声音好听,颜值能打,基于PaddleGAN给人工智能AI语音模型配上动态画面(Python3.10)
借助So-vits我们可以自己训练五花八门的音色模型,然后复刻想要欣赏的任意歌曲,实现点歌自由,但有时候却又总觉得少了点什么,没错,缺少了画面,只闻其声,却不见其人,本次我们让AI川普的歌声和他伟岸的形象同时出现,基于PaddleGAN构建“靓声靓影”的“懂王”。
PaddlePaddle是百度开源的深度学习框架,其功能包罗万象,总计覆盖文本、图像、视频三大领域40个模型,可谓是在深度学习领域无所不窥。
PaddleGAN视觉效果模型中一个子模块Wav2lip是对开源库Wav2lip的二次封装和优化,它实现了人物口型与输入的歌词语音同步,说白了就是能让静态图的唇部动起来,让人物看起来仿佛正在唱歌。
除此以外,Wav2lip还可以直接将动态的视频,进行唇形替换,输出与目标语音相匹配的视频,如此一来,我们就可以通过AI直接定制属于自己的口播形象了。
本机配置CUDA和cudnn
要想把PaddlePaddle框架在本地跑起来,并非易事,但好在有国内深度学习领域的巨擘百度进行背书,文档资源非常丰富,只要按部就班,就不会出太大问题。
首先,在本地配置好Python3.10开发环境,参见:一网成擒全端涵盖,在不同架构(Intel x86/Apple m1 silicon)不同开发平台(Win10/Win11/Mac/Ubuntu)上安装配置Python3.10开发环境
随后,需要在本地配置好CUDA和cudnn,cudnn是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。它就相当于工作的工具,而CUDA作为计算平台,就需要cudnn的配合,这俩个在版本上必须配套。
首先点击N卡控制中心程序,查看本机N卡驱动所支持的CUDA版本:
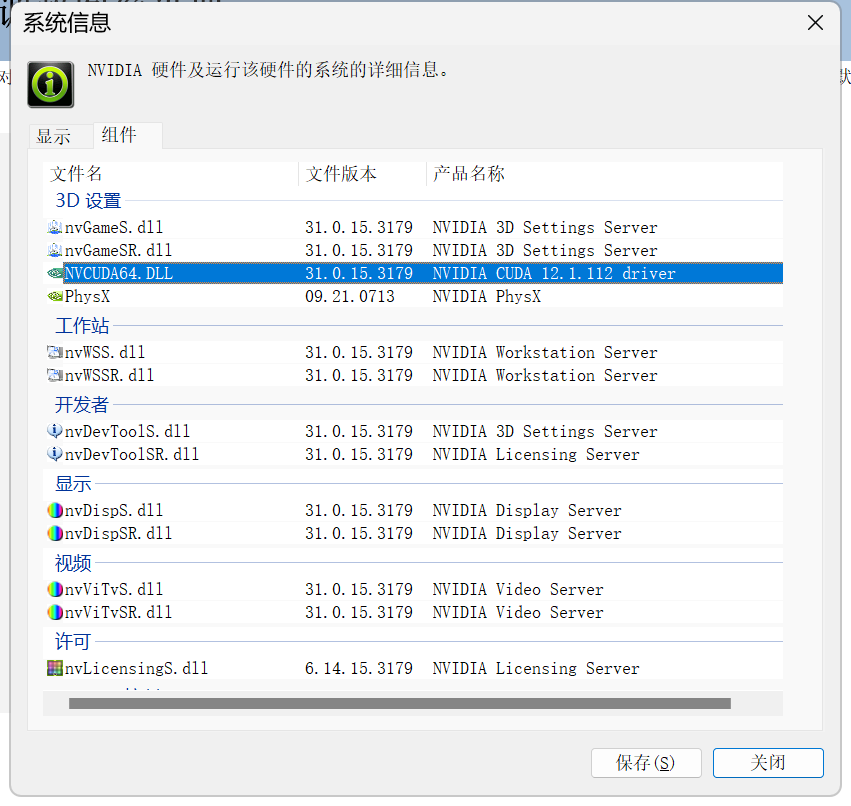
从图上可知,笔者的显卡是RTX4060,当前驱动最大支持CUDA12.1的版本,换句话说只要是小于等于12.1的CUDA就都是支持的。
随后查看PaddlePaddle框架的官方文档,查看Python3.10所支持的框架版本:
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/Tables.html#ciwhls-release
根据文档可知,对于Python3.10来说,PaddlePaddle最高的支持版本是win-cuda11.6-cudnn8.4-mkl-vs2017-avx,也就是CUDA的版本是11.6,cudnn的版本是8.4,再高就不支持了。
所以本机需要安装CUDA11.6和cudnn8.4。
注意版本一定要吻合,否则后续无法启动程序。
知晓了版本号,我们只需要去N卡的官网下载安装包即可。
CUDA11.6安装包下载地址:
https://developer.nvidia.com/cuda-toolkit-archive
cudnn8.4安装包下载地址:
https://developer.nvidia.com/rdp/cudnn-archive
首先安装CUDA11.6,安装完成后,解压cudnn8.4压缩包,将解压后的文件拷贝到CUDA11.6安装目录中即可,CUDA安装路径是:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6
随后需要将bin目录添加到系统的环境变量中:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\bin
接着在终端进入demo文件夹:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\extras\demo_suite
执行bandwidthTest.exe命令,返回:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\extras\demo_suite>bandwidthTest.exe
[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: NVIDIA GeForce RTX 4060 Laptop GPU
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 12477.8
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 12337.3
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 179907.9
Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
即代表安装成功,随后可通过deviceQuery.exe查询GPU设备:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\extras\demo_suite>deviceQuery.exe
deviceQuery.exe Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "NVIDIA GeForce RTX 4060 Laptop GPU"
