Data Lake Analytics: 读/写PolarDB的数据

Data Lake Analytics 作为云上数据处理的枢纽,最近加入了对于PolarDB的支持, PolarDB 是阿里云自研的下一代关系型分布式云原生数据库,100%兼容MySQL,存储容量最高可达 100T,性能最高提升至 MySQL 的 6 倍。这篇教程带你玩转 DLA 的 PolarDB 支持。
创建数据库
在 DLA 里面创建一个底层映射到 PolarDB 的外表的语法如下:
CREATE SCHEMA porlardb_test WITH DBPROPERTIES (
CATALOG = 'mysql',
LOCATION = 'jdbc:mysql://pc-bp1dlebalabala.rwlb.rds.aliyuncs.com:3306/dla_test',
USER = 'dla_test_1',
PASSWORD = 'the-fake-password',
VPC_ID = 'vpc-2zeij924vxd303kwifake',
INSTANCE_ID = 'rm-2zer0vg58mfo5fake'
);跟普通的建表不同的是这里多了两个属性: VPC_ID 和 INSTANCE_ID 。VPC_ID 是你的PolarDB所在VPC的ID, 如下图所示:
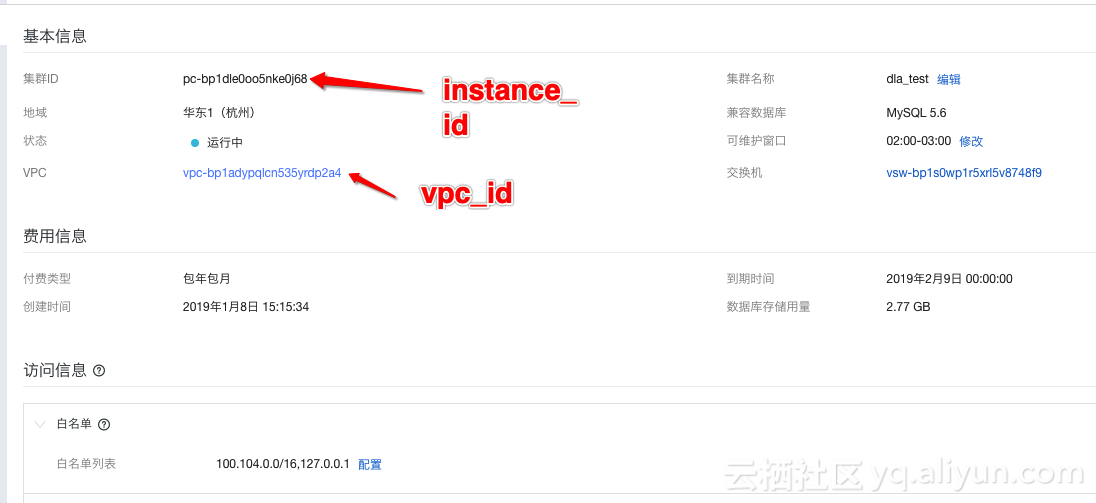
建表需要这两个额外信息是因为现在用户的数据库都是处于用户自己的VPC内部,默认情况下 DLA 是访问不了用户 VPC 里面的资源的,为了让DLA能够访问到用户PolarDB面的数据,我们需要利用阿里云的VPC反向访问技术。
权限声明: 当您通过上述方式建库,就视为您同意我们利用VPC反向访问的技术去读写您的PolarDB。
另外您还需要把 100.104.0.0/16 IP地址段加入到你的PolarDB的白名单列表,这是我们VPC反向访问的IP地段,如下图:
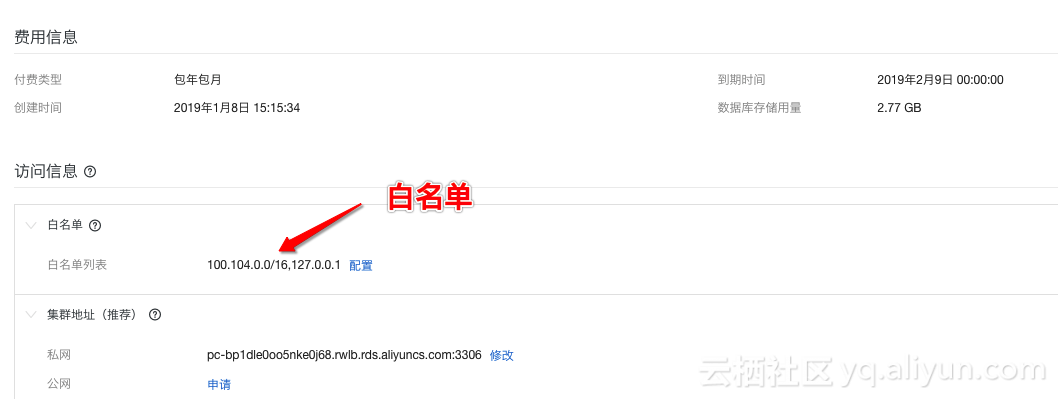
同时细心的读者可能注意到我们这里的 CATALOG 写的是 mysql, 而不是 polardb, 这是因为 PolarDB 100%兼容MySQL,我们直接以MySQL协议去访问就好了。
创建表
数据库建完之后,我们可以建表了,我们先在你的 PolarDB 里面建立如下的 person 表用来做测试:
create table person (
id int,
name varchar(1023),
age int
);并且向里面插入一下测试数据:
insert into person
values (1, 'james', 10),
(2, 'bond', 20),
(3, 'jack', 30),
(4, 'lucy', 40);然后就可以在 DLA 的数据库里面建立相应的映射表了:
create external table person (
id int,
name varchar(1023),
age int
);这样我们通过MySQL客户端连接到 DLA 数据库上面,就可以对 PolarDB 数据库里面的数据进行查询了:
mysql> select * from person;
+------+-------+------+
| id | name | age |
+------+-------+------+
| 1 | james | 10 |
| 2 | bond | 20 |
| 3 | jack | 30 |
| 4 | lucy | 40 |
+------+-------+------+
4 rows in set (0.35 sec)总结
今天主要介绍了一下如果在DLA里面查询PolarDB的数据,因为PolarDB本身兼容MySQL协议,所以在DLA里面的使用上跟MySQL基本一样,因此这里的介绍比较简单,更多的内容就留给读者自己去探索了。
原文链接
更多技术干货 请关注阿里云云栖社区微信号 :yunqiinsight
Data Lake Analytics: 读/写PolarDB的数据的更多相关文章
- 使用Data Lake Analytics读/写RDS数据
Data Lake Analytics 作为云上数据处理的枢纽,最近加入了对于RDS(目前支持 MySQL , SQLServer ,Postgres 引擎)的支持, 这篇教程带你玩转 DLA 的 R ...
