自定义处理的语言,类似JBOSS JBPM的JPDL)来构造。Oozie工作流中的Action在运程系统运行如(Hadoop,Pig服务器上)。一旦Action完成,远程服务器将回调Oozie的接口 并通知Action已经完成,这时Oozie又会以同样的方式执行工作流中的下一个Action,直到工作流中所有Action都完成(完成包括失败)。Oozie工作流提供各种类型的Action用于支持不同的需要,如Hadoop Map/Reduce,Hadoop File System,Pig,SSH,HTTP,Email,Java以及Oozie子流程。Oozie也支持自定义扩展以上各种类型的Action。
一个正常工作的Oozie系统须包含如下四个模块:Oozie Client、Oozie Server、DataBase和Hadoop集群。
- Oozie Client可以通过Web Service API、Java API、Command line 方式向Oozie Server提交工作流任务请求。Oozie客户端可以通过REST API或者Web GUI来从Oozie服务端获取Job的日志流。通常在Client端包括工作流配置文件、工作流属性文件和工作流库。
- Oozie Server负责接收客户端请求、调度工作任务、监控工作流的执行状态。Oozie本身不会执行具体的Job,而是将Job的配置信息发送到执行环境。
- DataBase用于存储Bundle、Coordinator、Workflow工作流的Action信息、Job信息,记录Oozie系统信息。简单说,除了Oozie 运行日志存在本地硬盘不存在DB中,其他信息都存储到DB。
- Hadoop集群运行Oozie工作流的实体,负责处理Oozie Server提交来的各种Job。包括HDFS、MapReduce、Hive、Sqoop等Hadoop组件提交的Job。
三、编译Oozie
- 使用的版本信息如下
Hadoop 2.4.1
JDK 1.7
Maven 3.5.0
Oozie 4.3
在oozie解压后的目录下,编译oozie,执行命令:
bin/mkdistro.sh -DskipTests -Dhadoop.version=2.4.1
注意:如果第一次安装,Maven会自动下载依赖的jar包,时间可能 会比较长。
- 如果出现下面的错误,表示Maven的内存溢出。

设置环境变量:export MAVEN_OPTS="-Xmx512m -XX:MaxPermSize=128m"
并且重新编译。
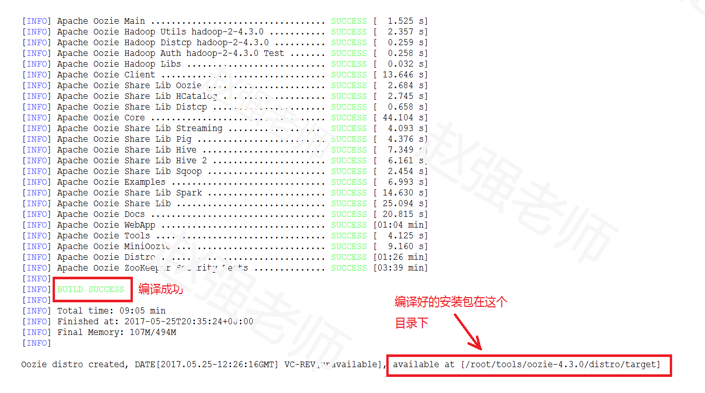
- 编译完成,成功出现以下提示。
四、安装部署Oozie
- 解压安装包
tar -zxvf oozie-4.3.0-distro.tar.gz -C ~/training/
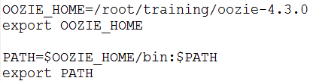
- 设置环境变量
- 建立MySQL数据库
create database oozie;
create user 'oozieowner'@'%' identified by 'password';
grant all on oozie.* TO 'oozieowner'@'%';
grant all on oozie.* TO 'oozieowner'@'localhost' identified by 'password';
- 修改文件:conf/oozie-site.xml

- 配置oozie的web console
(*)创建目录:mkdir /root/training/oozie-4.3.0/libext
(*)将文件ext-2.2.zip和mysql的驱动上传到这个目录
(*)拷贝$HADOOP_HOME/share/hadoop/*/*.jar和$HADOOP_HOME/share/hadoop/*/lib/*.jar到Oozie的libext目录下
(*)由于hadoop和oozie自带的tomcat jar包有冲突,所以需要把冲突的jar包驱动。执行下面的命令: cd /root/training/oozie-4.3.0/libext
mv servlet-api-2.5.jar servlet-api-2.5.jar.bak
mv jsp-api-2.1.jar jsp-api-2.1.jar.bak
mv jasper-compiler-5.5.23.jar jasper-compiler-5.5.23.jar.bak
mv jasper-runtime-5.5.23.jar jasper-runtime-5.5.23.jar.bak
- 初始化oozie
(*)生成oozie web console的war包:oozie-setup.sh prepare-war
(*)初始化数据库:ooziedb.sh create -sqlfile oozie.sql -run
(*)将不同任务依赖的共享jar包上传到HDFS:
oozie-setup.sh sharelib create -fs hdfs://hadoop111:9000 (*)修改oozie-4.3.0/oozie-server/conf/server.xml,注释掉下面的记录:

- 启动oozie和Hadoop的historyserver
oozied.sh start
mr-jobhistory-daemon.sh start historyserver
- 访问URL地址:http://192.168.88.111:11000/oozie/

