[转帖]【SOP】最佳实践之 TiDB 业务写变慢分析
https://zhuanlan.zhihu.com/p/647831844
前言
在日常业务使用或运维管理 TiDB 的过程中,每个开发人员或数据库管理员都或多或少遇到过 SQL 变慢的问题。这类问题大部分情况下都具有一定的规律可循,通过经验的积累可以快速的定位和优化。但是有些情况下不一定很好排查,尤其涉及到内核调优等方向时,如果事先没有对各个组件的互访关系、引擎存储原理等有一定的了解,往往难以下手。
本文针对写 TiDB 集群的场景,总结业务 SQL 在写突然变慢时的分析和排查思路,旨在沉淀经验、共享与社区。
写入原理
业务对集群的数据写入流程会被 TiDB Server 封装为一个个的写事务,写事务的完成主要涉及的组件是 TiDB Server 和 TiKV Server。如下所示,是 TiDB 集群写入流程的架构简图:
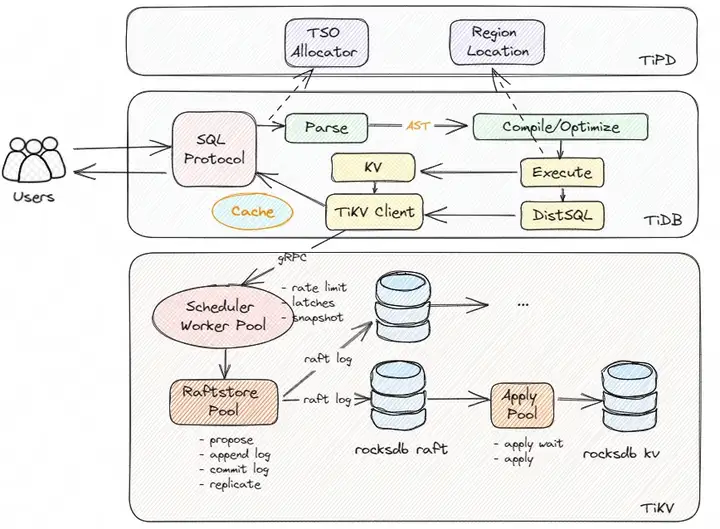
事务在写入的过程,分别会与 TiDB Server、TiPD Server 和 TiKV Server进行交互:
TiDB Server
- 用户提交的业务 SQL 经过 Protocol Layer 进行 SQL 协议转换后,内部 PD Client 向 TiPD Server 申请到一个 TSO,此 TSO 即为事务的开始时间 txn_start_tso,同时也是事务在全局的唯一 ID
- 接着 TiDB Server 对 SQL 文本进行解析处理,转为抽象语法树 AST 传给下一个处理模块
- TiDB Server 对 AST 进行编译、SQL 等价改写等逻辑优化、参考系统统计信息进行物理优化后,会生成真正可以执行的计划
- 可执行的计划经过分析判断,点查询操作转到KV模块、复杂查询转到 DistSQL 模块(继续转为对单个表访问的多个请求),再经过 TiKV Client 模块与 TiKV 进行交互,在 TiDB Server 这一侧完成对数据的访问
TiKV Server
TiKV 的 Scheduler Worker Pool 模块负责接收通过 gRPC 传过来的写请求数据,在这里它能实现写入流量的控制、锁冲突检查与获取(latch)、快照(snapshot)版本对比的功能
前面的校验通过后,写入的数据会进入到 Raftstore Pool 模块,它会将写入数据的请求封装为 raft log (Propose ),在本地持久化(append)的同时并发分发到 follower 节点,接着完成 raft log 的 commit 操作,最后将 raft log 日志数据写入到 rocksdb raft
Apply Pool 模块充当消费者的的角色,会消费 rocksdb raft 里面的日志数据,转为真正的 KV 数据存储到 rocksdb KV,至此完成了一次写入数据的流程
- rocksdb 里面的数据写入包括了 LSM Tree 的写入过程,主要方面有 WAL、MemTable 、Immutable Table、L0~L6 层的内存或磁盘 IO 操作,这里并没有详细阐述,有兴趣的可以前往官网查阅。
