python基--re模块的使用
正则表达式:
正则表达式本身是一种小型的、高度专业化的编程语言,然而在python中,通过内嵌集成re模块让调用者们可以直接调用来实现正则匹配。正则表达模式被变异成一系列的字节码,然后由C语言编写的
匹配引擎执行。
正则表达式是用来匹配处理字符串的,在python中使用正则表达式时需要引入re模块
# 纯python代码校验
while True:
phone_number = input('please input your phone number : ')
if len(phone_number) == 11 \
and phone_number.isdigit()\
and (phone_number.startswith('') \
or phone_number.startswith('') \
or phone_number.startswith('') \
or phone_number.startswith('')):
print('是合法的手机号码')
else:
print('不是合法的手机号码') # 正则表达式校验
import re
phone_number = input('please input your phone number : ')
if re.match('^(13|14|15|18)[0-9]{9}$',phone_number):
print('是合法的手机号码')
else:
print('不是合法的手机号码')
# 正则在所有语言中都可以使用 不是python独有的
# 匹配大段文本中特定的字符
有无正则校验的区别
正则表达式在线测试::http://tool.chinaz.com/regex/(这个与re模块没有任何的关系,仅仅是用来测试正则表达式的)
应用场景:爬虫、数据分析......
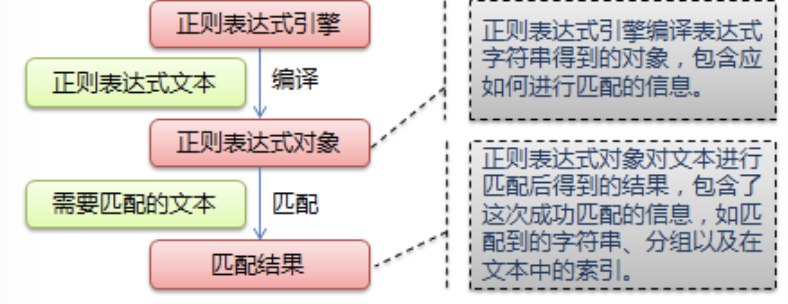
字符组概念:
在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示(一个字符组每次只能匹配一个字符)
例如:
匹配0-9数字就可以简写成[0-9](如果想匹配横杠,直接用反斜杠转义就可以了)
匹配a-z字母简写成[a-z](大写字母同理写可以这样写)
ps:这种什么到什么的范围必须是从小到大的,因为内部对应的ascii码是从小到大的。
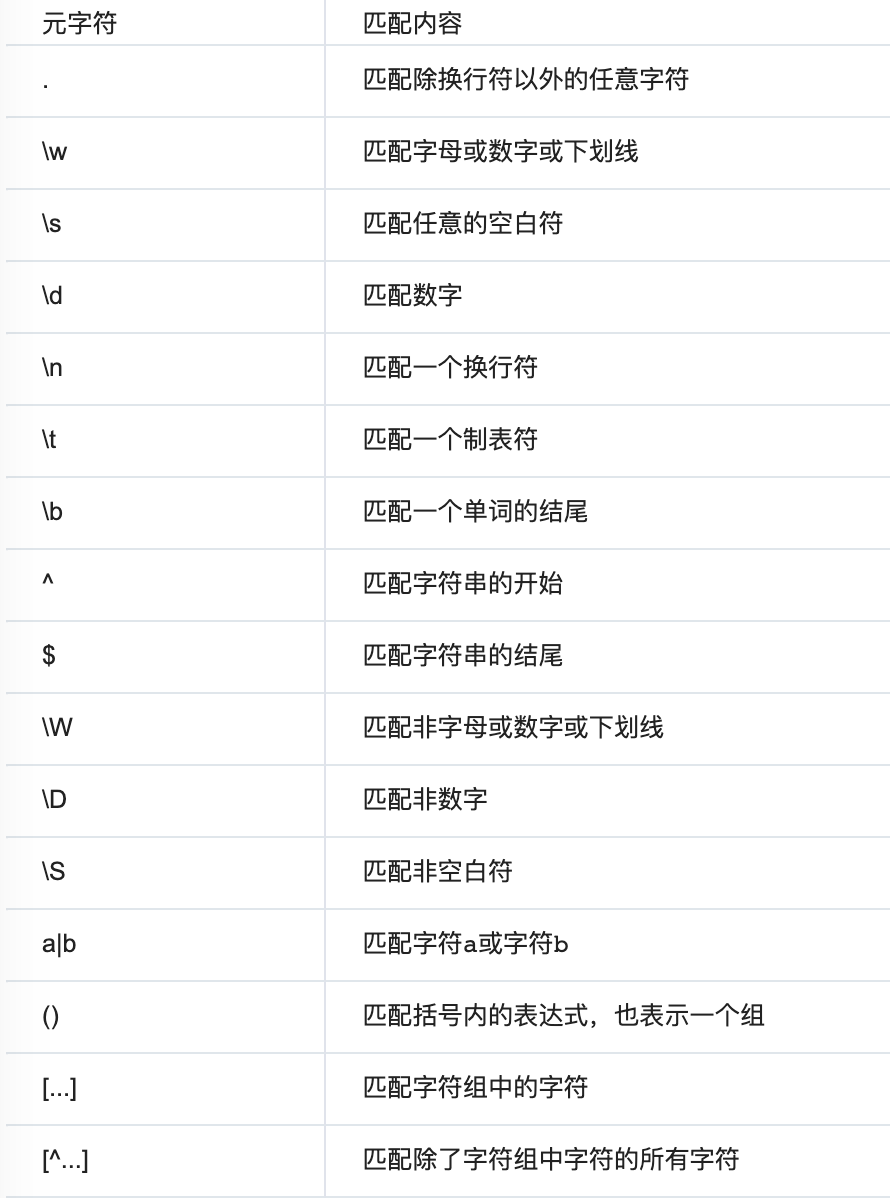
量词:
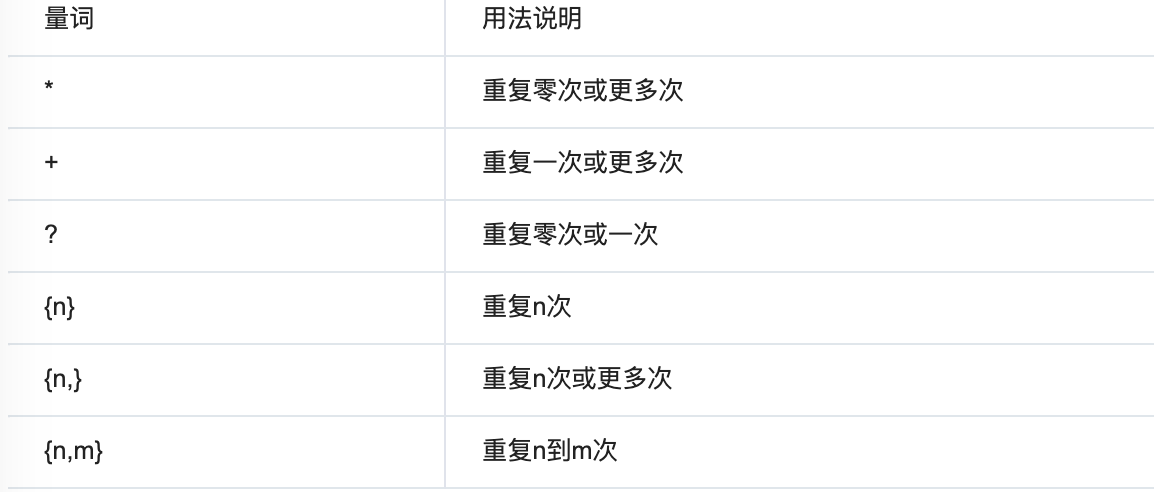
贪婪匹配:
再满足匹配条件时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配。
常用的非贪婪匹配pattern:
*?:重复任意次,但尽可能少重复
+?:重复1次或更多次,但尽可能少重复
??:重复0次或1次,但尽可能少重复
{n,m}?:重复n到m次,但尽可能少重复
{n,}?:重复n次以上,但尽可能少重复
.*?的用法:
. 是任意字符
* 是取0至无限长度
?:是非贪婪模式
合在一起就是,取尽量少的任意字符,一般都不会这么单独写。
re模块中常用的方法:
import re
ret = re.findall('a', 'william john lisa') # 返回所有满足匹配条件的结果,放在列表里
print(ret) #结果 : ['a', 'a']
ret = re.search('a', 'william john lisa').group()
print(ret) #结果 : 'a'
# 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
# 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
ret = re.match('a', 'abc').group() # 同search,不过尽在字符串开始处进行匹配
print(ret)
#结果 : 'a'
# ---------------------------------------------------------------------------------
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
