Huffman编码和解码
一.Huffman树
定义: 给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径达到最小,这样的二叉树称为最优二叉树,也称为霍夫曼树(Huffman树).
特点: Huffman树是带权路径长度最短的树,权值较大的节点离根节点较近
权值 = 当前节点的值 * 层数,wpl最小的值,就是Huffman树
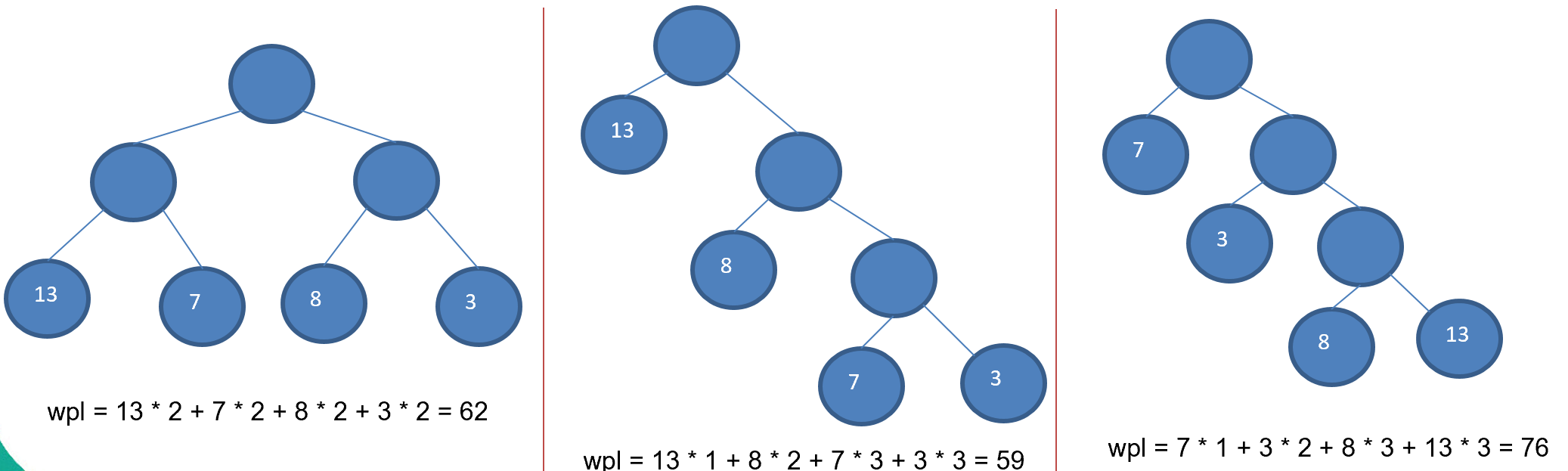
创建步骤 举例 {13,7,8,3,29,6,1}
1.从小到大进行排序,将每一个数据视为一个节点,每一个节点都可视为一个二叉树
2.取出根节点权值两个最小的二叉树
3.组成一个新的二叉树,新的二叉树根节点的权值是前面两颗二叉树节点权值之和
4.再将这颗二叉树以根节点的权值大小进行再排序,不断重复1,2,3,4步,直到所有的数据都被处理,就得到一个Huffman树
class Node implements Comparable<Node> {
// 实现Comparable接口,可以使用Collections工具类进行排序
public int value;
public Node left;
public Node right;
public Node(int value) {
this.value = value;
}
public Node() {
}
/*用于测试Huffman树是否正确*/
public void preOrder(){
System.out.println(this);
if (this.left != null){
this.left.preOrder();
}
if (this.right != null){
this.right.preOrder();
}
}
@Override
public String toString() {
return "Node{" +
"value=" + value +
'}';
}
@Override
public int compareTo(Node o) { // 从小到大进行排序
return this.value - o.value;
}
}
/**
* 创建霍夫曼树
* @param array 原数组
* @return 创建好Huffman树的root节点
*/
public static Node createHuffmanTree(int[] array){
if (array.length == 0 || array == null){
System.out.println("数组为空,无法创建");
return null;
}
/*遍历数组中的每一个元素,构造成Node,放入到List中*/
List<Node> nodes = new ArrayList<>();
for (int item : array) {
nodes.add(new Node(item));
} while (nodes.size() > 1){ /*只要List中有元素,就一直进行权值计算*/
/*对Node进行排序*/
Collections.sort(nodes); /*取出根节点两个权值最小的二叉树*/
Node leftNode = nodes.get(0);
Node rightNode = nodes.get(1); /*构建一个新的二叉树*/
Node parent = new Node(leftNode.value + rightNode.value);
parent.left = leftNode;
parent.right = rightNode; /*从List中删除使用过的节点*/
nodes.remove(leftNode);
nodes.remove(rightNode);
/*将新的节点加入到List中*/
nodes.add(parent);
}
/*返回Huffman树的root节点*/
return nodes.get(0);
}
}
测试,如果生成的Huffman树是正确的,那么前序遍历的结果也是正确的
public static void main(String[] args) {
int[] array = {13,7,8,3,29,6,1};
preOrder(createHuffmanTree(array));
}
public static void preOrder(Node root){
if (root != null){
root.preOrder();
}else {
System.out.println("该树为空,不能遍历");
return;
}
}

二.Huffman编码
定义: Huffman编码是一种通信的编码,是在电通信领域的基本编码之一
作用: Huffman编码广泛的应用于数据文件的压缩,而且它是前缀编码,可以有效的节省传输的带宽
编码的步骤: 举例 String content = 'i like like like java do you like a java oh oh oh';
1.生成节点
/*定义节点,data用于存放数据,weight用于存放权值*/
class HuffmanNode implements Comparable<HuffmanNode>{
public Byte data;
public int weight;
public HuffmanNode left;
public HuffmanNode right; public HuffmanNode(Byte data, int weight) {
this.data = data;
this.weight = weight;
} public HuffmanNode() {
} @Override
public int compareTo(HuffmanNode o) {
return this.weight - o.weight;
} }
2.统计字符串中每一个字符出现的次数
/*统计字符串中每个字符出现的次数,放在List中进行返回*/
/*List存储格式 [Node[date=97 ,weight = 5], Node[date=32,weight = 9]......]*/
public static List<HuffmanNode> getNodes(byte[] bytes){
