Spark的任务提交和执行流程概述
1、概述
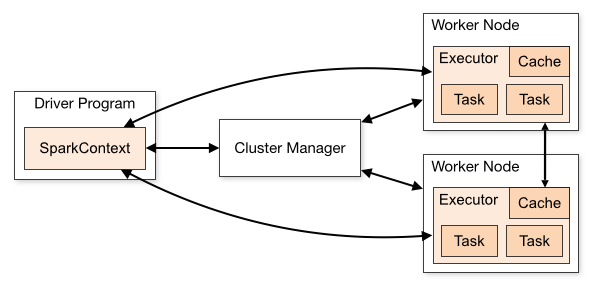
为了更好地理解调度,我们先看一下集群模式的Spark程序运行架构图,如上所示:
2、Spark中的基本概念
1、Application:表示你的程序
2、Driver:表示main函数,创建SparkContext。并由SC负责与ClusterMananger通信,进行资源的申请,任务的监控和分配。程序执行完毕后,关闭SparkContext。
3、Executor:某个Application运行在worker节点上的一个进行,该进程负责运行某些task,并且负责将数据存在内存或者磁盘上。在spark on yarn模式下,其进程名称为CoarseGrainedExectorBackend,一个CoarseGrainedExectorBackend进程有且仅有一个executor对象,它负责将task包装成taskRunner,并从线程池中抽取一个空闲线程运行task,这样,每个CoarseGrainedExectorBackend能并行运行task的数据就取决于分配给它的cpu的个数。
4、Worker:集群上的计算节点,对应一台物理机。在Standalone模式中值得是通过slave文件配置的worker节点,在Spark on yarn模式中指的是NodeManager节点。
5、Task:在Exector进程中执行任务的工作单元,多个task组成一个Stage
6、job:包含多个task组成的并行计算,是又action行为触发的。
7、Stage:每个job任务会被拆分成很多个Task,作为一个TaskSet,其名称为Stage
8、DAGScheduler:根据job将DAG划分成不同的Stage,并提交Stage给TaskScheduler,其划分Stage的依据是RDD之间的依赖关系。
9、TaskScheduler:将TaskSet提交给worker运行,每个Exector运行什么Task就是在此分配。
10、SchedulerBackend:是一个tait,作用是分配当前可用的资源,具体就是向当前等待分配计算资源的task分配计算资源,即Exector,并且在分配的Exector中启动task,完成计算调度。
3、Spark在不同集群中的运行流程
Spark提供了多种集群运行模式,部署在单台机器上,既可以使用本地local模式运行,也可以使用伪分布式模式运行;当以分布式集群部署的时候,可以使用Spark自带的Standalone模式、Yarn-client模式或者Yarn-Cluster模式。
3.1、Saprk On Standalone的运行流程说明:
Standalone模式是Spark实现的资源调度框架,其主要的节点有Client节点、Master节点和Worker节点。其中Driver既可以运行在Master节点上中,也可以运行在本地Client端。当用spark-shell交互式工具提交Spark的Job时,Driver在Master节点上运行;当使用spark-submit工具提交Job或者在Eclips、IDEA等开发平台上使用”new SparkConf().setMaster(“spark://master:7077”)”方式运行Spark任务时,Driver是运行在本地Client端上的。