CUDA Driver Version / Runtime Version 12.1 / 11.6
CUDA Capability Major/Minor version number: 8.9
Total amount of global memory: 8188 MBytes (8585216000 bytes)
MapSMtoCores for SM 8.9 is undefined. Default to use 128 Cores/SM
MapSMtoCores for SM 8.9 is undefined. Default to use 128 Cores/SM
(24) Multiprocessors, (128) CUDA Cores/MP: 3072 CUDA Cores
GPU Max Clock rate: 2370 MHz (2.37 GHz)
Memory Clock rate: 8001 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 33554432 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: zu bytes
Total amount of shared memory per block: zu bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1536
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: zu bytes
Texture alignment: zu bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model)
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 12.1, CUDA Runtime Version = 11.6, NumDevs = 1, Device0 = NVIDIA GeForce RTX 4060 Laptop GPU
Result = PASS
至此,CUDA和cudnn就配置好了。
配置PaddlePaddle框架
配置好CUDA之后,让我们来安装PaddlePaddle框架:
python -m pip install paddlepaddle-gpu==2.4.2.post116 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
这里安装paddlepaddle的gpu版本,版本号是2.4.2.post116,2.4是最新版,其中116就代表Cuda的版本,注意版本一定不能弄错。
随后克隆PaddleGan项目:
git clone https://gitee.com/PaddlePaddle/PaddleGAN
运行命令本地编译安装PaddleGan项目:
pip install -v -e .
随后再安装其他依赖:
pip install -r requirements.txt
这里有几个坑,需要说明一下:
首先PaddleGan依赖的numpy库还是老版本,它不支持最新的1.24版本,所以如果您的numpy版本是1.24,需要先把numpy卸载了:
pip uninstall numpy
随后安装1.21版本:
pip install numpy==1.21
接着在Python终端中验证PaddleGan是否安装成功:
import paddle
paddle.utils.run_check()
如果报这个错误:
PreconditionNotMetError: The third-party dynamic library (cudnn64_7.dll) that Paddle depends on is not configured correctly. (error code is 126)
Suggestions:
1. Check if the third-party dynamic library (e.g. CUDA, CUDNN) is installed correctly and its version is matched with paddlepaddle you installed.
2. Configure third-party dynamic library environment variables as follows:
- Linux: set LD_LIBRARY_PATH by `export LD_LIBRARY_PATH=...`
- Windows: set PATH by `set PATH=XXX; (at ..\paddle\phi\backends\dynload\dynamic_loader.cc:305)
[operator < fill_constant > error]
则需要下载cudnn64_7.dll动态库,然后复制到CUDA11.6的bin目录中,动态库地址后面会贴出来。
再次运行验证程序,返回:
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import paddle
>>> paddle.utils.run_check()
Running verify PaddlePaddle program ...