if (bytes.length == 0 || bytes == null){
System.out.println("字符串为空,无法进行编码");
return null;
}
List<HuffmanNode> nodes = new ArrayList<>();
Map<Byte,Integer> counts = new HashMap<>();
/*遍历bytes ,统计每一个byte出现的次数*/
for (byte item : bytes) {
Integer count = counts.get(item);
if (count == null){ // Map中没有这个字符,说明是第一次
counts.put(item,1);
}else {
counts.put(item,count+1);
}
}
/*遍历Map,将键值对转换为Node对象进行存放到List中*/
for (Map.Entry<Byte,Integer> node:counts.entrySet()){
nodes.add(new HuffmanNode(node.getKey(),node.getValue()));
}
return nodes;
}
3.根据List集合,创建Huffm树
public static HuffmanNode createHuffmanTree(List<HuffmanNode> nodes){
if (nodes.size() == 0 || nodes == null){
System.out.println("生成的List为空,不能生成霍夫曼树");
return null;
}
while (nodes.size() > 1){
Collections.sort(nodes);
HuffmanNode leftNode = nodes.get(0);
HuffmanNode rightNode = nodes.get(1);
HuffmanNode parent = new HuffmanNode(null,leftNode.weight+rightNode.weight);
parent.left = leftNode;
parent.right = rightNode;
nodes.remove(leftNode);
nodes.remove(rightNode);
nodes.add(parent);
}
return nodes.get(0);
}
4.将传入的Huffman树进行Huffman编码
/*将传入所有节点的Node节点的Huffman编码得到*/
/*node 传入的节点*/
/*code 路径,向左为0,向右为1*/
/*StringBuild 用于拼接路径,生成编码*/
public static void getCode(HuffmanNode node,String code,StringBuilder stringBuilder){
StringBuilder stringBuilder2 = new StringBuilder(stringBuilder);
/*将code加入到stringBuilder2 中*/
stringBuilder2.append(code);
if (node!=null){ // 如果node是null,则不进行处理
if (node.data == null){ // 是非叶子节点
//向左递归
getCode(node.left,"0",stringBuilder2);
//向右递归
getCode(node.right,"1",stringBuilder2);
}else { /*此时表明是叶子结点,说明找到了一条路径的最后*/
huffmanCode.put(node.data,stringBuilder2.toString());
}
}
} /*方便调用,重载此方法*/
public static Map<Byte,String> getCode(HuffmanNode root){
if (root == null){
System.out.println("没有生成霍夫曼树");
return null;
}else {
/*处理root左子树*/
getCode(root.left,"0",stringBuilder);
/*处理root右子树*/
getCode(root.right,"1",stringBuilder);
}
return huffmanCode;
}
5.使用Huffman编码进行压缩
/*将字符串对应的byte数组,通过生成的Huffman编码表,返回一个Huffman编码压缩后的byte数组*/
/*bytes 原始字符串对应的字节数组*/
/*huffmanCode 生成的Huffman编码表*/
/* 返回Huffman编码处理后的字节数组*/
public static byte[] zip(byte[] bytes,Map<Byte,String> huffmanCode){
if (bytes.length == 0 || bytes == null){
System.out.println("字符串为空,无法进行编码");
return null;
}
/*1.根据HuffmanCode获取原始的字节数组的二进制的字符串*/
StringBuilder stb = new StringBuilder();
for (byte b : bytes) {
stb.append(huffmanCode.get(b));
}
/*2.创建存储压缩后的字节数组*/
int index = 0; //记录第几个byte
int len = 0; // 确定霍夫曼编码的长度
if (stb.length() % 8 == 0){
len = stb.length() / 8;
}else {
len = stb.length() / 8 + 1;
}
byte[] huffmanCodeBytes = new byte[len];
/*每8位对应一个byte,所以步长+8*/
for (int i = 0; i < stb.length();i+=8){
String strByte = null;