图中 Raftstore Pool 和 Apply Pool 这两步通常统称为 Async Write 操作,这个是 TiKV 写入数据的关键流程,也是数据写入分析的重点环节所在。
- Raftstore Pool 和 Apply Pool 处理数据的过程涉及到线程池的调度和处理等,主要消耗 CPU 资源
- rocksdb raft 和 rocksdb kv 由于涉及到数据落盘,主要消耗磁盘 IO 资源
- 数据在不同 TiKV 节点之间进行复制、同步等,主要消耗网络带宽 IO 资源
写变慢排查思路
常规排查
通常业务的 SQL 变慢后,我们在 TiDB Server 的 Grafana 面板可以看到整体的或者某一百分位的请求延迟会升高,我们可以依次排查物理硬件环境、是否有业务变更操作、数据库运行的情况等,定位到问题后再针对性解决。
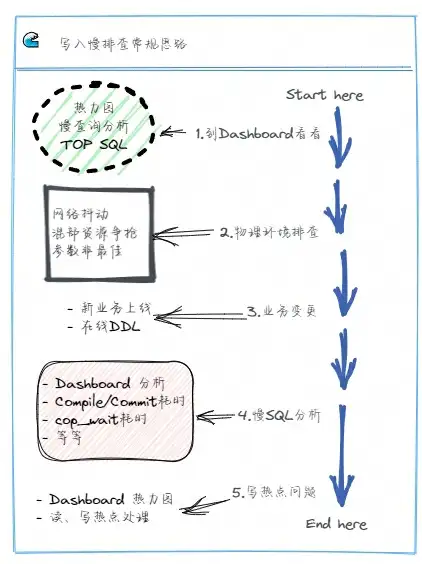
如上图是一个写入慢的常规排查思路,在实际工作中对于各项内容的排查可以同时进行,交叉分析,互相配合定位问题所在。
遇到问题,先到 Dashboard 看看,对整个集群运行状况有个整体的把握
- 查看集群热力图,关注集群高亮的区域,分析是否有写热点出现,如果有则确认对应的库表、Region 等信息
- 排查慢 SQL 情况,查看集群慢查询结果,分析 SQL 慢查询原因
- 查看 TOP SQL 面板,分析集群的 CPU 消耗与 SQL 关联的情况
物理硬件排查
- 排查客户端与集群之间、集群内部 TiDB 、TiPD、TiKV 各组件之间的网络问题
- 排查集群的内存、CPU、磁盘 IO 等情况,尤其是混合部署的集群,确认是否存在资源相互竞争、挤兑的场景出现
- 排查操作系统的内核操作是否与官方建议的最佳实践值是否一致,确认 TiDB 集群运行在最优的系统环境内
业务变更
- 确认是否是新上线业务
- 查看集群的 DDL Jobs,确认是否由于在线 DDL 导致的问题,特别是大表加索引的场景,会消耗集群较多的资源,从而干扰集群正常的访问请求
全链路排查
对于常规分析无法确认的或者复杂业务的问题,通常排查起来比较棘手,这时候可以分析数据从写入 TiDB Server 到 TiKV Server 、再落盘至 RocksDB 的整个过程,对全部写入链路逐一进行排查,从而确认写入慢所在的节点,定位到原因后再进行优化即可,这一过程大致如下图所示。
毫无疑问,这个是一个兜底的排查思路,适用范围较广,通用性较强,但是排查起来要花费更多的时间和精力,也要求管理员对数据库本身的运行原理有一定的掌握。
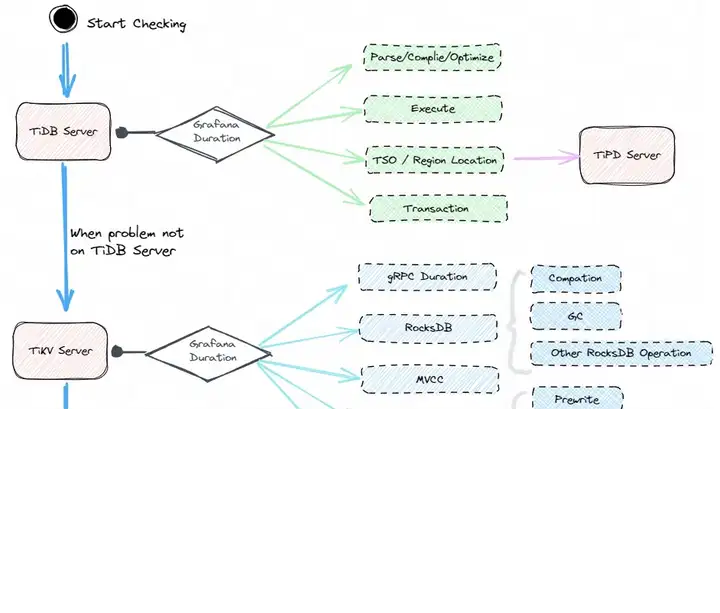
对于写入慢的全链路分析,我们首先在问题时段从整体上把握延迟情况,再分析 TiDB Server 和 TiKV Server 在对应时段的延迟,确认问题处于计算层还是存储层,接着再深入分析
- 对于 TiDB Server层,主要观察 SQL 的解析优化过程耗时,以及和 TiPD 进行交互过程的延迟情况
- 对于 TiKV Server 层,重点关注 Scheduler Worker Pool 、Raft log 同步复制与写入、Apply 这几个过程
