HotRing: A Hotspot-Aware In-Memory Key-Value Store(FAST ’20)
本文主要解决的是基于内存的K-V存储引擎在实际应用中出现的热点问题,设计了一个热点可感知的KV存储引擎,极大的提升了KV存储引擎对于热点数据访问的承载能力。
Introduction
热点问题,可以理解为在一个严重倾斜的工作负载下,频繁的访问和操作某一小部分数据。
如图,是阿里的不同业务中数据访问分布情况,大量的数据访问只集中在少部分的热点数据中。在平常的情况下,百分之五十的用户访问请求只是针对其中百分之一的数据,在一些极端的情况下,当新产品发售后,大量的粉丝疯狂进行抢购下单,业务的访问量基本都聚集在某一小部分数据上,会出现百分之九十的用户请求针对其中百分之一的数据。

目前有一些方法来解决热点数据问题:
- 使用一致性哈希算法将数据分片,分布到多个节点上,分摊热点访问。(Scale out using consistent hashing)
- 将热点数据备份到多个节点上,分摊热点访问。 (Replication in multi-node)
- 客户端缓存:通过预先标记热点,设置客户端层面的缓存。减小键值存储系统的负载压力。(Front-end cache)
第一种和第二种方法中因为节点的添加,会使得系统的成本会大大增加。第三种方法,如果用户请求中涉及到很多数据更新的请求,对客户端层面的缓存的数据需要维护,这个过程实现会变得很复杂。
本篇论文则是从提升单个点对热点数据的处理能力出发(Improve Single node’s ability to handle hotspots),设计了一种热点可感知的键值数据结构,实现在严重倾斜的工作负载下,快速的完成用户的访问请求。
Prior work
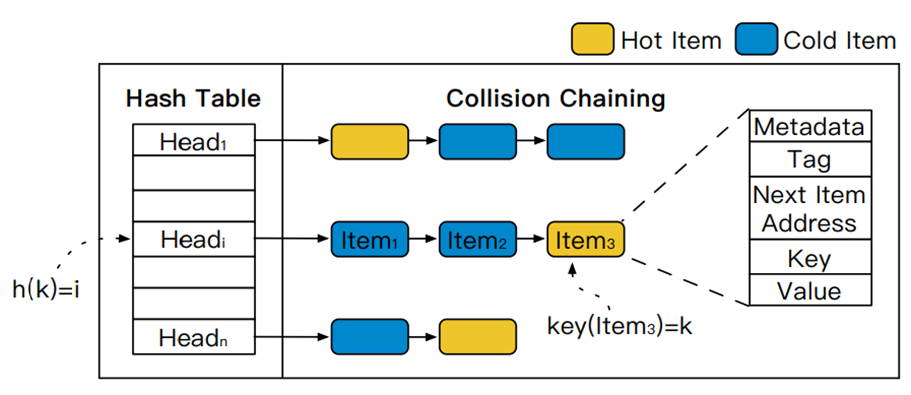
现有很多基于内存的键值存储引擎通常采用链式哈希作为索引,这种索引结构对热数据是无法感应到,数据项被随机的分布在链表上。如果图中item3是一个热数据项,他处在某一链表的尾部,需要经过多次内存访问才可以将item3的数据取出来。如果高度倾斜的工作负载下,要通过多次内存访问才可以的得到item3,会使得系统的性能就会很低下。如果可以将热点数据放置在冲突链头部,那么系统对于热点数据的访问将会有更快的响应速度。
Challenges
设计一个热点可感知的索引结构需要解决两个问题:
- 数据的热度是动态变化的,必须实现动态的热点感知,保证热点时效性。
- 无锁化处理,基于内存的键值存储引擎性能是很敏感的,要保证高性能就必须支持无锁的并发读/写操作
Design of HotRing
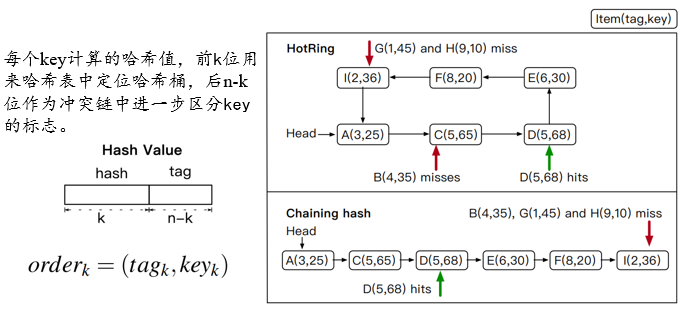
论文提出的索引结构被称作hotring,与传统的哈希结构不同的是,将哈希表中的链式结构改成了环,哈希表中存储的头指针可以指向环中的任意数据项。当链表变成环的时候,以头指针所指的数据项为起点,查找要访问的元素,如果元素不存在,就会一直循环查找下去,因此,作者将该还设计成一个有序环。

