Elasticsearch调优篇-慢查询分析笔记
前言
- elasticsearch提供了非常灵活的搜索条件给我们使用,在使用复杂表达式的同时,如果使用不当,可能也会为我们带来了潜在的风险,因为影响查询性能的因素很多很多,这篇笔记主要记录一下慢查询可能的原因,及其优化的方向。
- 本文讨论的es版本为7.0+。
慢查询现象
查询服务超时
- 最直观的现象就是提供查询的服务响应超时。
大量连接被拒绝
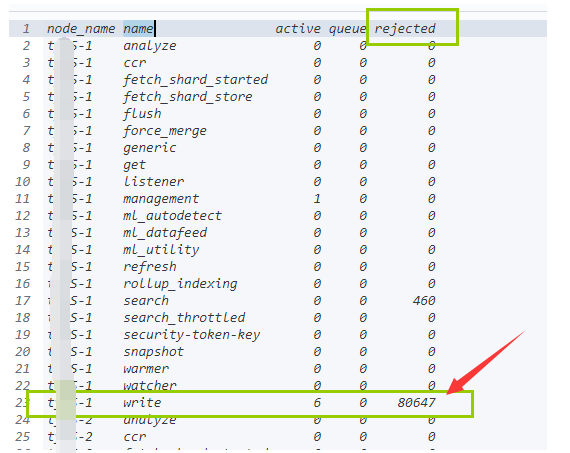
- 我们有时候写查询,为了图方遍,经常使用通配符*来查询,这有可能会匹配到多个索引,由于索引下分片太多,超过了集群中的核心数。就会在搜索线程池中造成排队任务,从而导致搜索拒绝。
查询延迟
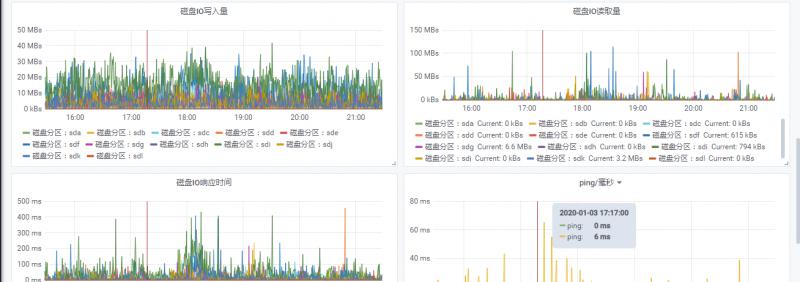
主机CPU飙高
- 另一个常见原因是磁盘 I/O 速度慢,导致搜索排队或在某些情况下 CPU 完全饱和。
- 除了文件系统缓存,Elasticsearch 还使用查询缓存和请求缓存来提高搜索速度。 所有这些缓存都可以使用搜索请求进行优化,以便每次都将某些搜索请求路由到同一组分片,而不是在不同的可用副本之间进行交替。这将更好地利用请求缓存、节点查询缓存和文件系统缓存。Es默认会在内存使用75%时发生FullGC ,做好主机和节点的监控同样重要。

优化方法
根据查询时间段动态计算索引
- elasticsearch支持同时查询多个索引,为了提高查询效率,避免使用通配符查询,我们可以计算枚举出所有的目标索引,一般es的数据都是按时间分索引,我们可以根据前端传入的时间段,计算出目标索引。
控制分片数量
- 分片的数量和节点和内存有一定的关系。
- 最理想的分片数量应该依赖于节点的数量。 数量是节点数量的1.5到3倍。
- 每个节点上可以存储的分片数量,和堆内存成正比。官方推荐:1GB 的内存,分片配置最好不要超过20。
注意from/to查询带来的深度分页问题
- 举例假如每页为 10 条数据,你现在要查询第 200 页,实际上是会把每个 Shard 上存储的前 2000条数据都查到一个协调节点上。
如果你有 5 个 分片,那么就有 10000 条数据,接着协调节点对这 10000 条数据进行一些合并、处理,再获取到最终第 200 页的 10 条数据。实在需要查询很多数据,可以使用scroll API 滚动查询。
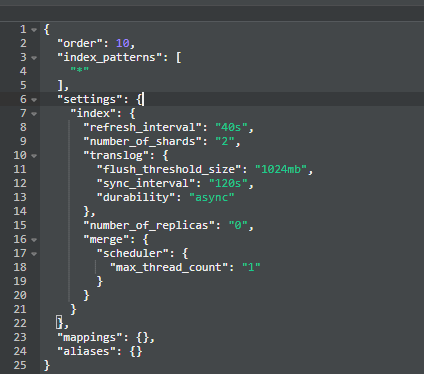
为你的索引配置索引模板
- 在低版本的es中默认的分片是5个,在高版本中改成了1,我们需要根据索引的索引量来动态调整分片数量,这里推荐设置一个默认匹配规则,将优先级设置高一些(ps:order高的会覆盖order低的模板),避免查询扫描过多的分片,合理利用集群资源。
避免数据分桶太多
对于分桶数量太大的聚合请求,应该将所有数据切片,比如按时间分片,多次请求,来提高查询效率,并且避免内存OOM。
独立协调节点
- 集群中应该有独立的协调节点,专门用于数据请求(node.master=false node.data=false),并给它们设置足够的内存。通过数据节点与协调节点分离,可以避免节点挂掉之后,导致整个集群不可用,或者长时间响应迟钝。
Routing数据路由
适当的增加刷新间隔
- es是一个准实时的搜索框架,这就意味着,从索引一个文档直到文档能够被搜索到有一个轻微的延迟,也就是 index.refresh_ interval ,默认值是1秒,适当的增加这个值,可以避免创建过多的segment(segment是最小的检索单元)。
