SpringBoot使用ELK日志收集ELASTIC (ELK) STACK
1:资源
# 文档向导
# logstash
https://www.elastic.co/guide/en/logstash/current/index.html
#kibana
https://www.elastic.co/guide/en/kibana/current/index.html
#elasticsearch
https://www.elastic.co/guide/en/elasticsearch/current/index.html
# 资源下载
https://www.elastic.co/cn/downloads/elasticsearch
https://www.elastic.co/cn/downloads/kibana
https://www.elastic.co/cn/downloads/logstash
没有VPN的我这里提供最新版本的软件包:
链接:https://pan.baidu.com/s/1XtIL_6MJgn7vplILKG31_A
提取码:825n
2:安装ELK
安装ELK基本tar –xzvf 解压就行 这里给出关键配置
Kibana配置
conf文件夹下 kibana.yml
修改config/kibana.yml文件配置:
vim kibana.yml
kibana.yml常见配置项
# pingElasticsearch超时时间
elasticsearch.pingTimeout
# 读取Elasticsearch数据超时时间
elasticsearch.requestTimeout
#Elasticsearch主机地址
elasticsearch.url: "http://ip:9200"
# 允许远程访问
server.host: "0.0.0.0"
# Elasticsearch用户名 这里其实就是我在服务器启动Elasticsearch的用户名
elasticsearch.username: "es"
# Elasticsearch鉴权密码 这里其实就是我在服务器启动Elasticsearch的密码
elasticsearch.password: "es"
server.port: 5601
server.host: "127.0.0.1"
server.name: tanklog
elasticsearch.hosts: ["http://localhost:9200/"]
Logstash配置
logstash目录下 新建conf文件
input {
file {
path => ["/usr/local/logstash/logstash-tutorial-dataset"]
type => "syslog"
tags => ["有用的","标识用的"]
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}
3:启动配置
# 启动 elasticsearch
#>>> ./elasticsearch #访问 dgw@ubuntu:~$ curl -L http://localhost:9200/
{
"name" : "ubuntu",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "CqSWrvU8TLiw_haNYjB0Ow",
"version" : {
"number" : "7.6.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "7f634e9f44834fbc12724506cc1da681b0c3b1e3",
"build_date" : "2020-02-06T00:09:00.449973Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
# 启动 kibana
#>>> kibana-7.6.0-linux-x86_64/bin$ ./kibana