上面的写入过程的延迟情况,可以从集群的 Grafana 监控面板观察得到,其中 TiKV 是重点所在,其每个阶段写入的流程以及对应在 Grafana 上的延迟监控面板如下。
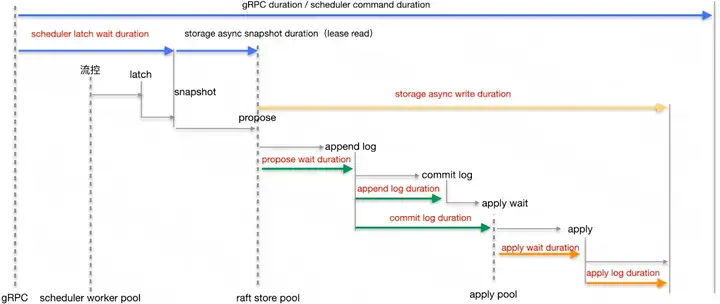
gRPC duration 或 Scheduler command duration 表示整个写入过程在 TiKV 侧的耗时情况
- gRPC duration 是请求在 TiKV 端的总耗时。通过对比 TiKV 的 gRPC duration 以及 TiDB 中的 KV duration 可以发现潜在的网络问题。比如 gRPC duration 很短但是 TiDB 的 KV duration 显示很长,说明 TiDB 和 TiKV 之间网络延迟可能很高,或者 TiDB 和 TiKV 之间的网卡带宽被占满
- TiKV Details 下 Scheduler - commit 的 Scheduler command duration 表示执行 commit 命令所需花费的时间,正常情况下,应该小于 1s
TiKV Details 下 Scheduler - commit 的 Scheduler latch wait duration表示由于等到锁 latch wait 造成的时间开销,正常情况下应该小于 1s
- TiKV Details 下 Storage 的 Storage async snapshot duration 表示异步处理 snapshot 所花费的时间,99% 的情况下应该小于 1s
- TiKV Details 下 Storage 的 Storage async write duration 表示异步写所花费的时间,99% 的情况下应该小于 1s
- TiKV Details 下 Raft propose 的 Propose wait duration 表示将写入数据请求转为 raft log 的等待时间
- TiKV Details 下 Raft IO 的 Append log duration 表示 Raft append 日志所花费的时间
- TiKV Details 下 Raft IO 的 Commit log duration 表示 Raft commit 日志所花费的时间
- TiKV Details 下 Raft propose 的 Apply wait duration 表示 apply 的等待时间
- TiKV Details 下 Raft IO 的 Apply log duration 表示 Raft apply 日志所花费的时间
通过对比分析不同阶段的延迟在整体中的占比,通常可以定位到比较慢的环节,然后再针对性优化即可。
总结
- 常规写入慢的问题,我们可以依次排查物理硬件环境、是否有业务新上线,是否有 DDL 变更操作、执行计划不准、热点问题等情况,通常可以定位到问题,再针对性解决
- 对于复杂问题则需要对写入过程逐一分析和对比,通常需要反复观察、对比、验证才能找到根本的原因
对于开发人员或 DBA,会解决具体的问题是一项很重要的能力,但定位问题根因所在的能力更难能可贵!
