SparkStreaming个人记录
一、SparkStreaming概述
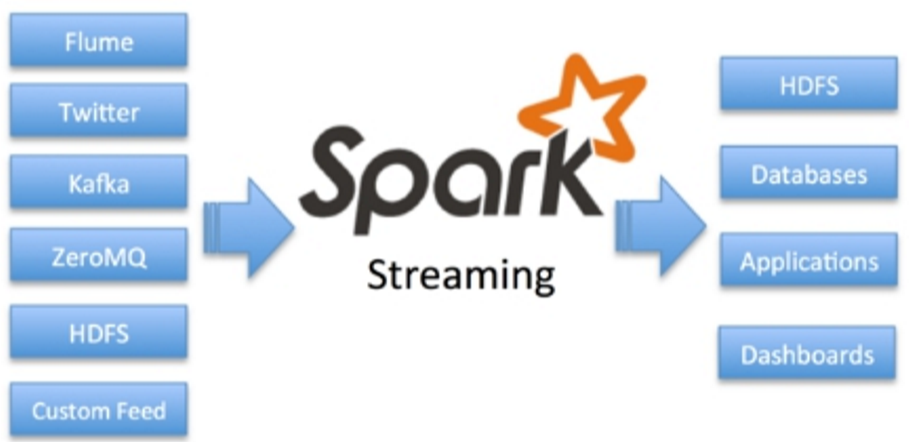
SparkStreaming是一种构建在Spark基础上的实时计算框架,它扩展了Spark处理大规模流式数据的能力,以吞吐量高和容错能力强著称。

SparkStreaming会将源数据以batch为单位来进行处理,每一批数据封装为一个DStream。即SparkStreaming处理的就是一个一个的DStream,而DStream底层就是RDD。
二、架构及原理
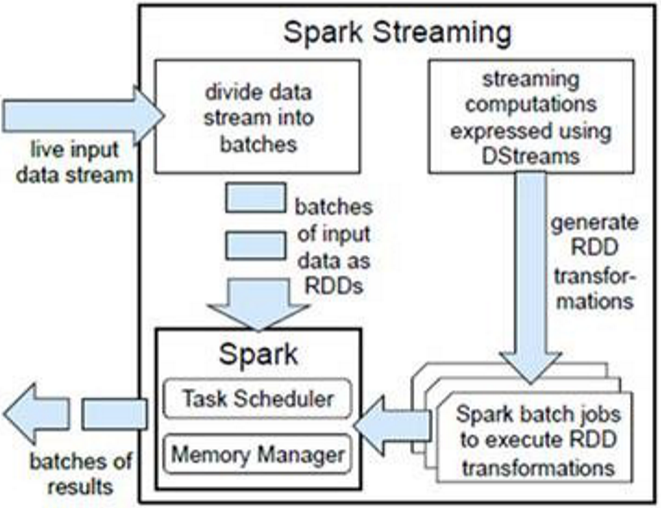
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以对接多种数据源(如Kafka、Flume、Twitter、ZeroMQ、TCP套接字等)进行类似的Map、Reduce和Join等复杂操作,并将结果保存到外部系统、数据库或应用到实时仪表盘。