#访问 dgw@ubuntu:~$ curl -L http://localhost:5601/
# 启动 logstash
#>>> dgw@ubuntu:~/Documents/logstash/logstash-7.6.0/bin$ ./logstash -f ../config/logstash-my.conf
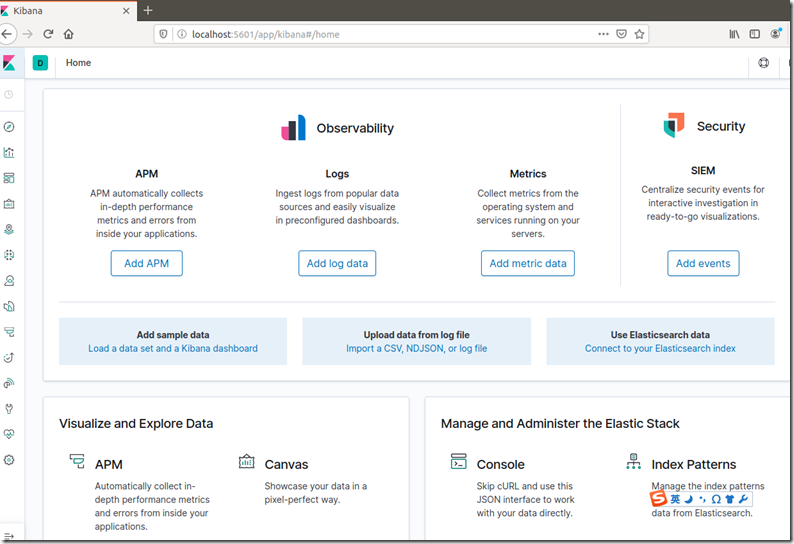
浏览器 http://localhost:5601/ 显示下面的画面即为成功
4:导入POM依赖
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>6.3</version>
</dependency>
5配置logstash
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/base.xml" /> <appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>127.0.0.1:4560</destination>
<!-- 日志输出编码 -->
<encoder charset="UTF-8"
class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"logLevel": "%level",
"serviceName": "${springAppName:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender> <root level="INFO">
<appender-ref ref="LOGSTASH" />
<appender-ref ref="CONSOLE" />
</root> </configuration>
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 4560
codec => json_lines
}
}
output {
elasticsearch {
hosts => "localhost:9200"
index => "springboot-logstash-%{+YYYY.MM.dd}"
}
}
6: 启动类设置输出信息
@SpringBootApplication
@RestController
public class SpringbootLogstashApplication { Logger logger = LoggerFactory.getLogger(SpringbootLogstashApplication.class); @GetMapping("test")
public void test(){
logger.info("测试初始一些日志吧!");
} public static void main(String[] args) {
SpringApplication.run(SpringbootLogstashApplication.class, args);
} }
7:测试
对maven 项目执行 mvn package 打包 得到 jar文件 拷贝到Linux下
dgw@ubuntu:~/Documents$ java -jar logstash-0.0.1-SNAPSHOT.jar
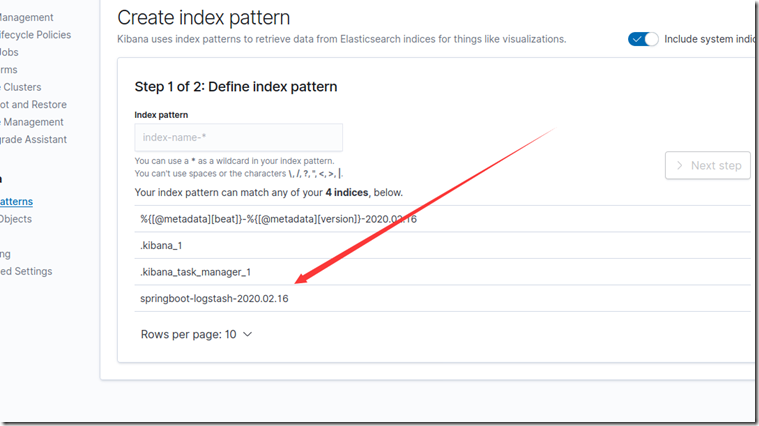
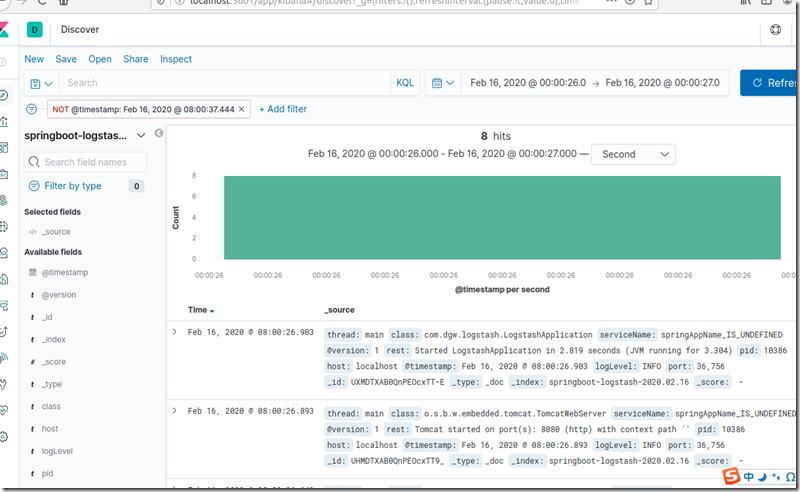
上面页面创建索引后, 在发现页面: 找到我们项目info
SpringBoot使用ELK日志收集ELASTIC (ELK) STACK的更多相关文章
- springboot 集成 elk 日志收集功能
Lilishop 技术栈 官方公众号 & 开源不易,如有帮助请点Star 介绍 官网:https://pickmall.cn Lilishop 是一款Java开发,基于SpringBoot研发 ...
