[转帖]oracle 11g 分区表创建(自动按年、月、日分区)
https://www.cnblogs.com/yuxiaole/p/9809294.html
前言:工作中有一张表一年会增长100多万的数据,量虽然不大,可是表字段多,所以一年下来也会达到 1G,而且只增不改,故考虑使用分区表来提高查询性能,提高维护性。
oracle 11g 支持自动分区,不过得在创建表时就设置好分区。
如果已经存在的表需要改分区表,就需要将当前表 rename后,再创建新表,然后复制数据到新表,然后删除旧表就可以了。
一、为什么要分区(Partition)
1、一般一张表超过2G的大小,ORACLE是推荐使用分区表的。
2、这张表主要是查询,而且可以按分区查询,只会修改当前最新分区的数据,对以前的不怎么做删除和修改。
3、数据量大时查询慢。
4、便于维护,可扩展:11g 中的分区表新特性:Partition(分区)一直是 Oracle 数据库引以为傲的一项技术,正是分区的存在让 Oracle 高效的处理海量数据成为可能,在 Oracle 11g 中,分区技术在易用性和可扩展性上再次得到了增强。
5、与普通表的 sql 一致,不需要因为普通表变分区表而修改我们的代码。
二、oracle 11g 如何按天、周、月、年自动分区
2.1 按年创建
numtoyminterval(1, 'year')
--按年创建分区表
create table test_part
(
ID NUMBER(20) not null,
REMARK VARCHAR2(1000),
create_time DATE
)
PARTITION BY RANGE (CREATE_TIME) INTERVAL (numtoyminterval(1, 'year'))
(partition part_t01 values less than(to_date('2018-11-01', 'yyyy-mm-dd'))); --创建主键
alter table test_part add constraint test_part_pk primary key (ID) using INDEX;
-- Create/Recreate indexes
create index test_part_create_time on TEST_PART (create_time);
2.2 按月创建
numtoyminterval(1, 'month')
--按月创建分区表
create table test_part
(
ID NUMBER(20) not null,
REMARK VARCHAR2(1000),
create_time DATE
)
PARTITION BY RANGE (CREATE_TIME) INTERVAL (numtoyminterval(1, 'month'))
(partition part_t01 values less than(to_date('2018-11-01', 'yyyy-mm-dd'))); --创建主键
alter table test_part add constraint test_part_pk primary key (ID) using INDEX;
2.3 按天创建
NUMTODSINTERVAL(1, 'day')
--按天创建分区表
create table test_part
(
ID NUMBER(20) not null,
REMARK VARCHAR2(1000),
create_time DATE
)
PARTITION BY RANGE (CREATE_TIME) INTERVAL (NUMTODSINTERVAL(1, 'day'))
(partition part_t01 values less than(to_date('2018-11-12', 'yyyy-mm-dd'))); --创建主键
alter table test_part add constraint test_part_pk primary key (ID) using INDEX;
2.4 按周创建
NUMTODSINTERVAL (7, 'day')
--按周创建分区表
create table test_part
(
ID NUMBER(20) not null,
REMARK VARCHAR2(1000),
create_time DATE
)
PARTITION BY RANGE (CREATE_TIME) INTERVAL (NUMTODSINTERVAL (7, 'day'))
(partition part_t01 values less than(to_date('2018-11-12', 'yyyy-mm-dd'))); --创建主键
alter table test_part add constraint test_part_pk primary key (ID) using INDEX;
2.5 测试
可以添加几条数据来看看效果,oracle 会自动添加分区。
--查询当前表有多少分区
select table_name,partition_name from user_tab_partitions where table_name='TEST_PART'; --查询这个表的某个(SYS_P21)里的数据
select * from TEST_PART partition(SYS_P21);
三、numtoyminterval 和 numtodsinterval 的区别