if (i+8 > stb.length()){ // 不够8位,直接从当前截取到末尾
strByte = stb.substring(i);
}else {
strByte = stb.substring(i,i+8); //否则按照每8位进行拼接
}
/*将strByte 转换成一个个byte,放在要返回的字节数组中,进行返回*/
huffmanCodeBytes[index++] = (byte)Integer.parseInt(strByte,2);
}
return huffmanCodeBytes;
}
查看编码的结果: 压缩率 (49-21) / 49 = 57.14%

压缩之后的字节数组是:
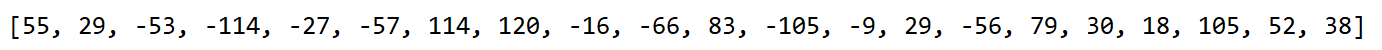
将上述Huffman编码的步骤封装
public static byte[] getZip(byte[] bytes){
List<HuffmanNode> nodes = getNodes(bytes);
// 根据nodes创建赫夫曼树
HuffmanNode root = createHuffmanTree(nodes);
// 根据root节点生成霍夫曼编码
huffmanCode = getCode(root);
// 根据霍夫曼编码,对数据进行压缩,得到字节数组
byte[] huffmanCodeBytes = zip(bytes,huffmanCode);
// System.out.println(Arrays.toString(huffmanCodeBytes));
return huffmanCodeBytes;
}
三.使用Huffman进行解码
1.将一个二进制的byte,装换为二进制的字符串
/**
* 将一个byte转换成二进制的字符串
* @param flag 表示是否要进行补高位,如果是true则需要补高位,false则不需要补位,如果是最后一个字节不需要补高位
* @param b
* @return 是该byte对应的二进制字符串(补码返回)
*/
public static String byteToBitString(boolean flag,byte b){
int temp = b; /* 使用临时变量,将byte转换为int*/
if (flag){ /*如果是一个正数,需要进行补位操作*/
temp |= 256; /*按位与操作*/
}
String str = Integer.toBinaryString(temp); /*返回temp对应的二进制补码*/
if (flag){ // 如果有8位,则按照8位来返回,否则直接返回字符串
return str.substring(str.length()-8);
}else {
return str;
}
}
2.解码操作
/**
*
* @param huffmanCode 对应霍夫曼编码表
* @param huffmanBytes 霍夫曼编码得到的字节数组
* @return 原先字符串对应的字节数组
*/
public static byte[] decode(Map<Byte,String> huffmanCode,byte[] huffmanBytes){
/*1.先得到HuffmanBytes对应的二进制的字符串*/
StringBuilder sbt = new StringBuilder();
//将byte字节转换为二进制字符串
for (int i = 0; i < huffmanBytes.length; i++) {
byte b = huffmanBytes[i];
// 判断是否是最后一个字节
boolean flag = (i == huffmanBytes.length-1);
sbt.append(byteToBitString(!flag,b));
} /*2.把字符串按照指定的方式进行霍夫曼解码*/
/*把Huffman码表进行调换,因为是反向查询*/
Map<String,Byte> map = new HashMap<>();
for (Map.Entry<Byte,String> entry:huffmanCode.entrySet()){
map.put(entry.getValue(),entry.getKey());
} /*3.创建集合,存放解码后的byte*/
List<Byte> byteList = new ArrayList<>();
/*使用索引不停的扫描stb*/
for (int k = 0; k < sbt.length();){
int count = 1; /*小的计数器,用于判断是否字符串是否在Huffman的码标中*/
Byte b = null; /*用于存放编码后的字节*/
boolean loop = true;
while (loop){
/*k不动,让count进行移动,指定匹配到一个字符*/
String key = sbt.substring(k,k+count);
b = map.get(key);
if (b == null){ //没有匹配到
count++;
}else {
//匹配到就退出循环
loop = false;
}
}
byteList.add(b);
k += count; //k直接移动到count在进行下一次遍历
} /*4.当for循环结束后,将list中存放的数据放入到byte数组中返回即可*/
byte[] decodeByteCodes = new byte[byteList.size()];
for (int j = 0; j < decodeByteCodes.length; j++) {
decodeByteCodes[j] = byteList.get(j);
}
return decodeByteCodes;
}
查看解码后的结果:

完整代码
package data.structer.tree;
import java.util.*;
public class HuffmanCodeDemo {
static Map<Byte,String> huffmanCode = new HashMap<>();
static StringBuilder stringBuilder = new StringBuilder();