W0517 20:15:34.881800 31592 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.9, Driver API Version: 12.1, Runtime API Version: 11.6
W0517 20:15:34.889958 31592 gpu_resources.cc:91] device: 0, cuDNN Version: 8.4.
PaddlePaddle works well on 1 GPU.
PaddlePaddle works well on 1 GPUs.
PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.
说明大功告成,安装成功。
本地推理
下面我们给川普的歌曲配上动态画面,首先通过Stable-Diffusion生成一张懂王的静态图片:

关于Stable-Diffusion,请移步:人工智能,丹青圣手,全平台(原生/Docker)构建Stable-Diffusion-Webui的AI绘画库教程(Python3.10/Pytorch1.13.0),囿于篇幅,这里不再赘述。
接着进入到项目的tools目录:
\PaddleGAN\applications\tools>
将川普的静态图片和歌曲文件放入tools目录中。
接着运行命令,进行本地推理:
python .\wav2lip.py --face .\Trump.jpg --audio test.wav --outfile pp_put.mp4 --face_enhancement
这里--face是目标图片,--audio则是需要匹配唇形的歌曲,--outfile参数是输出视频。
face_enhancement:参数可以添加人脸增强,不添加参数默认为不使用增强功能。
但添加了这个参数需要单独下载模型文件。
Wav2Lip实现唇形与语音精准同步突破的关键在于,它采用了唇形同步判别器,以强制生成器持续产生准确而逼真的唇部运动。此外,它通过在鉴别器中使用多个连续帧而不是单个帧,并使用视觉质量损失(而不仅仅是对比损失)来考虑时间相关性,从而改善了视觉质量。
具体效果:

结语
有的时候,人工智能AI技术的发展真的会让人有一种恍若隔世的感觉,耳听未必为实,眼见也未必为真。最后,成品视频可在Youtube平台(B站)搜索:刘悦的技术博客,欢迎诸君品鉴,本文所有涉及的安装包和动态库请参见:
https://pan.baidu.com/s/1-6NA2uAOSRlT4O0FGEKUGA?pwd=oo0d
提取码:oo0d
声音好听,颜值能打,基于PaddleGAN给人工智能AI语音模型配上动态画面(Python3.10)的更多相关文章
- 闻其声而知雅意,基于Pytorch(mps/cpu/cuda)的人工智能AI本地语音识别库Whisper(Python3.10)
前文回溯,之前一篇:含辞未吐,声若幽兰,史上最强免费人工智能AI语音合成TTS服务微软Azure(Python3.10接入),利用AI技术将文本合成语音,现在反过来,利用开源库Whisper再将语音转 ...
- 1个多商户、多平台版 微信小程序(多商户、多平台版),影城行业、影业连锁 多商户、多平台版微信小程序。(基于多平台版,支持在业务上 可给 每个单独影城 分发定制单独的小程序版本)
1个 影城行业 微信小程序(多商户.多平台版), 影业连锁 多商户.多平台版微信小程序.(基于多平台版,支持在业务上 可给 每个单独影城 分发定制单独的小程序版本) 资讯QQ: 876635409 ...
- 基于隐马尔科夫模型(HMM)的地图匹配(Map-Matching)算法
文章目录 1. 1. 摘要 2. 2. Map-Matching(MM)问题 3. 3. 隐马尔科夫模型(HMM) 3.1. 3.1. HMM简述 3.2. 3.2. 基于HMM的Map-Matchi ...
- 基于SourceTree 下的 Git Flow 模型
基于SourceTree 下的 Git Flow 模型 1. sourceTree 是一个开源的git 图形管理工具,可下载mac版本,windows版本 2. Git Flow 是一套使用Git进 ...
- 谈谈分布式事务之二:基于DTC的分布式事务管理模型[下篇]
[续上篇] 当基于LTM或者KTM的事务提升到基于DTC的分布式事务后,DTC成为了本机所有事务型资源管理器的管理者:此外,当一个事务型操作超出了本机的范 围,出现了跨机器的调用后,本机的DTC需要于 ...
- 基于UML网络教学管理平台模型的搭建
一.基本信息 标题:基于UML网络教学管理平台模型的搭建 时间:2013 出版源:网络安全技术与应用 领域分类:UML:网络教学管理平台:模型 二.研究背景 问题定义:网络教学管理平台模型的搭建 难点 ...