SparkStreaming是将流式计算分解成一系列短小的批处理作业,也就是SparkStreaming的输入数据按照batch size(如1秒)分成一段一段的数据DStream(Discretized-离散化Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将SparkStreaming中对DStream的Transformation操作变为针对Spark的RDD的Transformations操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务需求可以对中间的结果进行叠加或存储到外部设备。
对DStream的处理,每个DStream都要按照数据流到达的先后顺序依次进行处理。即SparkStreaming天然确保了数据处理的顺序性。这样使所有的批处理具有了一个顺序的特性,其本质是转换成RDD的血缘关系。所以,SparkStreaming对数据天然具有容错性保证。
为了提高SparkStreaming的工作效率,应合理配置批的时间间隔,最好能够实现上一个批处理完某个算子,下一个批算子刚好到来。
三、SparkStreaming入门案例
以下案例代码:https://github.com/Simple-Coder/sparkstreaming-demo
1、案例一
监控指定文件夹处理其中产生的新的文件
1.1 案例代码
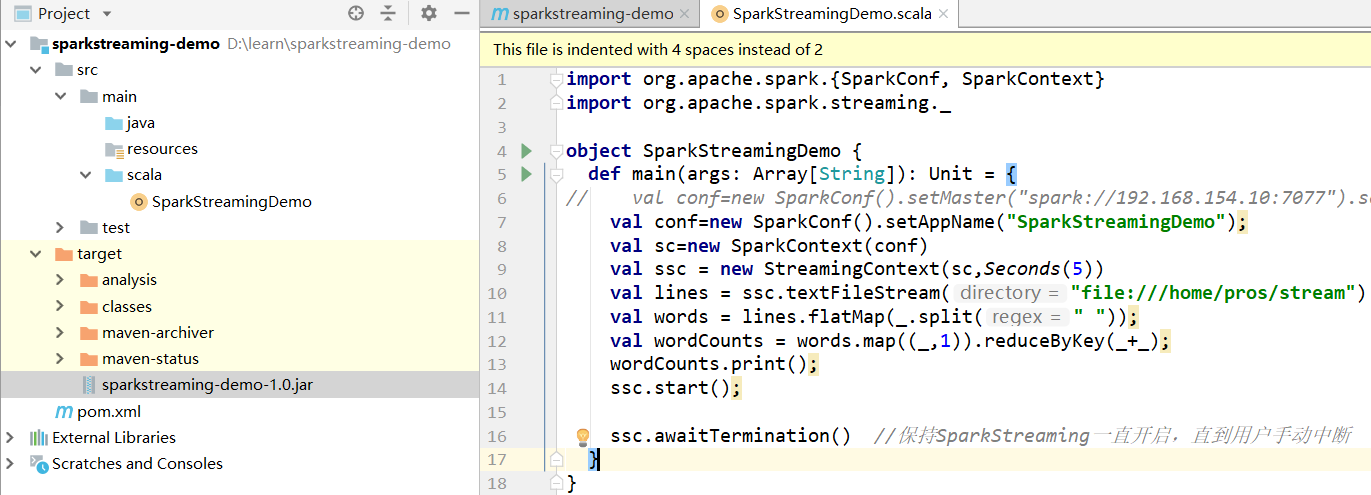
1.2 提交jar包

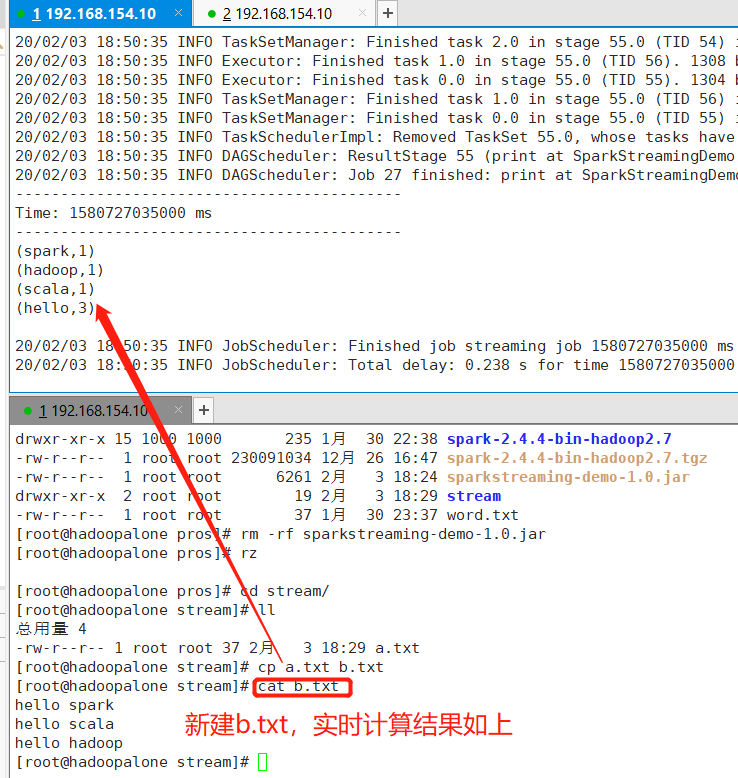
1.3 新增文件测试
2、案例二
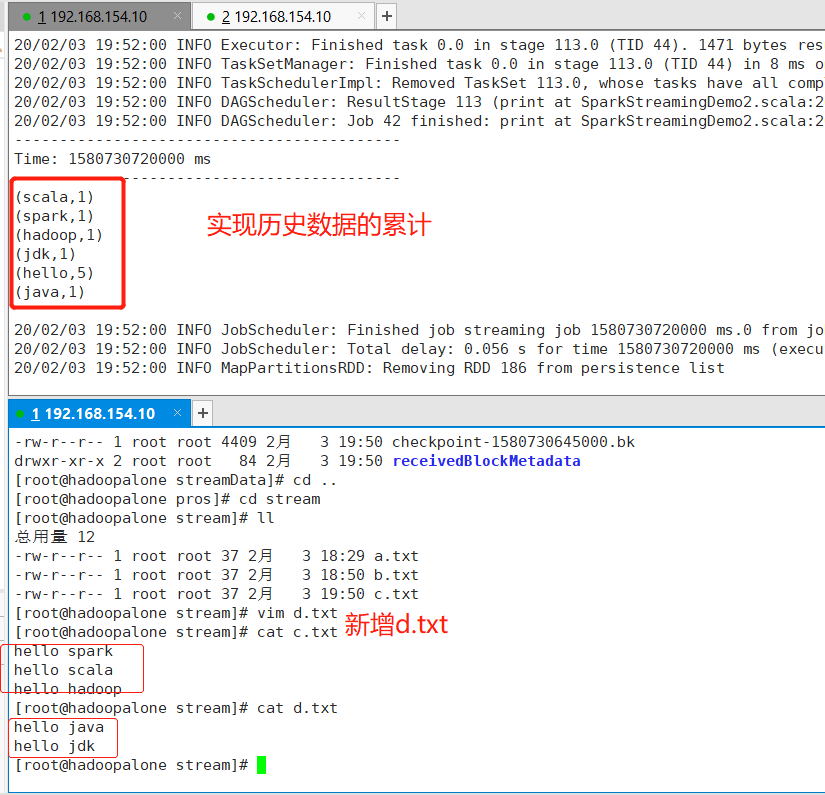
实现:SparkStreaming对历史数据的累加处理
经过测试,案例一的代码确实可以监控指定的文件夹,处理其中产生的新的文件,但是数据在每个周期到来后,都会重新进行计算,而如果需要对历史数据进行累计处理,这时就用到了Spark的CheckPoint机制,首先需要设置一个检查点目录,在这个目录,存储了历史周期数据。通过在临时文件夹中存储中间数据,为历史数据累计处理提供了可能性。
2.1 案例代码
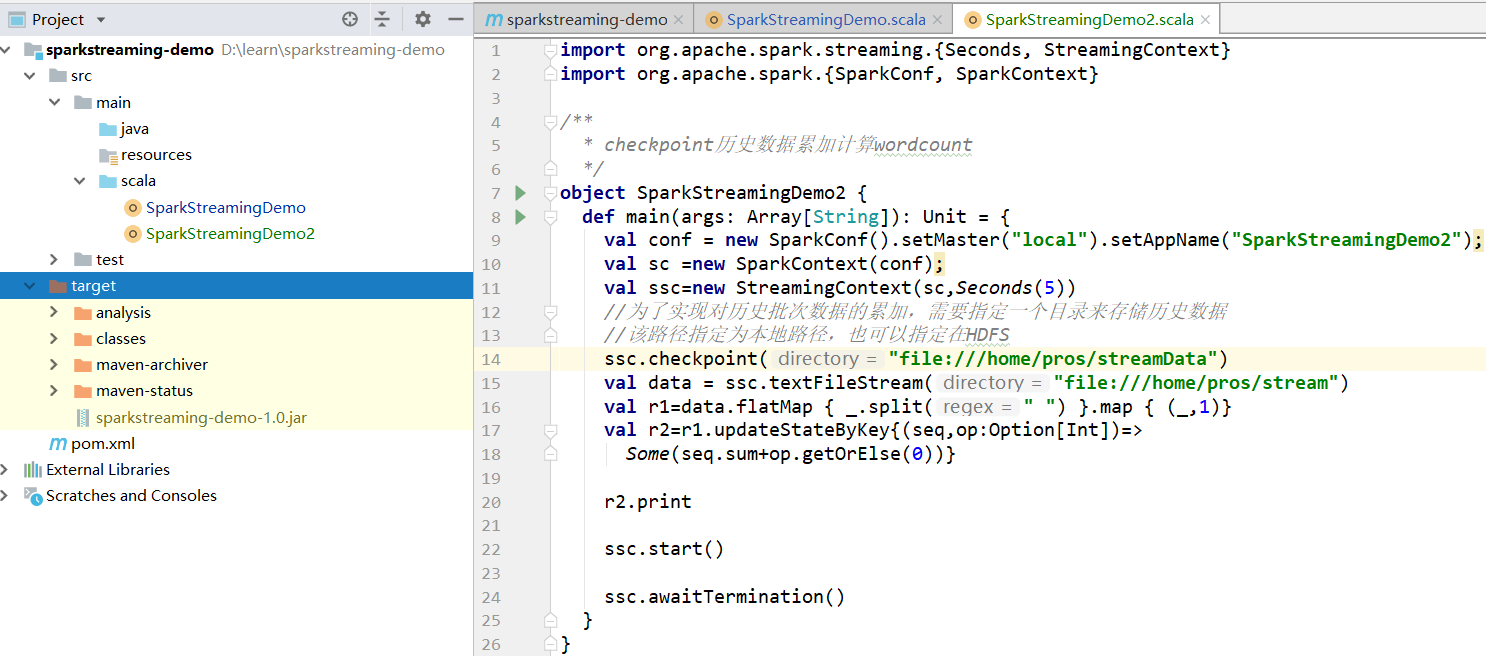
2.2 测试结果
3、案例三