public static void main(String[] args) {
String content = "i like like like java do you like a java oh oh oh";
//System.out.println("原始的长度是:"+content.length());
byte[] bytes = getZip(content.getBytes());
// System.out.println("Huffman编码后的字符串长度是:"+bytes.length);
System.out.println("解码后的字符串是:"+new String(decode(huffmanCode,bytes)));
}
// 解码
/**
*
* @param huffmanCode 对应霍夫曼编码表
* @param huffmanBytes 霍夫曼编码得到的字节数组
* @return
*/
public static byte[] decode(Map<Byte,String> huffmanCode,byte[] huffmanBytes){
StringBuilder sbt = new StringBuilder();
//将byte字节转换为二进制字符串
for (int i = 0; i < huffmanBytes.length; i++) {
byte b = huffmanBytes[i];
// 判断是否是最后一个字节
boolean flag = (i == huffmanBytes.length-1);
sbt.append(byteToBitString(!flag,b));
}
//把字符串按照指定的方式进行霍夫曼解码
Map<String,Byte> map = new HashMap<>();
for (Map.Entry<Byte,String> entry:huffmanCode.entrySet()){
map.put(entry.getValue(),entry.getKey());
}
// 创建集合,存放byte
List<Byte> byteList = new ArrayList<>();
for (int k = 0; k < sbt.length();){
int count = 1;
Byte b = null;
boolean loop = true;
while (loop){
String key = sbt.substring(k,k+count);
b = map.get(key);
if (b == null){ //没有匹配到
count++;
}else {
loop = false;
}
}
byteList.add(b);
k += count;
}
byte[] decodeByteCodes = new byte[byteList.size()];
for (int j = 0; j < decodeByteCodes.length; j++) {
decodeByteCodes[j] = byteList.get(j);
}
return decodeByteCodes;
}
/**
* 将一个byte转换成二进制的字符串
* @param flag 表示是否要进行补高位,如果是true则需要补高位,false则不需要补位,如果是最后一个字节不需要补高位
* @param b
* @return 是该byte对应的二进制字符串(补码返回)
*/
public static String byteToBitString(boolean flag,byte b){
int temp = b;
if (flag){
temp |= 256;
}
String str = Integer.toBinaryString(temp);
if (flag){
return str.substring(str.length()-8);
}else {
return str;
}
}
public static byte[] getZip(byte[] bytes){
List<HuffmanNode> nodes = getNodes(bytes);
// 根据nodes创建赫夫曼树
HuffmanNode root = createHuffmanTree(nodes);
// 根据root节点生成霍夫曼编码
huffmanCode = getCode(root);
// 根据霍夫曼编码,对数据进行压缩,得到字节数组
byte[] huffmanCodeBytes = zip(bytes,huffmanCode);
// System.out.println(Arrays.toString(huffmanCodeBytes));
return huffmanCodeBytes;
}
/**
* 统计字符串中每个字符出现的次数,添加到List中进行返回
* @param bytes
* @return
*/
public static List<HuffmanNode> getNodes(byte[] bytes){
if (bytes.length == 0 || bytes == null){
System.out.println("字符串为空,无法进行编码");
return null;
}
List<HuffmanNode> nodes = new ArrayList<>();
Map<Byte,Integer> counts = new HashMap<>();
for (byte item : bytes) {
Integer count = counts.get(item);
if (count == null){ // 说明是第一次
counts.put(item,1);
}else {
counts.put(item,count+1);
}
}
for (Map.Entry<Byte,Integer> node:counts.entrySet()){
nodes.add(new HuffmanNode(node.getKey(),node.getValue()));
}
return nodes;
}
/**
* 使用霍夫曼编码进行压缩
* @param bytes
* @param huffmanCode
* @return
*/