3.1 numtodsinterval(<x>,<c>) ,x 是一个数字,c 是一个字符串。
把 x 转为 interval day to second 数据类型。
常用的单位有 ('day','hour','minute','second')。
测试一下:
select sysdate, sysdate + numtodsinterval(4,'hour') as res from dual;
结果:
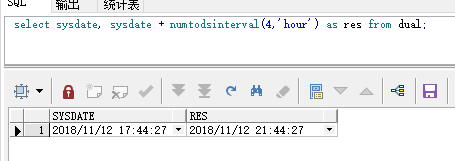
3.2 numtoyminterval (<x>,<c>)
将 x 转为 interval year to month 数据类型。
常用的单位有 ('year','month')。
测试一下:
select sysdate, sysdate + numtoyminterval(3, 'year') as res from dual;
结果:
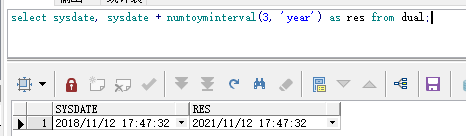
四、默认分区
4.1 partition part_t01 values less than(to_date('2018-11-01', 'yyyy-mm-dd'))。
表示小于 2018-11-01 的都放在 part_t01 分区表中。
五、给已有的表分区
需要先备份表,然后新建这个表,拷贝数据,删除备份表。
-- 1. 重命名
alter table test_part rename to test_part_temp; -- 2. 创建 partition table
create table test_part
(
ID NUMBER(20) not null,
REMARK VARCHAR2(1000),
create_time DATE
)
PARTITION BY RANGE (CREATE_TIME) INTERVAL (numtoyminterval(1, 'month'))
(partition part_t1 values less than(to_date('2018-11-01', 'yyyy-mm-dd'))); -- 3. 创建主键
alter table test_part add constraint test_part_pk_1 primary key (ID) using INDEX; -- 4. 将 test_part_temp 表里的数据迁移到 test_part 表中
insert into test_part_temp select * from test_part; -- 5. 为分区表设置索引
-- Create/Recreate indexes
create index test_part_create_time_1 on TEST_PART (create_time); -- 6. 删除老的 test_part_temp 表
drop table test_part_temp purge; -- 7. 作用是:允许分区表的分区键是可更新。
-- 当某一行更新时,如果更新的是分区列,并且更新后的列植不属于原来的这个分区,
-- 如果开启了这个选项,就会把这行从这个分区中 delete 掉,并加到更新后所属的分区,此时就会发生 rowid 的改变。
-- 相当于一个隐式的 delete + insert ,但是不会触发 insert/delete 触发器。
alter table test_part enable row movement;
我的理解是:
当查询经常跨分区查,则应该使用全局索引,因为这是全局索引比分区索引效率高。
当查询在一个分区里查询时,则应该使用 local 索引,因为本地索引比全局索引效率高。
扩展:https://blog.csdn.net/lively1982/article/details/9398485
分区索引:
https://www.cnblogs.com/grefr/p/6095005.html
https://blog.csdn.net/w892824196/article/details/82803889
[转帖]oracle 11g 分区表创建(自动按年、月、日分区)的更多相关文章
- oracle 11g 分区表创建(自动按年、月、日分区)
前言:工作中有一张表一年会增长100多万的数据,量虽然不大,可是表字段多,所以一年下来也会达到 1G,而且只增不改,故考虑使用分区表来提高查询性能,提高维护性. oracle 11g 支持自动分区,不 ...
- Oracle 11g R2创建数据库之手工建库方式
在之前的博文当中梳理了关于DBCA静默方式创建数据库的过程,本文就手工通过SQL*PLUS客户端采用CREATE DATABASE语句创建数据库.这种建库方式就是完全使用手工SQL语句创建数据库,通常 ...
- oracle 11g中的自动维护任务管理
因为人员紧缺,最近又忙着去搞性能优化的事情,有时候真的是不想再搞这个事情,只是没办法,我当前的绩效几乎取决于这个项目的最终成绩,所以不管是人的事还是事的事,都得去让他顺利推进. 前段时间发生还有几台服 ...
- oracle 11g 如何创建、修改、删除list-list组合分区
Oracle11g在分区方面做了很大的提高,不但新增了4种复合分区类型,还增加了虚拟列分区.系统分区.INTERVAL分区等功能. 9i开始,Oracle就包括了2种复合分区,RANGE-HASH和R ...