在变成有序环的时候,因为表示key大小所用的字节数一般不会少(通常为10-100字节大小),只是简单的对key进行排序,比较会带来巨大的开销。我们构建字典序:order = (tag, key)。先根据tag进行排序,tag相同再根据key进行排序:以itemB举例,链式哈希需要遍历所有数据才能返回read miss。而HotRing在访问itemA与C后,即可确认B read miss。
Hotspot Shift Identification
每段时间用户的访问需求在不断变化,数据的热度是动态变化的,HotRing实现了两种策略来实现周期性的动态识别热点并调整头指针指向。
- 随机移动策略
- 采样分析策略
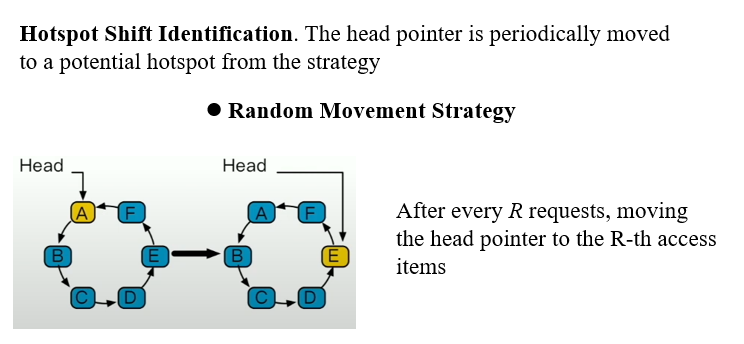
随机移动策略
每个线程维护一个变量,记录执行了多少次请求,每R次访问,移动头指针指向第R次访问的数据项。若指针已经指向该数据项,则头指针不移动。该策略的优势是, 不需要额外的元数据开销,实现简单,响应速度快。
缺点:
- 若R小,找到热点的时间会很短,但是可能造成频繁的头指针移动。
- 若用户的访问负载倾斜程度小,头指针移动的频率会变高,效率就会降低。
- 难以处理环中多个热点数据。
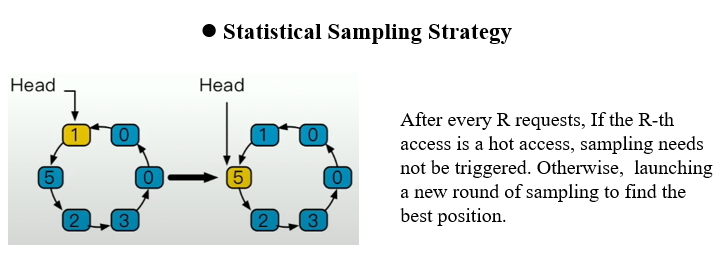
采样分析策略
使用该策略时,同样的,在R次访问后,若第R次访问的item已经是头指针指向的item,则不启动采样,否则,尝试启动对应冲突环的进行采样。
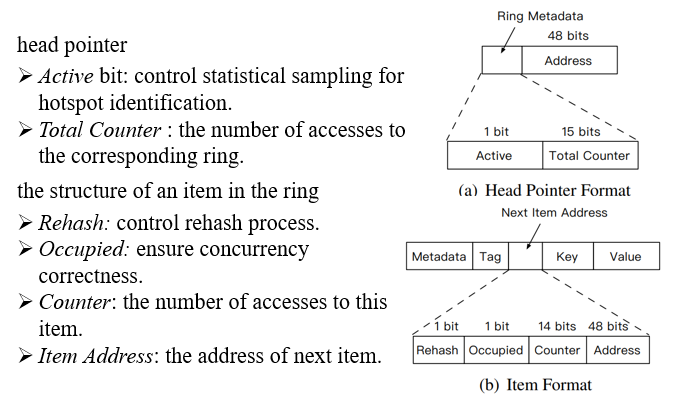
在介绍采样策略之前,先介绍一下头指针和数据项对应的数据结构。头指针head包括:
- active:1 bit,作为控制采样分析的标识。
- total_counter:15 bits,当前环总共的访问次数。
- address:48 bits,环的头地址(x86-64上目前只使用了48位)。
而环上每一项的next包括(因为现代操作系统所使用的内存地址空间使用64bit,而环中下一项的地址实际只需要48bit即可表示,其余的16bit来控制并发,访问次数等信息):
- rehash:1 bit,作为控制rehash的标识。
- occupied:1 bit,用于并发控制,保证并发访问的正确性。
- counter:14 bits,该项的访问次数。
- address:48 bits,下一项的地址。
现在开始介绍采样分析策略,如果第R次访问数据项并不是头指针指向的数据项,说明热点数据已经发生了变化,这个时候会对冲突环进行采样。采样的过程如下:
- 打开head.active(CAS)
- 后续的请求的访问记录会被记录到头指针的total_count和对应item的的next.count(CAS)采样个数也是R
- 采样结束后,将头指针的采样标记恢复过来。
CAS(Compare And Swap):当要操作内存中某一个变量的时候,会记录下变量中的旧值,通过对旧值进行一系列的操作后得到新值,然后将旧值会与内存中的变量做比较,如果不相同,则说明内存中的值在这期间内被修改过,这时CAS操作将会失败,新值将不会被写入内存。如果相同,使内存中的变量变为新值。