public static byte[] zip(byte[] bytes,Map<Byte,String> huffmanCode){
if (bytes.length == 0 || bytes == null){
System.out.println("字符串为空,无法进行编码");
return null;
}
StringBuilder stb = new StringBuilder();
for (byte b : bytes) {
stb.append(huffmanCode.get(b));
}
int index = 0;
int len = 0; // 确定霍夫曼编码的长度
if (stb.length() % 8 == 0){
len = stb.length() / 8;
}else {
len = stb.length() / 8 + 1;
}
byte[] huffmanCodeBytes = new byte[len];
for (int i = 0; i < stb.length();i+=8){
String strByte = null;
if (i+8 > stb.length()){ // 不够8位
strByte = stb.substring(i);
}else {
strByte = stb.substring(i,i+8);
}
huffmanCodeBytes[index] = (byte)Integer.parseInt(strByte,2);
index++;
}
return huffmanCodeBytes;
}
public static void getCode(HuffmanNode node,String code,StringBuilder stringBuilder){
StringBuilder stringBuilder2 = new StringBuilder(stringBuilder);
stringBuilder2.append(code);
if (node!=null){
if (node.data == null){ // 是非叶子节点
//向左递归
getCode(node.left,"0",stringBuilder2);
//向右递归
getCode(node.right,"1",stringBuilder2);
}else {
huffmanCode.put(node.data,stringBuilder2.toString());
}
}
}
public static Map<Byte,String> getCode(HuffmanNode root){
if (root == null){
System.out.println("没有生成霍夫曼树");
return null;
}else {
getCode(root.left,"0",stringBuilder);
getCode(root.right,"1",stringBuilder);
}
return huffmanCode;
}
/**
* 生成霍夫曼树
* @param nodes
* @return
*/
public static HuffmanNode createHuffmanTree(List<HuffmanNode> nodes){
if (nodes.size() == 0 || nodes == null){
System.out.println("生成的List为空,不能生成霍夫曼树");
return null;
}
while (nodes.size() > 1){
Collections.sort(nodes);
HuffmanNode leftNode = nodes.get(0);
HuffmanNode rightNode = nodes.get(1);
HuffmanNode parent = new HuffmanNode(null,leftNode.weight+rightNode.weight);
parent.left = leftNode;
parent.right = rightNode;
nodes.remove(leftNode);
nodes.remove(rightNode);
nodes.add(parent);
}
return nodes.get(0);
}
}
class HuffmanNode implements Comparable<HuffmanNode>{
public Byte data;
public int weight;
public HuffmanNode left;
public HuffmanNode right;
public HuffmanNode(Byte data, int weight) {
this.data = data;
this.weight = weight;
}
public HuffmanNode() {
}
@Override
public String toString() {
return "HuffmanNode{" +
"data=" + data +
", weight=" + weight +
'}';
}
@Override
public int compareTo(HuffmanNode o) {
return this.weight - o.weight;
}
}
Huffman编码和解码的更多相关文章
- DS二叉树--Huffman编码与解码
题目描述 1.问题描述 给定n个字符及其对应的权值,构造Huffman树,并进行huffman编码和译(解)码. 构造Huffman树时,要求左子树根的权值小于.等于右子树根的权值. 进行Huffma ...
- 用C++实现Huffman文件编码和解码(2 总结)
这个是代码是昨天写完的,一开始的时候还出了点小bug,这个bug在晚上去吃饭的路上想明白的,回来更改之后运行立刻完成最后一步,大获成功. 简单说下huffman编码和文件压缩主要的技术. Huffma ...
- Huffman 编码压缩算法
前两天发布那个rsync算法后,想看看数据压缩的算法,知道一个经典的压缩算法Huffman算法.相信大家应该听说过 David Huffman 和他的压缩算法—— Huffman Code,一种通过字 ...
