揭秘GES超大规模图计算引擎HyG:图切分
摘要:GES大规模图计算引擎HyG通过实现不同的点边分区算法,可以灵活地供用户选择多种多样的切分策略,进而达到更好的运算性能。
本文分享自华为云社区《GES超大规模图计算引擎HyG揭秘之图切分》,作者:π 。
对于超大规模图数据,点、边数量可以达到百亿甚至千亿、万亿,存储如此规模的图数据往往需要几百GB甚至几TB的存储空间,为了高效的图计算分析,往往需要将图数据存储于内存中,因此,对于超大规模的图数据,是没有办法将整张图存放在单机之上的,这就需要图计算框架对原始图进行切分,将一张大图切割成多个子图,然后将这些子图运行于一个集群之上,进而完成各种各样的图分析、图查询任务。GES大规模图计算引擎HyG通过实现不同的点边分区算法,可以灵活地供用户选择多种多样的切分策略,进而达到更好的运算性能。
一个好的图切分算法对于图计算引擎性能至关重要:
- 合理的切分可以使每个子图负载更加均衡,进而加快每轮的迭代速度
- 合理的切分可以大大降低子图之间的通信开销
图切分算法主要有两大分支:
- 离线切分 :需要加载完整的图数据,根据图整体的拓扑结构,进行多次迭代、聚类等方法,来获得高质量的分区边界
- 流式切分:在对点/边的划分过程中,被划分对象数据流式地传输到图划分模块中,当前对象的分区策略至多依赖于之前对象的分区状态,而与后续流式传输来的对象的信息无关
流式的图分区算法的优点
1) 内存占用小。流式的图分区算法每个分区只需要加载部分的图数据即可进行划分,各分区之间只需要较小的通讯代价即可完成对分区状态的同步。而离线的图分区算法需要加载完整的图数据,并且例如XtraPupl、Metis对整个图进行多次迭代,细化其分区,产生大量内存开销。
2) 分图效率高。流式的图分区算法中,对象流式地传入,即刻可以决定分区结果,对每个分区对象只需要遍历一次。并且支持多线程多个对象并行流式输入、分区,分区完成之后线程间同步分区状态,实现高效率的分区。而类似XtraPupl、Metis的离线分区算法,由于需要多次迭代,对一个对象的分区需要对遍历不止一次,并且由于其分区算法对图整体拓扑结构的依赖性高,导致其可开发的并行度不高,分图效率不如流式的图分区算法。
3) 分图质量相当,部分情况下更优。在对多种图计算算法和多个数据集的测试中,图计算推理时间开销各有优劣,但流式图分区中总有数个具体分区算法,其在图计算推理的时间开销优于离线图分区算法XtraPupl,用户使用流式图分区算法具有更高的灵活度,可以针对不同的算法、数据集、分区数量,选择合适的具体分区算法,获得更好的图计算推理性能。
我们的HyG图计算引擎就是采用流式切分算法进行图切分。
HyG图计算引擎如何实现图切分?
图切分最核心的就是两个步骤。1、如何将点分配到各个主机;2、如何将边分配到各个主机。HyG对这两个步骤进行了抽象,定义了以下两个方法:
getMaster(nodeID) //给定一个点ID,返回这个点需要分配给哪个主机
getEdgeOwner(edgeSrcID, edgeDstID) // 给定一条边,返回这个边需要分配给哪个主机
一旦给出了以上两个函数,HyG的切分器就可以完成大图的切分。业界和学术界有大量的图切分算法,本质的区别就是getMaster和getEdgeOwner的实现不同,几乎所有的图切分算法都可以重写成这种模式。下面我们举一个出边切(OEC)的例子,看看HyG是怎么通过重定义getMaster和getEdgeOwner两个函数完成图切分的。
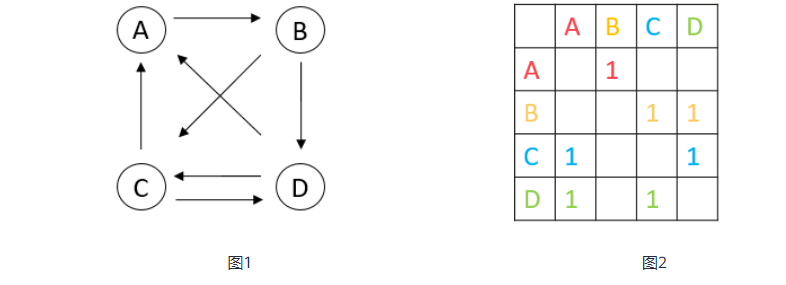
首先我们定义
GetMaster(nodeID)