【赵渝强老师】大数据工作流引擎Oozie的更多相关文章
- Facebook 正式开源其大数据查询引擎 Presto
Facebook 正式宣布开源 Presto —— 数据查询引擎,可对250PB以上的数据进行快速地交互式分析.该项目始于 2012 年秋季开始开发,目前该项目已经在超过 1000 名 Faceboo ...
- Apache Flink 为什么能够成为新一代大数据计算引擎?
众所周知,Apache Flink(以下简称 Flink)最早诞生于欧洲,2014 年由其创始团队捐赠给 Apache 基金会.如同其他诞生之初的项目,它新鲜,它开源,它适应了快速转的世界中更重视的速 ...
- 海胜专访--MaxCompute 与大数据查询引擎的技术和故事
摘要:在2019大数据技术公开课第一季<技术人生专访>中,阿里巴巴云计算平台高级技术专家苑海胜为大家分享了<MaxCompute 与大数据查询引擎的技术和故事>,主要介绍了Ma ...
- 大数据计算引擎之Flink Flink CEP复杂事件编程
原文地址: 大数据计算引擎之Flink Flink CEP复杂事件编程 复杂事件编程(CEP)是一种基于流处理的技术,将系统数据看作不同类型的事件,通过分析事件之间的关系,建立不同的时事件系序列库,并 ...
- 开发一个不需要重写成Hive QL的大数据SQL引擎
摘要:开发一款能支持标准数据库SQL的大数据仓库引擎,让那些在Oracle上运行良好的SQL可以直接运行在Hadoop上,而不需要重写成Hive QL. 本文分享自华为云社区< ...
- 工作流引擎Oozie(一):workflow
1. Oozie简介 Yahoo开发工作流引擎Oozie(驭象者),用于管理Hadoop任务(支持MapReduce.Spark.Pig.Hive),把这些任务以DAG(有向无环图)方式串接起来.Oo ...
- 即兴小探华为开源行业领先大数据虚拟化引擎openLooKeng
@ 目录 概述 定义 背景 特点 架构 关键技术 应用场景 安装 单台部署 集群部署 命令行接口 连接器 MySQL连接器 ClickHouse连接器 概述 定义 openLooKeng 官网地址 h ...
- 揭秘阿里云EB级大数据计算引擎MaxCompute
日前,全球权威咨询与服务机构Forrester发布了<The Forrester WaveTM: Cloud Data Warehouse, Q4 2018>报告.这是Forrester ...
- 大数据调度工具oozie详细介绍
背景 之前项目中的sqoop等离线数据迁移job都是利用shell脚本通过crontab进行定时执行,这样实现的话比较简单,但是随着多个job复杂度的提升,无论是协调工作还是任务监控都变得麻烦,我们选 ...
- 大数据技术之Oozie
第1章 Oozie简介 Oozie英文翻译为:驯象人.一个基于工作流引擎的开源框架,由Cloudera公司贡献给Apache,提供对Hadoop MapReduce.Pig Jobs的任务调度与协 ...
随机推荐
- [UE] 关于ue5中制作流日志记录
UE5目前根据现有功能,配合Quixel Bridge可以做到地编和一些简单的动画,实现完整的游戏,但是目前随着版本的迭代,流程的定制需要更新 ControlRig方便在UE中做动画的,模拟动画等,U ...
- 垃圾回收器比较:CMS 和 G1
前言 在查看系统内存监控的过程中,发现有几台机器的内存使用率一直很高,而且是呈现一个不太正常的高度,初始以为是 GC 不完全,也就是 JVM 内有大量对象不能回收,于是采用 Arthas 诊断查看一下 ...
- tar命令备份压缩7天生产日志
[root@localhost logs]# cat tar_7day.sh #!/bin/bash #压缩日期[当天的前一天] todayStamp_1=`date -d "-1 day& ...
- 【Uni-App】关于获取手机系统信息的项目实践
原因是这里APP下载方式的问题 安卓 和 IOS都可以写A标签跳转访问附件资源 但是甲方对这种下载方式并8满意[安卓行 苹果8行, 苹果行,安卓又8行] 通过 uni.getSystemInfo来判断 ...
- 《Python数据可视化之matplotlib实践》 源码 第二篇 精进 第六章
图 6.1 import matplotlib.pyplot as plt import numpy as np x=np.linspace(-2*np.pi, 2*np.pi, 200) y=np. ...
- 美的(Midea)超声波清洗机 眼镜清洗机 超声波洗眼镜 首饰剃须刀手表假牙牙套化妆刷 洗眼镜机超声波 MXV-01 —— 工业设计上的重大问题分析
前段时间买了一个美的的超声波清洗机,就是那种超声波洗眼镜的那种,本着买个高档的可以分体的那种好清洗的原则,就在JD上千挑万选后买了下面的这个货: 链接地址: https://item.jd.com/1 ...
- Auto.js 入门教程(二)
来了来了 ~ 下面开始学习auto.js 了! 准备材料 : android7.0及以上版本的手机一部(需要开启 '无障碍服务') auto.js软件 vscode (安装配套插件Auto.js-VS ...
- flex 左右布局-----在手机端,当左侧宽度固定,右侧宽度自适应时,右侧会超出浏览器窗口的问题解决方案
废话不多说:直接上代码解决问题: 父级: .parent { display: flex; flex-flow: row; } 子级: .left-child { width:100px; } .ri ...
- 4. 从0开始学ARM-ARM指令,移位、数据处理、BL、机器码
<到底什么是Cortex.ARMv8.arm架构.ARM指令集.soc?一文帮你梳理基础概念[科普]> 关于ARM指令用到的IDE开发环境可以参考下面这篇文章 <1. 从0开始学AR ...
- C# 菜单项添加复选标记
在网上查找都是说直接用菜单项的Checked属性, toolMenuItem.Checked=!toolMenuItem.Checked; 但是我用了也切换不过来. 有点晕菜了,我用的是vs2017. ...