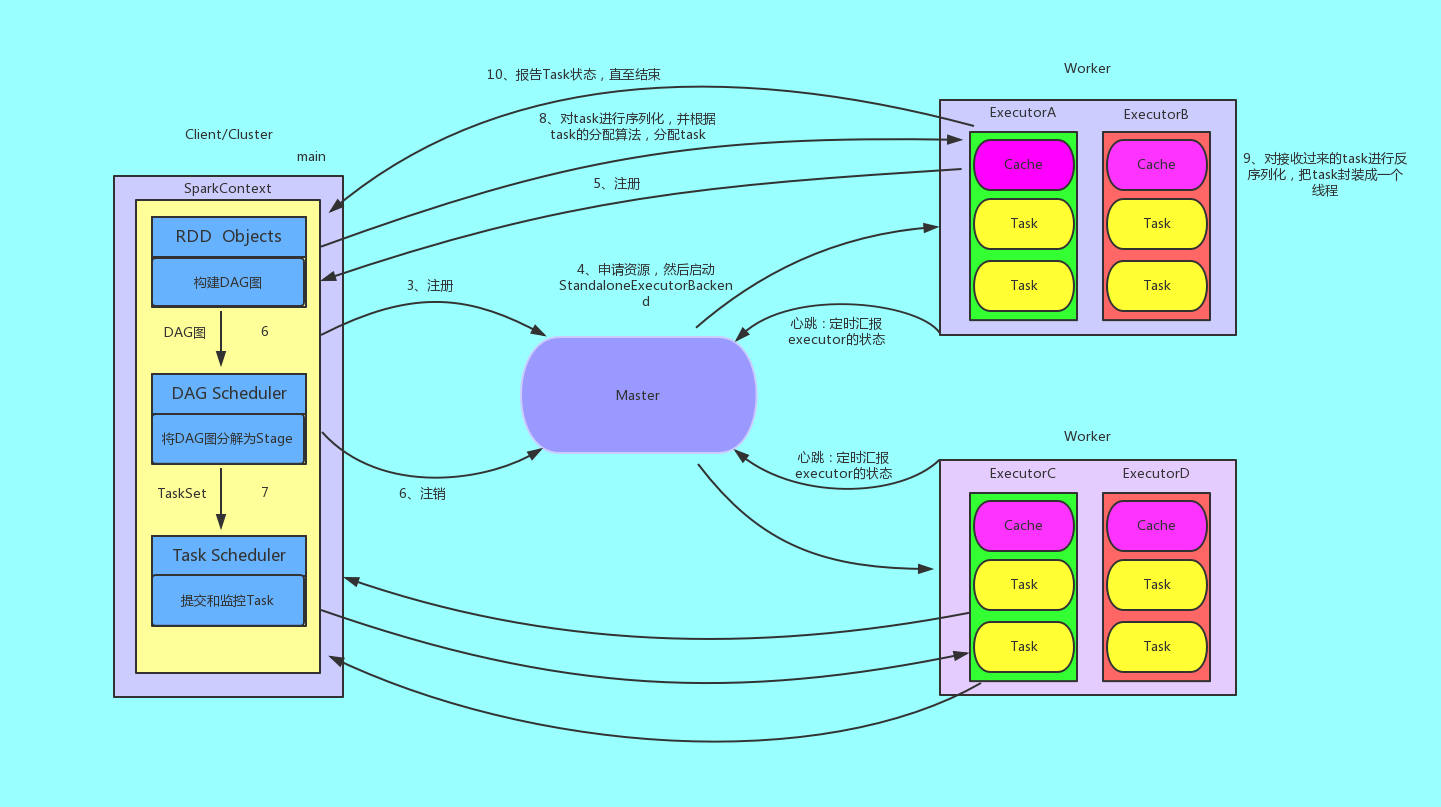
(1)我们提交一个任务,任务就叫Application,主函数是Drver中的main()函数
(2)构建SparkApplication的运行环境SparkContext,SC向资源管理器(可以是Standalone、Mesos(超大集群)或者Yarn)注册并申请运行Exector的资源;
(3)SparkContext构建DAG图,并将DAG图分界成Stage,并把TaskSet发送给TaskSheduler。
(4)Task Scheduler通过ClusterManger申请计算资源,比如在集群中某个Worker上启动专属的Exector,并且分配CPU、内存资源。
(5)然后启动StandaloneExcetorBackend;顺便初始化好一个线程池;接着就是在Exector中运行task任务。
(6)StandaloneExecutorBackend向Driver(SparkContext)注册,这样Driver就知道哪些Executor为他进行服务了;到这个时候其实我们的初始化过程基本完成了,我们开始执行transformation的代码,但是代码并不会真正的运行,直到我们遇到一个action操作。此时会生产一个job任务,并划分stage。
(7)Task在Exector上运行,并向SparkContext报告,运行完毕释放所有资源。
运行图如下所示:
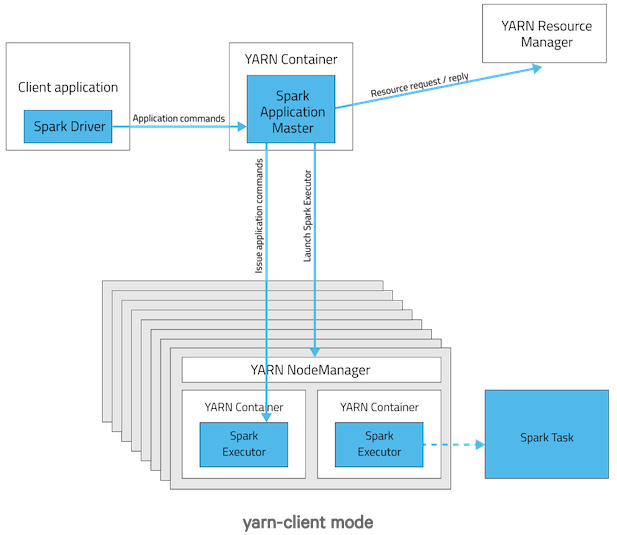
3.2 Spark on Yarn的Yarn-Client运行过程
Yarn-Client模式中,Driver在客户端本地运行,这种模式可以使得Spark Application和客户端进行交互,因为Driver在客户端,所以可以通过webUI访问Driver的状态,默认是http://xxx:4040访问,而YARN通过http:// xxx:8088访问。
YARN-client的工作流程分为以下几个步骤:
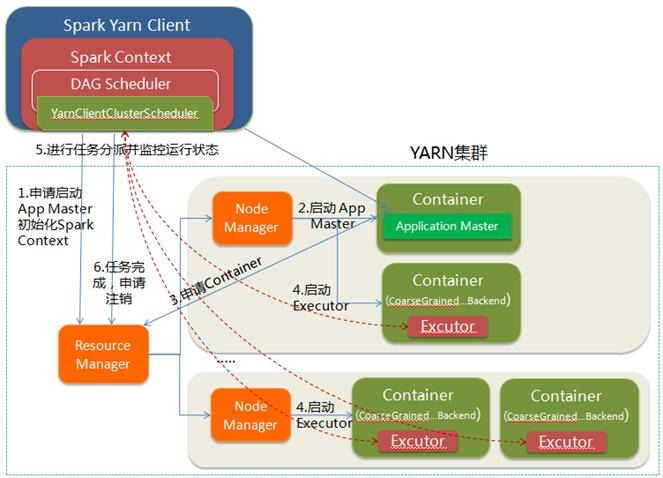
(1)Spark Yarn Client向YARN的ResourceManager申请启动Application Master。同时在SparkContent初始化中将创建DAGScheduler和TasKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend;
(2)ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派;
(3)Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container);
(4)一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
(5)Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
(6)应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。
配图说明