return floor(nodeID / hostNum)
这个函数很简单,就是点ID除以主机数量然后向下取整,图1我们有4个顶点,假设我们有4个主机,这样的话就为每个主机分配了一个点。
然后我们定义
GetEdgeOwner(edgeSrcID, edgeDstID)
return masterOf(edgeSrcID)
这个函数也很简单,就是获取边的源顶点所在的主机ID,因为GetMaster已经完成了点的划分,因此这一步直接查询就可以得到结果。这样的话切分器就明确了这条边应该分配给哪个主机。
在完成GetMaster和GetEdgeOwner的定义后,HyG就可以将原始的图切分成4个子图,如图3所示。
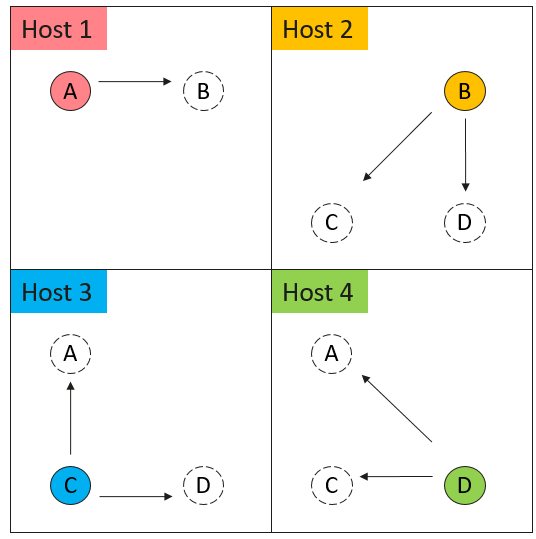
图3
上面提到的切分示例是最简单的一种切分方法,在现实应用场景下,往往需要更为复杂的切分策略才能达到有效、均衡的切分效果。
HyG实现的点分区算法主要分为两类:ContiguousEB和FennelEB。
1) ContiguousEB直接将点分配给在读图阶段读取该点的分区,不进行额外的分区操作。
2) FennelEB在分区时会维护当前的分区状态,流式读取到顶点后,会根据各分区的已分配数量、该顶点在各分区的局部性,为每个分区生成一个评分,将顶点分配到评分最高的分区中。
HyG实现的边分区算法主要分为三类:Source,Hybrid和Cartesian。
1) Source直接将边分配给其对应顶点所在的分区,如果是以出边划分的算法,即将其划分给源顶点所在的分区,如果是以入边划分的算法,即将其划分给目标顶点所在的分区。
2) Hybrid设定一个阈值threshold,顶点度数低于阈值的称为低度顶点,高于阈值的视为高度顶点。这种边分区算法保证了低度顶点的局部性,同时将高度顶点分散开来,避免了少数高度顶点带来的负载不均衡问题。
3) Cartesian将邻接矩阵切分为数个二维网格,每个网格对应一个分区,将边按照网格划分,这种分区算法保留了一定的局部性,同时可以获得更好的负载均衡。
HyG通过实现不同的点分区算法(GetMaster)和不同的边分区算法(GetEdgeOwner),可以实现多种多样的切分策略,非常的灵活好用,用户可以根据自己图数据的特点选择不同的切分策略,进而达到更好的运算性能。
目前HyG已上线至华为云GES服务,欢迎大家上手体验~
揭秘GES超大规模图计算引擎HyG:图切分的更多相关文章
- 图计算引擎分析——Gemini
前言 Gemini 是目前 state-of-art 的分布式内存图计算引擎,由清华陈文光团队的朱晓伟博士于 2016 年发表的分布式静态数据分析引擎.Gemini 使用以计算为中心的共享内存图分布式 ...
- 图计算引擎分析--GridGraph
作者:京东科技 李永萍 GridGraph:Large-Scale Graph Processing on a Single Machine Using 2-Level Hierarchical Pa ...
- 阿里重磅开源首款自研科学计算引擎Mars,揭秘超大规模科学计算
日前,阿里巴巴正式对外发布了分布式科学计算引擎 Mars 的开源代码地址,开发者们可以在pypi上自主下载安装,或在Github上获取源代码并参与开发. 此前,早在2018年9月的杭州云栖大会上,阿里 ...
- 腾讯正式开源图计算框架Plato,十亿级节点图计算进入分钟级时代
腾讯开源再次迎来重磅项目,14日,腾讯正式宣布开源高性能图计算框架Plato,这是在短短一周之内,开源的第五个重大项目. 相对于目前全球范围内其它的图计算框架,Plato可满足十亿级节点的超大规模图计 ...