- [转帖]Oracle 11G RAC For Windows 2008 R2部署手册
Oracle 11G RAC For Windows 2008 R2部署手册(亲测,成功实施多次) https://www.cnblogs.com/yhfssp/p/7821593.html 总体规划 ...
- Oracle 11g R2创建数据库之DBCA静默方式
通常创建Oracle数据库都是通过DBCA(Database Configuration Assistant)工具完成的,DBCA工具可以通过两种方式完成建库任务,即图形界面方式和静默命令行方式.既然 ...
- oracle 11g dataguard创建的简单方法
oracle 10g可以通过基于备份的rman DUPLICATE实现dataguard,通过步骤需要对数据库进行备份,并在standby侧进行数据库的恢复.而到了11g,oracle推出了Dupli ...
- oracle 11g 分区表
查看所有用户分区表及分区策略(1.2级分区表均包括): SELECT p.table_name AS 表名, decode(p.partitioning_key_count, 1, '主分区') AS ...
- oracle 11g数据库--创建表空间,创建用户,用户授权并指定表空间。
使用环境:我们安装完数据库后,查看以下服务是否启动 需要建库.实质上我们是建立表空间,从而进行库的还原工作. 根据本例情况,是在下面目录下进行的操作. D:\app\Administrator\ora ...
- Oracle 11g中创建实例
1.打开“所有程序” -> “Oracle -OraDb11g_home1” -> “配置移植工具” -> “Database Configuration Assistant”. ...
随机推荐
- 关于腾讯地图geolocation.getLocation 经常定位失败,定位时间过长的解决方法
今天遇到个项目,腾讯地图定位出现问题,导致地图无法呈现出最近的目标 这是正常的效果,之前一直出现贵州等地点的信息,查看控制台的网络后,发现腾讯的定位失败,要么就是定位时间过长,要20S左右,但是换ED ...
- zabbix常用监控项
https://blog.csdn.net/xkjcf/article/details/78559273?locationNum=10&fps=1 agent.ping #agent是否在线 ...
- UDP与KCP详解
UDP 以及TCP是什么.我们知道传输层中有TCP和UDP两种网络协议,这节就讲UDP是什么. Internet协议集支持一个无连接的传输协议,该协议称为用户数据报协议(UDP,User Datagr ...
- 欢迎使用CSDN-markdown编辑器测试
这里写自定义目录标题 欢迎使用Markdown编辑器 新的改变 功能快捷键 合理的创建标题,有助于目录的生成 如何改变文本的样式 插入链接与图片 如何插入一段漂亮的代码片 生成一个适合你的列表 创建一 ...
- java中synchronized和ReentrantLock的加锁和解锁能在不同线程吗?如果能,如何实现?
java中synchronized和ReentrantLock的加锁和解锁能在不同线程吗?如果能,如何实现? 答案2023-06-21: java的: 这个问题,我问了一些人,部分人是回答得有问题的. ...
- react+antd选择框输入
react+antd选择框输入 const onSearch=(fn,value)=>{ if(value){//这个if无比重要 form.setFieldsValue({"Owne ...
- 【小白学YOLO】一文带你学YOLOv1 Testing
摘要:本文将为初学者带详细分析如何进行YOLOv1 Testing的内容. YOLOv1 Testing 进入testing阶段,我们已经得到98个bounding box和confidence还有C ...
- 掌握ROMA Compose,报表清单不秃头
摘要:在没有ROMA Compose之前,完成一个跨数据源的关联查询是一个十分艰巨的任务. 1. ROMA Compose为何诞生 试想这样一个场景,主管让刚入职的小沛明天下班前给他发一份报表.小沛兴 ...
- GaussDB(for Redis)揭秘:Redis存算分离架构最全解析
前言: 本文根据华为云NoSQL数据库架构师余汶龙,在今年的中国系统架构师大会SACC上的演讲整理而成,内容如下. 本次分享的大纲分成如下四个部分: 什么是GaussDB(for Redis)? 为什 ...
- Apache Pulsar 在火山引擎 EMR 的集成与场景
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 近年来,基于云原生架构的新一代消息队列和流处理引擎 Apache Pulsar 在大数据领域发挥着愈发重要的作用, ...