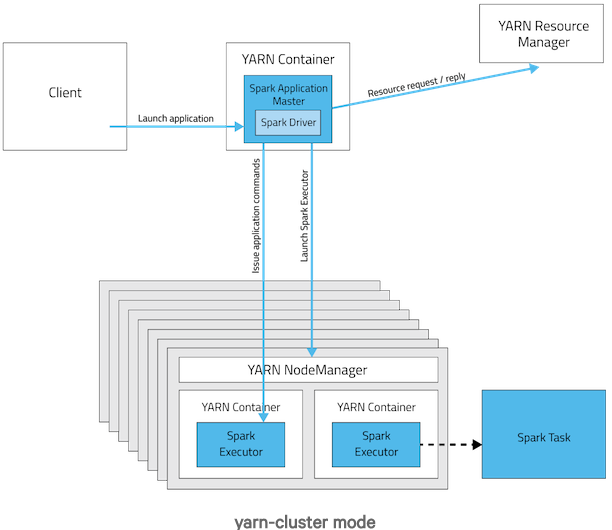
3.3 Yarn-Cluster运行模式
在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:第一个阶段是把Spark的Driver作为一个ApplicationMaster在YARN集群中先启动;第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成。
YARN-cluster的工作流程分为以下几个步骤:
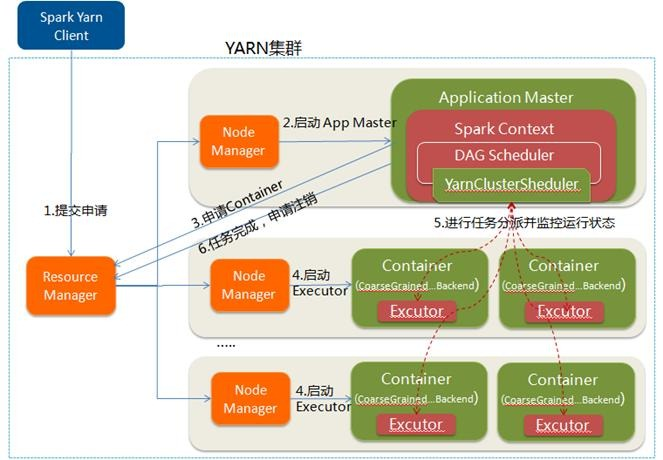
1. Spark Yarn Client向YARN中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等;
2. ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化;
3. ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束;
4. 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler进行任务的调度,其中YarnClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等;
5. ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6. 应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己
配图说明:
3.4 YARN-Client 与 YARN-Cluster 区别
理解YARN-Client和YARN-Cluster深层次的区别之前先清楚一个概念:Application Master。在YARN中,每个Application实例都有一个ApplicationMaster进程,它是Application启动的第一个容器。它负责和ResourceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。从深层次的含义讲YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别。
1、YARN-Cluster模式下,Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业;
2、YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开。
Spark的任务提交和执行流程概述的更多相关文章
- 一个 Spark 应用程序的完整执行流程
一个 Spark 应用程序的完整执行流程 1.编写 Spark Application 应用程序 2.打 jar 包,通过 spark-submit 提交执行 3.SparkSubmit 提交执行 4 ...
- JavaScript 引擎 V8 执行流程概述
本文首发于 vivo互联网技术 微信公众号 链接:https://mp.weixin.qq.com/s/t__Jqzg1rbTlsCHXKMwh6A作者:赖勇高 本文主要讲解的是V8的技术,是V8的入 ...