- 腾讯开源进入爆发期,Plato助推十亿级节点图计算进入分钟级时代
腾讯开源再次迎来重磅项目,14日,腾讯正式宣布开源高性能图计算框架Plato,这是在短短一周之内,开源的第五个重大项目. 相对于目前全球范围内其它的图计算框架,Plato可满足十亿级节点的超大规模图计 ...
- GraphX 图计算实践之模式匹配抽取特定子图
本文首发于 Nebula Graph Community 公众号 前言 Nebula Graph 本身提供了高性能的 OLTP 查询可以较好地实现各种实时的查询场景,同时它也提供了基于 Spark G ...
- 图计算 on nLive:Nebula 的图计算实践
本文首发于 Nebula Graph Community 公众号 在 #图计算 on nLive# 直播活动中,来自 Nebula 研发团队的 nebula-plato 维护者郝彤和 nebula-a ...
- 关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph Learning (PGL))
关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph Learning (PGL)) 欢迎fork本项目原始链接:关于图计算&图学习的基础知识概览:前置知识点学习 ...
- 开源图计算框架GraphLab介绍
GraphLab介绍 GraphLab 是由CMU(卡内基梅隆大学)的Select 实验室在2010 年提出的一个基于图像处理模型的开源图计算框架.框架使用C++语言开发实现. 该框架是面向机器学习( ...
- 揭秘阿里云EB级大数据计算引擎MaxCompute
日前,全球权威咨询与服务机构Forrester发布了<The Forrester WaveTM: Cloud Data Warehouse, Q4 2018>报告.这是Forrester ...
随机推荐
- 随身wifi 救砖过程记录
7,8块钱买了个随身wifi,准备刷机玩的,后来不知道刷错了boot还是啥,加电后灯都不亮了,前期没备份,于是网上找了各种教程,下面记录下: 变砖后有个底层的9008驱动协议可以刷机,下面的过程都是基 ...
- 虹科案例 | 虹科Domo商业智能,助力保险公司逃离繁杂数据池!
金融行业的发展充满着不确定性,一个具备强大承保能力和精算专业知识的资金池,对于身处该领域的公司和个人都是十分必要的. 在全国城市联盟(NLC)的协助下成立的NCL Mutual会员制互助保险公司,为各 ...
- 高效技巧揭秘:Java轻松批量插入或删除Excel行列操作
摘要:本文由葡萄城技术团队原创并首发.转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 前言 在职场生活中,对Excel工作表的行和列进行操作是非常普遍的需求 ...
- 沫沫漫画网Js逆向分析爬取全站资源入库处理图片合并
网站分析 打开目标网站:https://www.momomh.com/ 选择一部漫画作为分析对象:<渴望:爱火难耐> 进到漫画详情页这里,发现并没有需要逆向分析.直接可以获取漫画信息.随便 ...
- gametime
这道题是动态调试的考点,看了wp才有思路 像这样的游戏题一定要搞清楚他的具体游戏流程才能更好的做出来,然后根据他的思路去改掉相关的判断就可以了 攻防世界逆向高手题之gametime_攻防世界 game ...
- 牛客多校第五场 K King of Range
题意: 给定一个\(n\)个数得序列\(a_i\),给定\(m\)个询问,每次给出一个\(k\),寻找有多少个区间\([l, r]\)中最大值与最小值之差严格大于\(k\). 思路: 可以发现,如果已 ...
- class-dump 混淆加固、保护与优化原理
class-dump 混淆加固.保护与优化原理 进行逆向时,经常需要dump可执行文件的头文件,用以确定类信息和方法信息,为hook相关方法提供更加详细的数据.class-dump的主要用于检查存 ...
- 吉特日化MES系统&各类化妆品检验标准汇总
在日化行业中,生产配料过程中,对产品的检验主要分为四大类: (1) 感官指标 (2) 理化指标 (3) 微生物指标 (4) 毒理指标 根据每个产品的不同,其指标会有所不同
- SpringBoot使用maven打jar包配置
在pom.xml文件中加入依赖 <parent> <groupId>org.springframework.boot</groupId> <artifactI ...
- 实用指南:打造卓越企业BI实施解决方案
前言 随着大数据时代的到来,商业智能(BI)工具变得非常重要.一个全面的商业智能方案可以支持数据驱动的决策并提高决策效率,同时还可以准确反映企业运行状态,为企业持续增长提供新的动力.本文小编将为大家介 ...