print(ret) # ['', '', 'cd']
ret = re.sub('\d', 'H', 'william1john2lisa3', 1)#将数字替换成'H',参数1表示只替换1个
print(ret) #evaHegon4yuan4
ret = re.subn('\d', 'H', 'william1john2lisa3')#将数字替换成'H',返回元组(替换的结果,替换了多少次)
print(ret)
obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #结果 : 123
import re
ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一个结果
print(next(ret).group()) #查看第二个结果
print([i.group() for i in ret]) #查看剩余的左右结果
注意:
1、findall的优先级查询:
import re
ret = re.findall('www.(baidu|taobao).com', 'www.taobao.com')
print(ret) # ['taobao'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret = re.findall('www.(?:baidu|taobao).com', 'www.taobao.com')
print(ret) # ['www.taobao.com']
2、split的优先级查询:
ret=re.split("\d+","william1john2lisa3")
print(ret) #结果 : ['william', 'john', 'lisa']
ret=re.split("(\d+)","william1john2lisa3")
print(ret) #结果 : ['william', '3', 'john', '4', 'lisa']
#在匹配部分加上()之后所切出的结果是不同的,
#没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项,
#这个在某些需要保留匹配部分的使用过程是非常重要的。
爬虫练习:
import requests
import re # 获取网页源代码
def get_html_content(url):
return requests.get(url).text # 解析获取的源代码,提取有用的内容
def parse_html(html_con):
# 正则进行解析
r = re.compile(r'<p class="name"><.*?>(?P<title>.*?)</a></p>' +
'.*?<p.*?>(?P<actor>.*?)</p>' +
'.*?<a href="(?P<url>.*?)" title=".*?>', re.S)
obj = r.finditer(html_con)
for i in obj:
info = {
'title': i.group('title'),
'actor': i.group('actor').strip(),
'movie_url': 'https://maoyan.com' + i.group('url') }
yield info def main(nums):
url = 'https://maoyan.com/board/4?offset=%s' % nums get_html = get_html_content(url)
for i in parse_html(get_html):
print(i) if __name__ == '__main__':
for i in range(0, 101, 10):
main(i)
这里以爬去电影排行榜为例
python基--re模块的使用的更多相关文章
- 洗礼灵魂,修炼python(11)--python函数,模块
前面的章节你如果看懂了,基本算是入门了七八了,不过如果你以为python就这么点东西,你觉得很简单啊,那你就错了,真正的东西在后面,前面我说的几大核心其实也不是多么高深多么厉害的,那些东西是基础很常用 ...