- 如何在Data Lake Analytics中使用临时表
前言 Data Lake Analytics (后文简称DLA)是阿里云重磅推出的一款用于大数据分析的产品,可以对存储在OSS,OTS上的数据进行查询分析.相较于传统的数据分析产品,用户无需将数据重新 ...
- Data Lake Analytics + OSS数据文件格式处理大全
0. 前言 Data Lake Analytics是Serverless化的云上交互式查询分析服务.用户可以使用标准的SQL语句,对存储在OSS.TableStore上的数据无需移动,直接进行查询分析 ...
- Data Lake Analytics,大数据的ETL神器!
0. Data Lake Analytics(简称DLA)介绍 数据湖(Data Lake)是时下大数据行业热门的概念:https://en.wikipedia.org/wiki/Data_lake. ...
- 使用Data Lake Analytics从OSS清洗数据到AnalyticDB
前提 必须是同一阿里云region的Data Lake Analytics(DLA)到AnalyticDB的才能进行清洗操作: 开通并初始化了该region的DLA服务: 开通并购买了Analytic ...
- Data Lake Analytics: 使用DataWorks来调度DLA任务
DataWorks作为阿里云上广受欢迎的大数据开发调度服务,最近加入了对于Data Lake Analytics的支持,意味着所有Data Lake Analytics的客户可以获得任务开发.任务依赖 ...
- 使用Data Lake Analytics + OSS分析CSV格式的TPC-H数据集
0. Data Lake Analytics(DLA)简介 关于Data Lake的概念,更多阅读可以参考:https://en.wikipedia.org/wiki/Data_lake 以及AWS和 ...
- Data Lake Analytics账号和权限体系详细介绍
一.Data Lake Analytics介绍 数据湖(Data Lake)是时下大数据行业热门的概念:https://en.wikipedia.org/wiki/Data_lake.基于数据湖做分析 ...
- Data Lake Analytics的Geospatial分析函数
0. 简介 为满足部分客户在云上做Geometry数据的分析需求,阿里云Data Lake Analytics(以下简称:DLA)支持多种格式的地理空间数据处理函数,符合Open Geospatial ...
随机推荐
- Vue+Iview+Node 安装环境 运行测试Vue
1.运行环境及设置 备注:建议设置 npm config set registry https://registry.npm.taobao.org 2.全局安装vue/cli 3.创建vue 项目 v ...
- (转)HttpURLConnection中设置网络超时
转:http://www.xd-tech.com.cn/blog/article.asp?id=37 Java中可以使用HttpURLConnection来请求WEB资源.HttpURLConnect ...
- C# ObservableCollection集合排序
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/BYH371256/article/details/83346807注意:ObservableColl ...
- abstract类与interface
抽象类: 1.用abstract修饰,抽象类中可以没有抽象方法,但抽象方法肯定在抽象类中,且抽象方法定义时不能有方法体: 2.抽象类不可以实例化只能通过继承在子类中实现其所有的抽象方法 ...
- 学SpringBoot一篇就够了
1.SpringBoot概述 Spring 框架对于很多 Java 开发人员来说都不陌生.自从 2002 年发布以来,Spring 框架已经成为企业应用开发领域非常流行的基础框架.有大量的企业应用基于 ...
- 谈谈HINT /*+parallel(t,4)*/在SQL调优中的重要作用
/*+parallel(t,4)*/在大表查询等操作中能够起到良好的效果,基于并行查询要启动并行进程.分配任务与系统资源.合并结果集,这些都是比较消耗资源,但我们为能够减少执行事务的时间使用paral ...
- UMP系统架构 Controller服务器
- 【CF622F】The Sum of the k-th Powers (拉格朗日插值法)
用的dls的板子,因为看不懂调了好久...果然用别人的板子就是这么蛋疼- -|| num数组0~k+1储存了k+2个值,且这k+2个值是自然数i的k次方而不是次方和,dls的板子自己帮你算和的...搞 ...
- Android开发 ViewPager删除Item后,不会更新数据和View
问题描述: 在使用ViewPager的适配器删除适配器里一个Item后依然会,而删除的这个item依然会保留缓存,适配器不会重新加载更新数据.如下代码: public class TReleaseCi ...
- Oracle SQL性能优化【转】
(1) 选择最有效率的表名顺序(只在基于规则的优化器中有效):ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving table) ...