对数据采样结束后,利用已有的信息可以进行判断将哪一个数据项作为头节点。具体过程如下:
- 遍历环,计算每一项的访问频率。(第k项的访问次数nk,环中所有项的访问次数为N,则第k项的访问频率为nk/N)。
- 计算每个节点的收益W,取最小的收益的数据项作为新的热数据项。每一项的受益值的计算公式如下,假设现在求第k项的收益,即计算所有项到该项的距离乘以该项的访问频率,求得每一项的期望值,选择最小的期望值作为新的头节点:
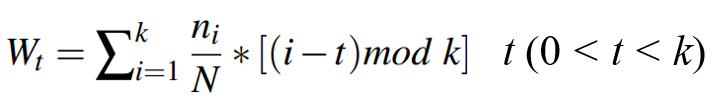
- 使用CAS原子操作将新的头指针指向数据项。
- 重置头指针和数据项的计数器。
Write-Intensive Hotspot with RCU
在一般情况下,对于更新操作,HotRing可以对不超过8字节的数据进行update-in-place原子更新操作,这种情况下,读取和更新被视作一样的操作。但对于超过8个字节的大数据进行更新,hotring则会使用read-copy-update协议,RCU——更新数据的时候,首先拷贝一个副本,然后对副本进行修改,最后使用一个回调(callback)机制在适当的时机把指向原来数据的指针重新指向新的被修改的数据,这个期间数据都是可以随意读的。
当更新的数据项是头指针指向的热数据项时,因为要修改前一个数据项的next指针,需要遍历整个环来获取头节点的前一项。如图,遍历得到热数据的前一项需要花费大量的内存访问开销。论文在这种情况下,更新的只是前一项的计数器,其他项的计数器不变,这样可以使得头指针可以在后面的策略调整中直接指向热数据的前一项,使得对热数据的更新需要的内存访问操作就会减少。

Concurrent Operations
1.Read操作
Hotringd的读取不需要任何的操作,操作完全无锁。
2.Insert操作
当两个线程都在B、D之间插入时,对原来结构的修改,只涉及到B项的next项,修改B项的next项的竞争冲突可以通过CAS保证线程安全。若前一项next字段发生竞争,CAS会失败,此时操作需要重试。

3.Update操作
当更新的数据不超过8字节:使用in-place update方法去更新即可,不需要其它操作,线程安全可以通过CAS保证。当更新的数据超过8字节:使用RCU更新,因为采用RCU方法,这时候需要分3种情况:
①RCU-update & Insert
2个线程分别更新B和插入C,两个线程对原来结构的影响分别是修改A的next指针和修改B的next指针,即便存在CAS操作,但两者之间不存在冲突,所以两个操作都会成功,但结果肯定不是我们所希望的。
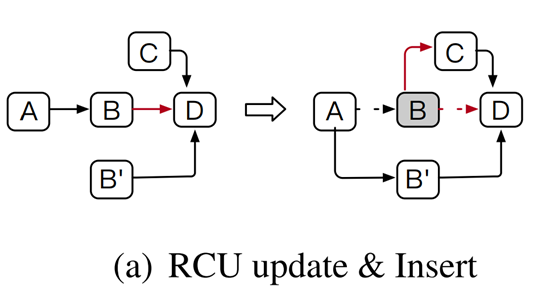
解决办法:RCU-update前,尝试CAS修改B.next值,置B.next.occupy = 1。另外一个线程的在完成插入操作时,使用CAS原子操作访问前一个节点B的next字段,发现该字段的occupy位为1,操作会失败,重试。操作完成后,新版本项的occupy为0。
②RCU-update & RCU-update
2个线程分别更新B和更新D,两个线程对原来结构的影响分别是修改A的next指针和修改B的next指针,即便存在CAS操作,但两者之间不存在冲突,所以两个操作都会成功,但结果肯定不是我们所希望的。

