mapduce简介
原文引自:http://www.cnblogs.com/shishanyuan/p/4639519.html
1、环境说明
部署节点操作系统为CentOS,防火墙和SElinux禁用,创建了一个shiyanlou用户并在系统根目录下创建/app目录,用于存放Hadoop等组件运行包。因为该目录用于安装hadoop等组件程序,用户对shiyanlou必须赋予rwx权限(一般做法是root用户在根目录下创建/app目录,并修改该目录拥有者为shiyanlou(chown –R shiyanlou:shiyanlou /app)。
Hadoop搭建环境:
l 虚拟机操作系统: CentOS6.6 64位,单核,1G内存
l JDK:1.7.0_55 64位
l Hadoop:1.1.2
2、MapReduce原理
2.1 MapReduce简介
MapReduce 是现今一个非常流行的分布式计算框架,它被设计用于并行计算海量数据。第一个提出该技术框架的是Google 公司,而Google 的灵感则来自于函数式编程语言,如LISP,Scheme,ML 等。MapReduce 框架的核心步骤主要分两部分:Map 和Reduce。当你向MapReduce 框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map 任务,然后分配到不同的节点上去执行,每一个Map 任务处理输入数据中的一部分,当Map 任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce 任务的输入数据。Reduce 任务的主要目标就是把前面若干个Map 的输出汇总到一起并输出。从高层抽象来看,MapReduce的数据流图如下图所示:
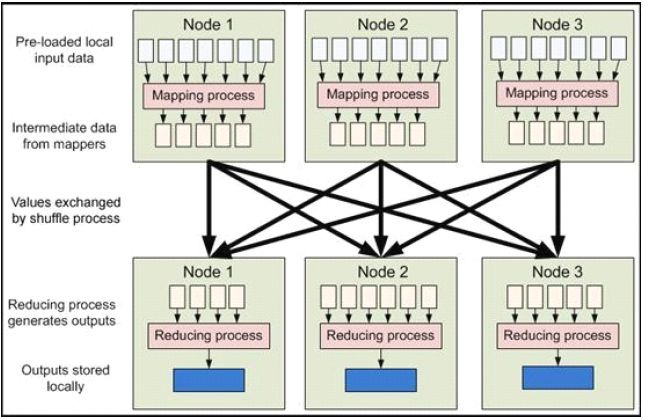
2.2 MapReduce流程分析
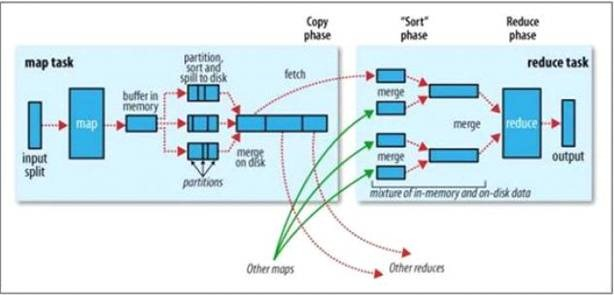
2.2.1 Map过程
1. 每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件;
2. 在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combia操作,这样做的目的是让尽可能少的数据写入到磁盘;
3. 当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combia操作,目的有两个:
l尽量减少每次写入磁盘的数据量
l尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了
4. 将分区中的数据拷贝给相对应的reduce任务。有人可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就可以了。
2.2.2 Reduce过程
1. Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中;
2. 随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作;
3. 合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。
2.3 MapReduce工作机制剖析
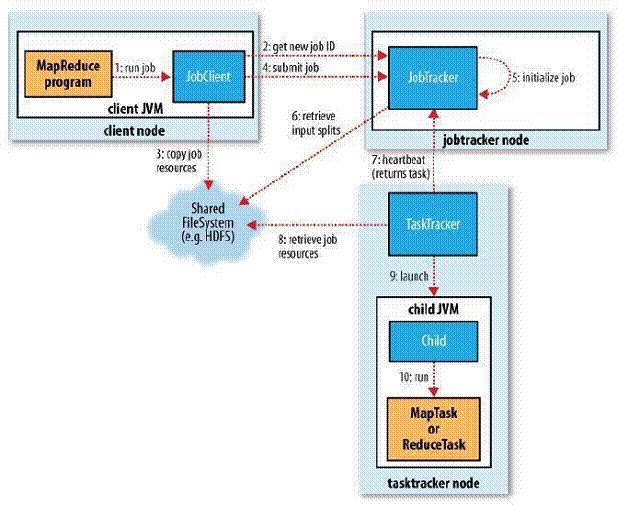
1.在集群中的任意一个节点提交MapReduce程序;
2.JobClient收到作业后,JobClient向JobTracker请求获取一个Job ID;
3.将运行作业所需要的资源文件复制到HDFS上(包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息),这些文件都存放在JobTracker专门为该作业创建的文件夹中,文件夹名为该作业的Job ID;
4.获得作业ID后,提交作业;
5.JobTracker接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度,当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行;
6.对于map和reduce任务,TaskTracker根据主机核的数量和内存的大小有固定数量的map槽和reduce槽。这里需要强调的是:map任务不是随随便便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”;
7.TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobClient查询状态时,它将得知任务已完成,便显示一条消息给用户;
8.运行的TaskTracker从HDFS中获取运行所需要的资源,这些资源包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分等信息;
9.TaskTracker获取资源后启动新的JVM虚拟机;
10. 运行每一个任务;
mapduce简介的更多相关文章
- ASP.NET Core 1.1 简介
ASP.NET Core 1.1 于2016年11月16日发布.这个版本包括许多伟大的新功能以及许多错误修复和一般的增强.这个版本包含了多个新的中间件组件.针对Windows的WebListener服 ...