配置慢查询日志
- 通过在 Elasticsearch 中启用 slowlogs 来识别运行缓慢的查询。slowlogs 专门用于分片级别,仅适用于数据节点。协调/客户端节点不具备慢日志分析功能,因为它们不保存数据。通过它,我们可以在日志中看到,那个查询语句耗时长,从而制定优化措施。
index.search.slowlog.threshold.query.warn: 10s
index.search.slowlog.threshold.query.info: 5s
index.search.slowlog.threshold.query.debug: 2s
index.search.slowlog.threshold.query.trace: 500ms
index.search.slowlog.threshold.fetch.warn: 1s
index.search.slowlog.threshold.fetch.info: 800ms
index.search.slowlog.threshold.fetch.debug: 500ms
index.search.slowlog.threshold.fetch.trace: 200ms
index.search.slowlog.level: info
配置熔断策略
- es7.0后版本提供一系列的断路器,用于防止操作引起OutOfMemoryError。每个断路器都指定了可以使用多少内存的限制。此外,还有一个父级断路器,用于指定可在所有断路器上使用的内存总量。
indices.breaker.request.limit:请求中断的限制,默认为JVM堆的60%。
indices.breaker.total.limit:总体父中断程序的启动限制,如果indices.breaker.total.use_real_memory为,则默认为JVM堆的70% false。如果indices.breaker.total.use_real_memory 为true,则默认为JVM堆的95%。
network.breaker.inflight requests.limit 限制当前通过HTTP等进来的请求使用内存不能超过Node内存的指定值。这个内存主要是限制请求内容的长度。 默认100%。
script.max_compilations_rate:在允许的时间间隔内限制动态脚本的并发执行数量。默认值为75 / 5m,即每5分钟75。
欢迎来公众号【侠梦的开发笔记】 一起交流进步
Elasticsearch调优篇-慢查询分析笔记的更多相关文章
- <JVM下篇:性能监控与调优篇>补充:使用OQL语言查询对象信息
笔记来源:尚硅谷JVM全套教程,百万播放,全网巅峰(宋红康详解java虚拟机) 同步更新:https://gitee.com/vectorx/NOTE_JVM https://codechina.cs ...
- 《Kafka权威指南》读书笔记-操作系统调优篇
<Kafka权威指南>读书笔记-操作系统调优篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 大部分Linux发行版默认的内核调优参数配置已经能够满足大多数应用程序的运 ...
- <JVM下篇:性能监控与调优篇>补充:浅堆深堆与内存泄露
笔记来源:尚硅谷JVM全套教程,百万播放,全网巅峰(宋红康详解java虚拟机) 同步更新:https://gitee.com/vectorx/NOTE_JVM https://codechina.cs ...