- 【308】Python os.path 模块常用方法
参考:Python os.path 模块 参考:python3中,os.path模块下常用的用法总结 01 abspath 返回一个目录的绝对路径. 02 basename 返回一个目录的基名 ...
- Python logging(日志)模块
python日志模块 内容简介 1.日志相关概念 2.logging模块简介 3.logging模块函数使用 4.logging模块日志流处理流程 5.logging模块组件使用 6.logging配 ...
- python之platform模块
python之platform模块 ^_^第三个模块从天而降喽!! 函数列表 platform.system() 获取操作系统类型,windows.linux等 platform.platform() ...
- python之OS模块详解
python之OS模块详解 ^_^,步入第二个模块世界----->OS 常见函数列表 os.sep:取代操作系统特定的路径分隔符 os.name:指示你正在使用的工作平台.比如对于Windows ...
- python之sys模块详解
python之sys模块详解 sys模块功能多,我们这里介绍一些比较实用的功能,相信你会喜欢的,和我一起走进python的模块吧! sys模块的常见函数列表 sys.argv: 实现从程序外部向程序传 ...
- 学习PYTHON之路, DAY 6 - PYTHON 基础 6 (模块)
一 安装,导入模块 安装: pip3 install 模块名称 导入: import module from module.xx.xx import xx from module.xx.xx impo ...
- linux下python调用c模块
在C调用Python模块时需要初始化Python解释器,导入模块等,但Python调用C模块却比较简单,下面还是以helloWorld.c 和 main.py 做一说明: (1)编写C代码,hel ...
- Python学习之模块进程函数详解
今天在看<Beginning Linux Programming>中的进程相关部分,讲到Linux几个进程相关的系统函数: system , exec , fork ,wait . Pyt ...
随机推荐
- 使用pageHelper分页查询,报sql语句错误
1.异常详情: 2.异常分析: (1)pageHelper分页大致流程: 配置默认的拦截器:pagehelper.PageInterceptor,对发送的查询语句进行拦截,拦截之后对原有的查询语句进 ...
- css---switch开关
html: <label><input class="mui-switch" type="checkbox"> 默认未选中</la ...
- jeecms v9 vue环境搭建
一.安装NODEJS运行环境 前往nodejs官网下载nodejs,https://nodejs.org/en/ ,建议下载最新稳定版的,下载后安装即可,下载选择类似如下 安装完毕之后,在cmd中输入 ...
- nulls_hlist原理 和 tcp连接查找
原文链接 http://abcdxyzk.github.io/blog/2018/09/28/kernel-sk_lookup/
- Linux-c glib库hash表GHashTable介绍
百度云glib 链接:https://pan.baidu.com/s/1W9qdlMKWRKIFykenTVuWNQ 密码:ol6y hash表是一种提供key-value访问的数据结构,通过指定的 ...
- C语言中常用的字符串处理函数总结
C语言中字符串处理函数备注 此文仅用于自己研究和记录 字符串处理函数 1. char *gets(char *s); #include<stdio.h> 功能: 从标准输入读入字符,并保存 ...
- 启发式搜索——A*算法
启发式搜索 启发式搜索是一种对搜索到的每一个位置进行评估,然后从评估的最优位置进行搜索直到目的地, 由于搜索时对每一个位置的评估是基于直观或经验的所有叫启发式搜索 A*算法 历史: 1964年Nils ...
- windows下和linux下运行jar
需要在windows下运行jar,首先需要我们打包出来可执行jar idea打包可执行jar可以参考我的另一篇博客[https://mp.csdn.net/postedit/88653200] 一.w ...
- svn 设置快捷命令
# some more svn aliases alias svnset='svn propset svn:externals . -F' alias svnget='svn propget svn: ...
- autoreleasing的用法介绍:
在c/c++,objective-c内存管理中有一条是:谁分配谁释放. __autoreleasing则可以使对像延迟释放.比如你想传一个未初始化地对像引用到一个方法当中,在此方法中实始化此对像,那么 ...