解决办法:更新B的时候,创建一个新的数据项B’,使用CAS操作修改B的,置B.next.occupy = 1,当另一个线程修改D节点后,使用CAS连接前一个节点B的时候,发现B.next.occupy = 1,操作会失败,重试。
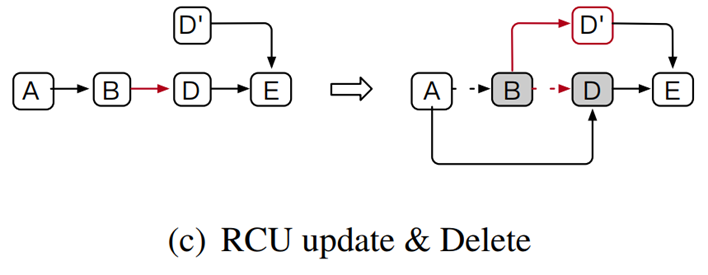
③RCU-update & Delete
2个线程分别删除B和更新D,会出现和上述一样的问题。此处不再赘述。
4.头指针在并发下的移动操作
- 当要移动头指针时,为了避免新的头节点在这个过程中出现更新或者删除的情况,导致头指针可能指向无效的数据项,我们会通过CAS设置新的头节点的occupy为1,保证不被被其他操作更新/删除。
- 当头节点被更新时:更新时会设置新版本的头节点occupy为1,使得其他操作无法对新节点造成影响。将头指针指向新的头节点,将新版本的occupy标记为0
- 当头节点被删除时:除了设置当前被删除的头节点occupy为1,还得设置下一项的occupy为1,因为下一项是新的头节点,需要保证其不被更新/删除
Lock-free Rehash
当冲突环上存在多个热点数据时,键值对存储引擎的性能就会大大降低。因此HotRing设计了无锁rehash策略来解决这一问题。和普通的哈希表不同的是使用负载因子来触发rehash不同,HotRing使用访问开销(即操作平均内存访问次数)来触发rehash,文中设置平均内存访问次数超过2的时候,就会自动触发。HotRing rehash分为3步:
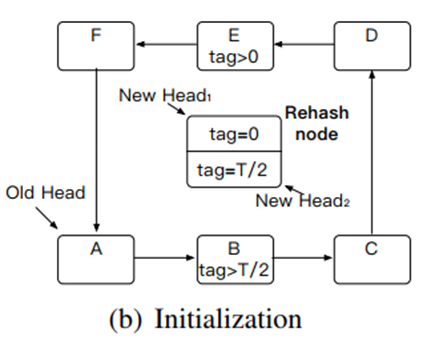
1. 初始化 ——首先创建线程来专门处理rehash操作,初始化一个2倍大小的散列表,复用tag的最高一位来进行索引,将原先的一个环拆分成了两个环。根据tag范围对数据项进行划分。假设tag最大值为T,tag范围为[0,T),则两个新的头指针对应tag范围为[0,T/2)和[T/2,T)。然后该线程创建一个rehash node,里面包含2个rehash child item,作为2个新环的头,它的格式和data item一样,但是tag值分别是0和T/2。

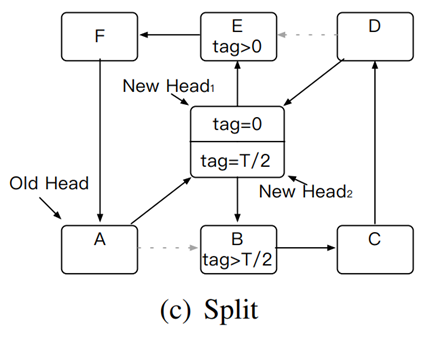
 2. 分割——接下来需要分割原有的环到2个新的环。如图,因为itemB和E是tag的范围边界,所以线程会将两个rehash item节点分别插入到itemB和E之前。到目前为止,已经在逻辑上将冲突环一分为二。
2. 分割——接下来需要分割原有的环到2个新的环。如图,因为itemB和E是tag的范围边界,所以线程会将两个rehash item节点分别插入到itemB和E之前。到目前为止,已经在逻辑上将冲突环一分为二。
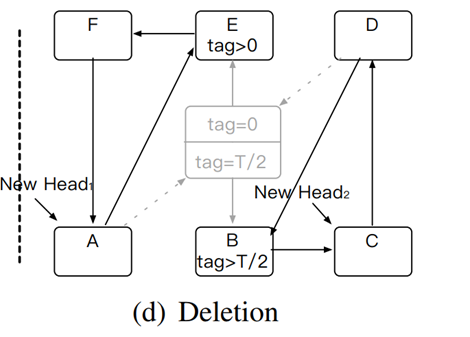
3. 删除——最后一步,将每一个环中首尾两部分连接在一起。此外,还有一些收尾工作,包括旧哈希表的回收、以及rehash节点的删除回收等。需要注意的是,在完成删除操作之前,要确保所有对旧哈希表的访问已经结束。只有rehash线程会阻塞一段时间。