- [转载]Huffman编码压缩算法
转自http://coolshell.cn/articles/7459.html 前两天发布那个rsync算法后,想看看数据压缩的算法,知道一个经典的压缩算法Huffman算法.相信大家应该听说过 D ...
- [老文章搬家] 关于 Huffman 编码
按:去年接手一个项目,涉及到一个一个叫做Mxpeg的非主流视频编码格式,编解码器是厂商以源代码形式提供的,但是可能代码写的不算健壮,以至于我们tcp直连设备很正常,但是经过一个UDP数据分发服务器之后 ...
- Jcompress: 一款基于huffman编码和最小堆的压缩、解压缩小程序
前言 最近基于huffman编码和最小堆排序算法实现了一个压缩.解压缩的小程序.其源代码已经上传到github上面: Jcompress下载地址 .在本人的github上面有一个叫Utility的re ...
- Huffman编码实现文件的压缩与解压缩。
以前没事的时候写的,c++写的,原理很简单,代码如下: #include <cstdio> #include <cstdlib> #include <iostream&g ...
- Huffman编码实现压缩解压缩
这是我们的课程中布置的作业.找一些资料将作业完毕,顺便将其写到博客,以后看起来也方便. 原理介绍 什么是Huffman压缩 Huffman( 哈夫曼 ) 算法在上世纪五十年代初提出来了,它是一种无损压 ...
- java编码原理,java编码和解码问题
java的编码方式原理 java的JVM的缺省编码方式由系统的“本地语言环境”设置确定,和操作系统的类型无关 . 在JAVA源文件-->JAVAC-->Class-->Java--& ...
随机推荐
- IntelliJ IDEA的常用设置及快捷键
IntelliJ IDEA的常用设置及快捷键 基本设置 打开设置:ctrl+alt+s 修改主题.字体.字号 快捷键设置 创建项目和模块 标记源码文件 标记资源文件 设置jdk版本号 配置Tomcat ...
- 浅谈 OpenGL 中相关阻塞问题
昨天我遇到一个问题,问题如下: 我使用了延迟渲染,我的渲染流程是:Pass1 --> CUDA并行计算 -->Pass2 CUDA并行计算中需要使用Pass1渲染生成的两张纹理,然而我在G ...
- spark(1.1) mllib 源码分析(三)-决策树
本文主要以mllib 1.1版本为基础,分析决策树的基本原理与源码 一.基本原理 二.源码分析 1.决策树构造 指定决策树训练数据集与策略(Strategy)通过train函数就能得到决策树模型Dec ...
- [转]C#中的abstract 类和方法
转:https://www.cnblogs.com/zzy2740/archive/2005/09/20/240808.html C#中的abstract类不能被实例化,他只提供其他类的继承的接口 u ...
- C# 微信h5支付
相关文档 https://pay.weixin.qq.com/wiki/doc/api/H5.php?chapter=9_20&index=1 需要准备 公众号ID.商户号.商家私钥 1.登 ...
- Netty快速入门(09)channel组件介绍
书接上回,继续介绍组件. ChannelHandler组件介绍 ChannelHandler组件包含了业务处理核心逻辑,是由用户自定义的内容,开发人员百分之九十的代码都是ChannelHandler. ...
- 【转】ArcGIS Server 站点架构-Web Adaptor
GIS 服务器内置了Web服务器,如果我想用我自己企业内部的服务器,该怎么做? 多个GIS服务器集群又如何做? …… 有问题,说明我们在思考,这也是我们希望看到的,因为只有不断的思考,不断的问自己为什 ...
- FNScanner二维码接口openView自定义扫码Demo
本文出自APICloud官方论坛 FNScanner 模块是一个二维码/条形码扫描器,是 scanner 模块的优化升级版.在 iOS 平台上本模块底层集成了 Zbar 和系统自带的条形码/二维码分析 ...
- bzoj1597: [Usaco2008 Mar]土地购买 dp斜率优化
东风吹战鼓擂第一题土地购买送温暖 ★★★ 输入文件:acquire.in 输出文件:acquire.out 简单对比时间限制:1 s 内存限制:128 MB 农夫John准备扩大他的农 ...
- Spring-cloud微服务实战【二】:eureka注册中心(上)
## 前言 本系列教程旨在为大家演示如何一步一步构建一整套微服务系统,至于其中的数据库用什么,订单ID如何保持唯一,分布式相关问题等等不在我们讨论范围内,本教程为了方便大家后续下载代码运行测试,不 ...