- 基于R语言的时间序列指数模型
时间序列: (或称动态数列)是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列.时间序列分析的主要目的是根据已有的历史数据对未来进行预测.(百度百科) 主要考虑的因素: 1.长期趋势(Lon ...
- 解读 --- 基于微软企业商务应用平台 (Microsoft Dynamics 365) 之上的人工智能 (AI) 解决方案
9月25日微软今年一年一度的Ignite 2017在佛罗里达州奥兰多市还是如期开幕了.为啥这么说?因为9月初五级飓风厄玛(Hurricane Irma) 在佛罗里达州登陆,在当地造成了挺大的麻烦.在这 ...
- 转:从头开始编写基于隐含马尔可夫模型HMM的中文分词器
http://blog.csdn.net/guixunlong/article/details/8925990 从头开始编写基于隐含马尔可夫模型HMM的中文分词器之一 - 资源篇 首先感谢52nlp的 ...
- 基于Python的信用评分卡模型分析(二)
上一篇文章基于Python的信用评分卡模型分析(一)已经介绍了信用评分卡模型的数据预处理.探索性数据分析.变量分箱和变量选择等.接下来我们将继续讨论信用评分卡的模型实现和分析,信用评分的方法和自动评分 ...
随机推荐
- 手把手带你玩转Linux
今天这篇文章带你走进Linux世界的同时,带你手把手玩转Linux,加深对Linux系统的认识. 一.搞好Linux工作必须得不断折腾,说白了,只是动手力量必须强.我在初学Linux的那片,家中三台计 ...
- 小笨自采集在线电脑壁纸 v2.0-支持移动端自适应,支持https
这周闲着没事,翻着网站,记得去年的发表的一篇文章小笨分享一款高清电脑壁纸API,主要是将孟坤壁纸改造支持https,还加了一个搜索功能.以前的壁纸是这样的: 但是,不支持移动端浏览,于是小笨趁着这周周 ...
- 爬取JSON文件并且存储
思路 1 先调用模块 2 定义一个函数 2.1 获取网址(点击评论 找到JSON的文件(分析评论preview)获取Request URL后面的地址) 2.2 添加用户的请求头 2.3 使用get方法 ...
- 机器学习基础04DAY
scikit-learn数据集 我们将介绍sklearn中的数据集类,模块包括用于加载数据集的实用程序,包括加载和获取流行参考数据集的方法.它还具有一些人工数据生成器. sklearn.dataset ...
- LeetCode刷题笔记 - 2022
这篇博客集中整理在LeetCode的刷题记录,方便查阅 258. 各位相加 - 力扣(LeetCode) (leetcode-cn.com) 代码 class Solution { public: i ...
- python入门教程之一 什么是python
python简介 1 什么是python Python是一种计算机程序设计语言.你可能已经听说过很多种流行的编程语言,比如非常难学的C语言,非常流行的Java语言,适合初学者的Basic语言,适合网页 ...
- MySQL之 InnoDB 内存结构
从MySQL 5.5版本开始默认 使用InnoDB作为引擎,它擅长处理事务,具有自动崩溃恢复的特性,在日常开发中使用非常广泛 下面是官方的InnoDB引擎架构图,主要分为内存结构和磁盘结构两大部分. ...
- Java代理之jdk动态代理+应用场景实战
本文将先介绍jdk动态代理的基本用法,并对其原理和注意事项予以说明.之后将以两个最常见的应用场景为例,进行代码实操.这两个应用场景分别是拦截器和声明性接口,它们在许多开发框架中广泛使用.比如在spri ...
- FFmpeg开发笔记(一)搭建Linux系统的开发环境
对于初学者来说,如何搭建FFmpeg的开发环境是个不小的拦路虎,因为FFmpeg用到了许多第三方开发包,所以要先编译这些第三方源码,之后才能给FFmpeg集成编译好的第三方库.不过考虑到刚开始仅仅调用 ...
- 链式描述线性表(C++实现)
在链式描述中,线性表的元素在内存中的存储位置是随机的,每个元素都有一个明确的指针或链指向下一个元素的位置 chain类 在此使用单向链表实现了线性表,其中最后一个节点的指针域为NULL,即它用单向链接 ...