Evaluation
Experimental Setting
在一台内存容量为32GB的服务器上测试的,测试的时候使用YCSB提供5种工作负载,默认情况下,使用64个线程在两亿五千万个键值对测试负载B,在测试负载中,有百分之97.8的操作是针对其中百分只1的数据,百分之99.8的操作是针对10%的数据,

Deployment
- HotRing-r (random movement strategy)
- HotRing-s (sampling statistics strategy)
Baselines
- Chaining Hash(a lock-free chain-based hash index that is modified from the hash structure in Memcached.)
- FASTER(SIGMOD 2019)
- Masstree
- Memcached
在单线程和多线程情况下,对这几种数据结构的性能进行了测试。Hotring在大量读操作的情况下,可以实现一个很高的性能。

下图中,左图表明,链或者环中数据项的个数即便很多,hotring也可以保持一个很好的性能。右图表明hotring在数据访问呈现严重倾斜的情况下,也能保持非常好的性能。(θ是齐夫分布的参数,YCSB生成工作负载时, θ的值越高,表明测试的所使用负载的倾斜程度就越严重。)
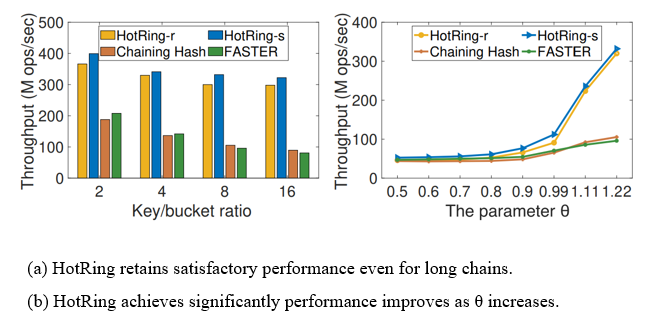
在下图中,左图表明hotring在read miss的情况下的性能比chaining hash的性能要好。这是因为hotring中每一个桶的环是有序的,判断元素不存在不需要遍历桶中的所有元素。右图热点切换时,不同的热点选择策略稳定下来需要的时间,hotring-r在两秒内就可以达到一种稳定的状态了。

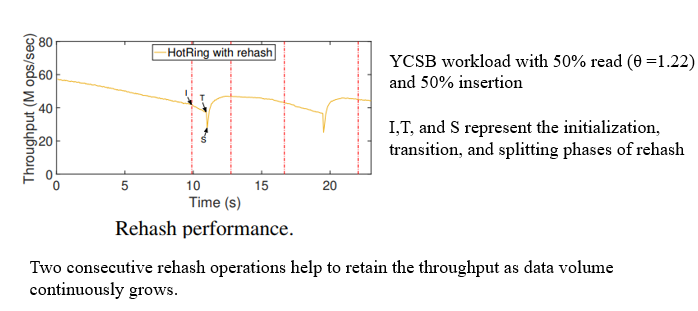
在分裂前,为了保证从旧哈希表进入的访问均已经返回,rehash的过程被阻塞一段时间,随着数据容量的不断增长,rehash操作可以维持这个稳定的性能。如下图所示:
参考资料:
1.Jiqiang Chen, Liang Chen, Sheng Wang, Guoyun Zhu, Yuanyuan Sun, Huan Liu, Feifei Li:HotRing: A Hotspot-Aware In-Memory Key-Value Store. FAST 2020: 239-252
2. 最快KV引擎!存储顶会FAST’20论文揭秘Tair创新性引擎
HotRing: A Hotspot-Aware In-Memory Key-Value Store(FAST ’20)的更多相关文章
- etcd -> Highly-avaliable key value store for shared configuration and service discovery
The name "etcd" originated from two ideas, the unix "/etc" folder and "d&qu ...