这里想表达的意思,和大家耳熟能详的故事异曲同工:
“老师傅,故障已排除,但就凭这一条线也要 10000$ ?!”
“画这条线要 1$,但知道在哪里画要 9999$”!
[转帖]【SOP】最佳实践之 TiDB 业务写变慢分析的更多相关文章
- PyTorch最佳实践,怎样才能写出一手风格优美的代码
[摘要] PyTorch是最优秀的深度学习框架之一,它简单优雅,非常适合入门.本文将介绍PyTorch的最佳实践和代码风格都是怎样的. 虽然这是一个非官方的 PyTorch 指南,但本文总结了一年多使 ...
- 【Yii系列】最佳实践之后台业务框架
缘起 上面的几章都讲概念了,没有怎么讲到实践的东西,可能会有些枯燥,这很正常的,概念还是需要慢慢啃的,尤其是官网其他的部分,需要狠狠的啃. 什么,你啃不动了?看看官网旁边的那个在线用户吧. 你不啃的时 ...
- Istio技术与实践04:最佳实践之教你写一个完整的Mixer Adapter
Istio内置的部分适配器以及相应功能举例如下: circonus:微服务监控分析平台. cloudwatch:针对AWS云资源监控的工具. fluentd:开源的日志采集工具. prometheus ...
- iOS系统中导航栏的转场解决方案与最佳实践
背景 目前,开源社区和业界内已经存在一些 iOS 导航栏转场的解决方案,但对于历史包袱沉重的美团 App 而言,这些解决方案并不完美.有的方案不能满足复杂的页面跳转场景,有的方案迁移成本较大,为此我们 ...
- 京东云TiDB SQL优化的最佳实践
京东云TiDB SQL层的背景介绍 从总体上概括 TiDB 和 MySQL 兼容策略,如下表: SQL层的架构 用户的 SQL 请求会直接或者通过 Load Balancer 发送到 京东云TiDB ...
- DDD实战进阶第一波(八):开发一般业务的大健康行业直销系统(业务逻辑条件判断最佳实践)
这篇文章其实是大健康行业直销系统的番外篇,主要给大家讲讲如何在领域逻辑中,有效的处理业务逻辑条件判断的最佳实践问题. 大家都知道,聚合根.实体和值对象这些领域对象都自身处理自己的业务逻辑.在业务处理过 ...
- [转帖]12条用于Linux的MySQL/MariaDB安全最佳实践
12条用于Linux的MySQL/MariaDB安全最佳实践 2018-01-04 11:05:56作者:凉凉_,soaring稿源:开源中国社区 https://ywnz.com/linuxysjk ...
- MySQL面试必考知识点:揭秘亿级高并发数据库调优与最佳实践法则
做业务,要懂基本的SQL语句: 做性能优化,要懂索引,懂引擎: 做分库分表,要懂主从,懂读写分离... 数据库的使用,是开发人员的基本功,对它掌握越清晰越深入,你能做的事情就越多. 今天我们用10分钟 ...