案例二的数据不停的累计下去,有些时候业务需求却是:每隔一段时间重新统计下一段时间的数据,并且能够对设置的批时间进行更细粒度的控制,这样的功能可以通过滑动窗口的方式来实现
Spark的滑动窗口机制:每隔一段时间(滑动区间)计算下一个段时间(窗口长度)的数据
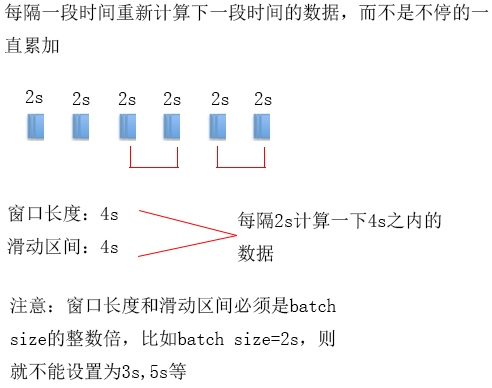
注:窗口长度和滑动区间必须是batch size的整数倍
3.1 案例代码

SparkStreaming个人记录的更多相关文章
- SparkStreaming updateStateByKey 保存记录信息
)(_+_) ) 查看是否存在,如果存在直接获取 )) ssc.checkpoint() )) //使用updateStateByKey 来更新状态 val stateDstream = wordDs ...
- 记录一下SparkStreaming中因为使用redis做数据验证而导致数据结果不对的问题
业务背景: 需要通过redis判断当前用户是否是新用户.当出现新用户后,会将该用户放入到redis中,以标明该用户已不是新用户啦. 出现问题: 发现入库时,并没有新用户入库,但我看了数据了,确实应该是 ...