- hotspot的Heap Memory和Native Memory
JVM管理的内存可以总体划分为两部分:Heap Memory和Native Memory.前者供Java应用程序使用的:后者也称为C-Heap,是供JVM自身进程使用的.Native Memory没有 ...
- Android内存管理(4)*官方教程 含「高效内存的16条策略」 Managing Your App's Memory
Managing Your App's Memory In this document How Android Manages Memory Sharing Memory Allocating and ...
- PatentTips - Method to manage memory in a platform with virtual machines
BACKGROUND INFORMATION Various mechanisms exist for managing memory in a virtual machine environment ...
- SAP NOTE 1999997 - FAQ: SAP HANA Memory
Symptom You have questions related to the SAP HANA memory. You experience a high memory utilization ...
- 程序间数据共享与传递:EXPORT/IMPORT、SAP/ABAP Memory
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
- 《Small Memory Software:Patterns For System With Limited Memory》读书笔记
原文地址:http://blog.csdn.net/jinzhuojun/article/details/13297447 虽然摩尔定律让我们的计算机硬件得以以指数速度升级,但反摩尔定律又不断消减这些 ...
- Method and apparatus for providing total and partial store ordering for a memory in multi-processor system
An improved memory model and implementation is disclosed. The memory model includes a Total Store Or ...
- CDH版本Hbase二级索引方案Solr key value index
概述 在Hbase中,表的RowKey 按照字典排序, Region按照RowKey设置split point进行shard,通过这种方式实现的全局.分布式索引. 成为了其成功的最大的砝码. 然而单一 ...
随机推荐
- salesforce零基础学习(九十七)Event / Task 针对WhoId的浅谈
我们在Sales Cloud中经常会创建顾客,如果针对TO C业务,会启用个人顾客,比如针对车企行业,有一些场景是需要卖给个人的,而不只是企业采购.当通过打电话或者其他的场景有潜在客户并且转换成客户以 ...
- 【Scala】利用Akka的actor编程模型,实现2个进程间的通信
文章目录 步骤 一.创建maven工程,导入jar包 二.master进程代码开发 三.worker进程代码开发 四.控制台结果 步骤 一.创建maven工程,导入jar包 <propertie ...
- Adobe Reader XI 打开后“已停止工作”的解决办法
搜了好多方法按照步骤做完,基本无用,试了以下方法搞定. 具体方法是: 把域名解析到本机. 打开 C:\Windows\System32\drivers\etc\hosts 添加 127.0.0.1 a ...
- 安卓集成Unity开发示例(一)
本项目目的是在移动端的 Native App 中以库的形式集成已经写好的 Unity 工程,利用 Unity 游戏引擎便捷的开发手段进行跨平台开发. Unity官方文档 Unity as a Libr ...
- 排序算法整理(Python实现)
目录 1. 冒泡排序 2. 选择排序 3. 插入排序 4. 归并排序 5. 快速排序 1. 冒泡排序 冒泡排序(Bubble Sort)是稳定排序,其基本思想是:遍历待排序列,依次两两比较,如果顺 ...
- PrintStream:打印流
package com.itheima.demo05.PrintStream; import java.io.FileNotFoundException; import java.io.PrintSt ...
- php对接金蝶系统
金蝶系统是强大的财务系统,可对公司的财务进行整理,所以有的时候需要去我php系统来对接金蝶系统,为金蝶系统生成各种单据.下面是php对接金蝶的流程. 各种方法已经封装好,直接可以调用就行了. 1.如果 ...
- Spark2.4.5集群安装与本地开发
下载 官网地址:https://www.apache.org/dyn/closer.lua/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz 验证Java ...
- Jmeter简单性能测试练习
项目描述: 被测网站:xqtesting.blog.51cto.com 指标:响应时间以及错误率 场景:线程数20 测试步骤: 测试计划 线程组 http请求 监听器 运行脚本 查看报告 1.添加 ...
- Power安装linux-BIG ENDIAN mysql编译安装
一.安装系统,不选择额外的软件 mkvdev -vadapter vhost0 -vdev hdisk2 -dev db_mysql01_sys mkvdev -vadapter vhost0 -vd ...