- MVVM模式和在WPF中的实现(一)MVVM模式简介
MVVM模式解析和在WPF中的实现(一) MVVM模式简介 系列目录: MVVM模式解析和在WPF中的实现(一)MVVM模式简介 MVVM模式解析和在WPF中的实现(二)数据绑定 MVVM模式解析和在 ...
- Cassandra简介
在前面的一篇文章<图形数据库Neo4J简介>中,我们介绍了一种非常流行的图形数据库Neo4J的使用方法.而在本文中,我们将对另外一种类型的NoSQL数据库——Cassandra进行简单地介 ...
- REST简介
一说到REST,我想大家的第一反应就是“啊,就是那种前后台通信方式.”但是在要求详细讲述它所提出的各个约束,以及如何开始搭建REST服务时,却很少有人能够清晰地说出它到底是什么,需要遵守什么样的准则. ...
- Microservice架构模式简介
在2014年,Sam Newman,Martin Fowler在ThoughtWorks的一位同事,出版了一本新书<Building Microservices>.该书描述了如何按照Mic ...
- const,static,extern 简介
const,static,extern 简介 一.const与宏的区别: const简介:之前常用的字符串常量,一般是抽成宏,但是苹果不推荐我们抽成宏,推荐我们使用const常量. 执行时刻:宏是预编 ...
- HTTPS简介
一.简单总结 1.HTTPS概念总结 HTTPS 就是对HTTP进行了TLS或SSL加密. 应用层的HTTP协议通过传输层的TCP协议来传输,HTTPS 在 HTTP和 TCP中间加了一层TLS/SS ...
- 【Machine Learning】机器学习及其基础概念简介
机器学习及其基础概念简介 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- Cesium简介以及离线部署运行
Cesium简介 cesium是国外一个基于JavaScript编写的使用WebGL的地图引擎,一款开源3DGIS的js库.cesium支持3D,2D,2.5D形式的地图展示,可以自行绘制图形,高亮区 ...
随机推荐
- JS鼠标经过
<!DOCTYPE html><html><head> <meta charset="utf-8"> <title>菜鸟 ...
- Android开发 自定义View_白色圆型涟漪动画View
代码: import android.animation.ValueAnimator; import android.content.Context; import android.graphics. ...
- tomcat7 linux service
1. 创建tomcat用户 useradd -r -m -d /usr/local/tomcat7 -s /sbin/nologin tomcat 2. 将下面脚本命名为tomcat7 放入/etc/ ...
- EJB(Enterprise JavaBean)科普
该文章是引用的,主要用于自己的学习,然后是记载免得忘记的时候到处乱找.结尾有引用地址. 到底EJB是什么?被口口相传的神神秘秘的,百度一番,总觉得没有讲清楚的,仍觉得一头雾水.百度了很久,也从网络的文 ...
- [kuangbin带你飞]专题一 简单搜索 - A - 棋盘问题
#include<iostream> #include<cstdio> #include<string> #include<vector> #inclu ...
- 4_6.springboot2.xWeb开发之错误处理机制
1.SpringBoot默认的错误处理机制 默认效果:1).浏览器,返回一个默认的错误页面 浏览器发送请求的请求头: 2).如果是其他客户端,默认响应一个json数据 原理: 默认情况下,Sp ...
- Ubuntu环境下使用npm编译从git上clone下来的前端(Javascript)项目
一.更新Ubuntu软件源 打开终端依次输入: $ sudo apt-get update $ sudo apt-get install -y python-software-properties s ...
- php非法输入数据类型
1.空白输入 2.超长输入(如大于256个字符) 3.特殊字符(如·!@#¥%……&*()—=|.:‘:<>;'"<>?.,) 4.控制字符(如\r\n等) ...
- 踩坑记-java mysql 新增获取主键、DIY主键、UUID
java mysql 获取主键.DIY主键.UUID,简单粗暴,代码如下: mapper.xml insert id="add" parameterType="com.x ...
- https://webpack.js.org/plugins/
有问题还是看源码 ,看官方文档吧,整一晚上终于整明白了