- SpringBoot使用ELK日志收集
本文介绍SpringBoot应用配合ELK进行日志收集. 1.有关ELK 1.1 简介 在之前写过一篇文章介绍ELK日志收集方案,感兴趣的可以去看一看,点击这里-----> <ELK日志分 ...
- FILEBEAT+ELK日志收集平台搭建流程
filebeat+elk日志收集平台搭建流程 1. 整体简介: 模式:单机 平台:Linux - centos - 7 ELK:elasticsearch.logstash.kiban ...
- kubernetes-平台日志收集(ELK)
使用ELK Stack收集Kubernetes平台中日志与可视化 K8S系统的组件日志 K8S Cluster里面部署的应用程序日志 日志系统: ELK安装 安装jdk [root@localhost ...
- Linux下单机部署ELK日志收集、分析环境
一.ELK简介 ELK是elastic 公司旗下三款产品ElasticSearch .Logstash .Kibana的首字母组合,主要用于日志收集.分析与报表展示. ELK Stack包含:Elas ...
- ELK日志收集平台部署
需求背景 由于公司的后台服务有三台,每当后台服务运行异常,需要看日志排查错误的时候,都必须开启3个ssh窗口进行查看,研发们觉得很不方便,于是便有了统一日志收集与查看的需求. 这里,我用ELK集群,通 ...
- ELK日志收集分析平台 (Elasticsearch+Logstash+Kibana)使用说明
使用ELK对返回502的报警进行日志的收集汇总 eg:Server用户访问网站返回502 首先在zabbix上找到Server的IP 然后登录到elk上使用如下搜索条件: pool_select:X. ...
- 日志收集系统elk
目录 elk简介 官方帮助 rsyslog rsyslog日志采集介绍与使用 综合实验 案例一: 单机ELK部署 案例二. JAVA环境配置,部署 filebeat+Elasticsearch apa ...
- 日志收集系统ELK搭建
一.ELK简介 在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常低下.因此我们需要集中化的管理 ...
随机推荐
- java 多线程 快速入门
------------恢复内容开始------------ java 多线程 快速入门 1. 进程和线程 什么是进程? 进程是正在运行的程序它是线程的集合 进程中一定有一个主线程 一个操作系统可以有 ...
- 常见的sql注入环境搭建
常见的sql注入环境搭建 By : Mirror王宇阳 Time:2020-01-06 PHP+MySQL摘要 $conn = new mysqli('数据库服务器','username','pass ...
- elk日志使用
elasticsearch +log4net.ElasticSearch+kibana(windows) 需要的东西(目前用的5.6版本) 1.先安装jdk和jre 配置java环境 2. ...
- spring boot使用拦截器
1.编写一个拦截器 首先,我们先编写一个拦截器,和spring mvc方式一样.实现HandlerInterceptor类,代码如下 package com.example.demo.intercep ...
- BitSet 的使用
BitSet 的简单介绍 BitSet,即位图,是位操作的对象,值只有 0 或 1(即 false 或 true). Java 的 BitSet 内部维护着一个 long 数组,默认初始化时数组的长度 ...
- 使用内存映射文件MMF实现大数据量导出时的内存优化
前言 导出功能几乎是所有应用系统必不可少功能,今天我们来谈一谈,如何使用内存映射文件MMF进行内存优化,本文重点介绍使用方法,相关原理可以参考文末的连接 实现 我们以单次导出一个excel举例(csv ...
- 2、Vue实战-配置篇-npm配置
引言: 如果刚开始使用 vue 并不了解 nodejs.npm 相关知识可以看我上一篇的实践,快速入门了解实战知识树. Vue实战-入门篇 上篇反思: 1.新的关注点:开发 vue 模板.如何使用本地 ...
- k8s内运行ubuntu容器
k8s内运行ubuntu镜像 环境 互相能访问的4台机器master,node01,node02,node03,4核心,内存8G 使用root操作 安装k8s 在master安装docker.kube ...
- 【LC_Lesson5】---求最长的公共前缀
编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower","flow" ...
- 【LC_Lesson4】---罗马数字到整数得转换
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M. 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000例如, 罗马数字 2 写做 II ,即为两个并列 ...