- <JVM下篇:性能监控与调优篇>01-概述篇-02-JVM监控及诊断工具-命令行篇
笔记来源:尚硅谷JVM全套教程,百万播放,全网巅峰(宋红康详解java虚拟机) 同步更新:https://gitee.com/vectorx/NOTE_JVM https://codechina.cs ...
- MySQL 数据库规范--调优篇(终结篇)
前言 这篇是MySQL 数据库规范的最后一篇--调优篇,旨在提供我们发现系统性能变弱.MySQL系统参数调优,SQL脚本出现问题的精准定位与调优方法. 目录 1.MySQL 调优金字塔理论 2.MyS ...
- 大数据集群Linux CentOS 7.6 系统调优篇
大数据集群Linux CentOS 7.6 系统调优篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.设置主机hosts文件 1>.修改主机名 [root@node100 ...
- <JVM下篇:性能监控与调优篇>03-JVM监控及诊断工具-GUI篇
笔记来源:尚硅谷JVM全套教程,百万播放,全网巅峰(宋红康详解java虚拟机) 同步更新:https://gitee.com/vectorx/NOTE_JVM https://codechina.cs ...
- linux系统性能调优第一步——性能分析(vmstat)
linux系统性能调优第一步--性能分析(vmstat) 分类: LINUX 性能调优的第一步是性能分析,下面从性能分析着手进行一些介绍,尤其对linux性能分析工具vmstat的用法和实践进行详细介 ...
- Android性能调优篇之探索垃圾回收机制
开篇废话 如果我们想要进行内存优化的工作,还是需要了解一下,但这一块的知识属于纯理论的,有可能看起来会有点枯燥,我尽量把这一篇的内容按照一定的逻辑来走一遍.首先,我们为什么要学习垃圾回收的机制,我大概 ...
随机推荐
- LA 4973 Ardenia (3D Geometry + Simulation)
ACM-ICPC Live Archive 三维几何,题意是要求求出两条空间线段的距离.题目难度在于要求用有理数的形式输出,这就要求写一个有理数类了. 开始的时候写出来的有理数类就各种疯狂乱套,TLE ...
- redux【react】
首先介绍一下redux就是Flux的一种进阶实现.它是一个应用数据流框架,主要作用应用状态的管理 一.设计思想: (1).web应用就是一个状态机,视图和状态一一对应 (2).所有的状态保存在一个对象 ...
- Python--day69--ORM正反向查找(外键)
ForeignKey操作 正向查找 对象查找(跨表) 语法: 对象.关联字段.字段 示例: book_obj = models.Book.objects.first() # 第一本书对象 prin ...
- [转]来自后端的逆袭 blazor简介 全栈的福音
背景 什么是SPA 什么是MPA MPA (Multi-page Application) 多页面应用指的就是最传统的 HTML 网页设计,早期的网站都是这样的设计,所之称为「网页设计」.使用 MPA ...
- H3C 寻找邻居
- laydate type=time/datetime/date 开始时间和结束时间的输入限制
最近项目中使用了laydate插件,需要限制开始时间和结束时间的输入 1.type=date 要求:周期开始时间和周期结束时间以天为单位,结束时间不能早于开始时间,可以是同一天. 周期开始时间:< ...
- HDU 2454"Degree Sequence of Graph G"(度序列可图性判断)
传送门 参考资料: [1]:图论-度序列可图性判断(Havel-Hakimi定理) •题意 给你 n 个非负整数列,判断这个序列是否为可简单图化的: •知识支持 握手定理:在任何无向图中,所有顶点的度 ...
- 安装 Sureface Hub 系统 Windows 10 team PPIPro 系统
本文告诉大家如何安装这个系统 本文的方法我自己没试过,如果失败了,不要打我 下载地址 中文版 https://pan.baidu.com/s/1gAJSSE6KB9JHXo4BT_VfmA 其他请看 ...
- RocketMQ(消息重发、重复消费、事务、消息模式)
分布式开放消息系统(RocketMQ)的原理与实践 RocketMQ基础:https://github.com/apache/rocketmq/tree/rocketmq-all-4.5.1/docs ...
- ASP.NET MVC 实现页落网资源分享网站+充值管理+后台管理(11)之支付管理及广告管理
源码下载地址:http://www.yealuo.com/Sccnn/Detail?KeyValue=c891ffae-7441-4afb-9a75-c5fe000e3d1c 本项目属于个人项目,不支 ...