- SparkStreaming 源码分析
SparkStreaming 分析 (基于1.5版本源码) SparkStreaming 介绍 SparkStreaming是一个流式批处理框架,它的核心执行引擎是Spark,适合处理实时数据与历史数 ...
- 【译】Yarn上常驻Spark-Streaming程序调优
作者从容错.性能等方面优化了长时间运行在yarn上的spark-Streaming作业 对于长时间运行的Spark Streaming作业,一旦提交到YARN群集便需要永久运行,直到有意停止.任何中断 ...
- SparkStreaming
Spark Streaming用于流式数据的处理.Spark Streaming支持的数据输入源很多,例如:Kafka.Flume.Twitter.ZeroMQ和简单的TCP套接字等等.数据输入后可以 ...
- 【SparkStreaming学习之四】 SparkStreaming+kafka管理消费offset
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- sparkStreaming消费kafka-1.0.1方式:direct方式(存储offset到zookeeper)-- 2
参考上篇博文:https://www.cnblogs.com/niutao/p/10547718.html 同样的逻辑,不同的封装 package offsetInZookeeper /** * Cr ...
- sparkStreaming消费kafka-1.0.1方式:direct方式(存储offset到zookeeper)
版本声明: kafka:1.0.1 spark:2.1.0 注意:在使用过程中可能会出现servlet版本不兼容的问题,因此在导入maven的pom文件的时候,需要做适当的排除操作 <?xml ...
- sparkStreaming消费kafka-0.8方式:direct方式(存储offset到zookeeper)
生产中,为了保证kafka的offset的安全性,并且防止丢失数据现象,会手动维护偏移量(offset) 版本:kafka:0.8 其中需要注意的点: 1:获取zookeeper记录的分区偏移量 2: ...
随机推荐
- 广搜 BFS()
极其简陋的BFS模板 void BFS(???){ queue<node>q; node start, next; start = ???; q.push(start); while(!q ...
- numpy 一些知识
import numpy as np 什么类型的相加,返回的还是什么类型的,所以在累加小类型的数值时会出现问题如下: a=np.array([123,232,221], dtype=np.uint8) ...
- opencv-python常用接口
最直接的是参考官网:https://docs.opencv.org/4.2.0/d6/d00/tutorial_py_root.html
- mysql内核测试&原理学习
参考资料:https://www.cnblogs.com/f-ck-need-u/p/9001061.html#blog5
- pytest学习2-运行方式
pytest常用运行方式 运行目录及子包下的所有用例: pytest 目录名 运行指定模块所有用例: pytest test_reg.py pytest test_reg.py::TestClass: ...
- MFC对话框常用操作文章收藏
1.改变控件文本 参考链接:https://blog.csdn.net/active2489595970/article/details/88856235 所有控件的文本都可以用这种方式动态改变. 2 ...
- Codeforces Round #609 (Div. 2) A-E简要题解
contest链接:https://codeforces.com/contest/1269 A. Equation 题意:输入一个整数,找到一个a,一个b,使得a-b=n,切a,b都是合数 思路:合数 ...
- MySQL认知
MySQL 认识MySQL MySQL是什么? MySQL是最流行的关系型数据库管理系统,在WEB应用方面MySQL是最好的RDBMS(Relational Database Management S ...
- JAVASCRIPT实现的WEB页面跳转以及页面间传值方法
在WEB页面中,我们实现页面跳转的方法通常是用LINK,BUTTON LINK ,IMG LINK等等,由用户点击某处,然后直接由浏览器帮我们跳转. 但有时候,需要当某事件触发时,我们先做一些操作,然 ...
- java基础之 变量
变量是一个内存位置的名称. 1.成员变量(实例变量,属性) 成员变量就是类中的属性,当创建对象的时候,每个对象都有一份属性.一个对象中的属性就是成员变量. 2.本地变量(局部变量) 在方法内声明的变量 ...