- 【大数据和云计算技术社区】分库分表技术演进&最佳实践笔记
1.需求背景 移动互联网时代,海量的用户每天产生海量的数量,这些海量数据远不是一张表能Hold住的.比如 用户表:支付宝8亿,微信10亿.CITIC对公140万,对私8700万. 订单表:美团每天几千 ...
- [转]10分钟梳理MySQL知识点:揭秘亿级高并发数据库调优与最佳实践法则
转:https://mp.weixin.qq.com/s/RYIiHAHHStIMftQT6lQSgA 做业务,要懂基本的SQL语句: 做性能优化,要懂索引,懂引擎: 做分库分表,要懂主从,懂读写分离 ...
随机推荐
- C语言使用dlfcn动态载入.so动态库
转载:https://mp.weixin.qq.com/s?__biz=Mzk0NDYzNTI1Ng==&mid=2247483722&idx=1&sn=09a9458b012 ...
- Quartz.Net系列(八):Trigger之CalendarIntervalScheduleBuilder详解
所有方法图 CalendarIntervalScheduleBuilder方法 在SimpleScheduleBuilder基础上实现了日.周.月.年 WithInterval:指定要生成触发器的时间 ...
- 什么是全场景AI计算框架MindSpore?
摘要:MindSpore是华为公司推出的新一代深度学习框架,是源于全产业的最佳实践,最佳匹配昇腾处理器算力,支持终端.边缘.云全场景灵活部署,开创全新的AI编程范式,降低AI开发门槛. MindSpo ...
- 使用Mask R-CNN模型实现人体关键节点标注
摘要:在本案例中,我们将展示如何对基础的Mask R-CNN进行扩展,完成人体关键节点标注的任务. 本文分享自华为云社区<使用Mask R-CNN模型实现人体关键节点标注>,作者: 运气男 ...
- 冠军斩获10万奖金!首届“域见杯”医检AI开发者大赛精彩落幕
摘要:首届"域见杯"医检AI开发者大赛精彩落幕. 8月24日,由广州市科学技术局指导,金域医学和华为云共同打造的中国第三方医检行业首个开发者大赛--"域见杯"医 ...
- 有了这个告警系统,DBA提前预警不是难题
摘要:告警功能是各大云平台必不可少的模块,个性化的告警配置,为帮助用户和运维人员及时发现问题发挥着重要作用. 本文分享自华为云社区<GaussDB(DWS) 数据库智能监控系统告警框架上线啦!& ...
- 讲透学烂二叉树(三):二叉树的遍历图解算法步骤及JS代码
二叉树的遍历是指不重复地访问二叉树中所有结点,主要指非空二叉树,对于空二叉树则结束返回. 二叉树的遍历分为 深度优先遍历 先序遍历:根节点->左子树->右子树(根左右),有的叫:前序遍历 ...
- JVM HotSpot 可达性分析算法实现细节
本文部分摘自<深入理解 Java 虚拟机第三版> 根节点枚举 在之前关于可达性分析算法的介绍中我们讲过,我们需要先找出可固定作为 GC Roots 的节点,然后沿着引用链去寻找那些无用的垃 ...
- XShell、XFtp免费许可证增强:删除标签限制!
大家好,我是DD! XShell相信大家都不陌生了,作为Windows平台下最强大的SSH工具,是大部分开发者的必备工具.但由于免费许可证的标签限制,有不少开发者会去找破解版使用.虽然功能是可以使用了 ...
- 【3rd_Party】format() 处理一些常见的格式化解决方案
fmt的痛与对format设计的思考 fmt:轻量高性能的C++格式化库 C++20 引入了新的 format() 函数,该函数以字符串形式返回参数的格式化表示.format() 使用 python ...