- Spark源码分析之一:Job提交运行总流程概述
Spark是一个基于内存的分布式计算框架,运行在其上的应用程序,按照Action被划分为一个个Job,而Job提交运行的总流程,大致分为两个阶段: 1.Stage划分与提交 (1)Job按照RDD之间 ...
- ovn-kubernetes执行流程概述
Master部分 1.master初始化 以node name创建一个distributed logical router 创建两个load balancer用于处理east-west traffic ...
- Spark源码剖析 - 任务提交与执行
1. 任务概述 任务提交与执行过程: 1) build operator DAG:此阶段主要完成RDD的转换及DAG的构建: 2) split graph into stages of tasks:此 ...
- Spark Streaming 执行流程
Spark Streaming 是基于spark的流式批处理引擎,其基本原理是把输入数据以某一时间间隔批量的处理,当批处理间隔缩短到秒级时,便可以用于处理实时数据流. 本节描述了Spark Strea ...
- spark 源码分析之二十一 -- Task的执行流程
引言 在上两篇文章 spark 源码分析之十九 -- DAG的生成和Stage的划分 和 spark 源码分析之二十 -- Stage的提交 中剖析了Spark的DAG的生成,Stage的划分以及St ...
- 大数据学习day23-----spark06--------1. Spark执行流程(知识补充:RDD的依赖关系)2. Repartition和coalesce算子的区别 3.触发多次actions时,速度不一样 4. RDD的深入理解(错误例子,RDD数据是如何获取的)5 购物的相关计算
1. Spark执行流程 知识补充:RDD的依赖关系 RDD的依赖关系分为两类:窄依赖(Narrow Dependency)和宽依赖(Shuffle Dependency) (1)窄依赖 窄依赖指的是 ...
- Spark修炼之道(进阶篇)——Spark入门到精通:第九节 Spark SQL执行流程解析
1.总体执行流程 使用下列代码对SparkSQL流程进行分析.让大家明确LogicalPlan的几种状态,理解SparkSQL总体执行流程 // sc is an existing SparkCont ...
随机推荐
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 显示代码:电脑程序输出: Sample output
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- Mysql 锁定 读情况
在一个事务中,标准的SELECT语句是不会加锁,但是有两种情况例外. SELECT ... LOCK IN SHARE MODE SELECT ... FOR UPDATE SELECT ... LO ...
- linux#自启动脚本
编写脚本: /etc/init.d/myscriptname # chkconfig: # description: 描述信息,描述信息,上面的90表示在众多开机启动脚本的优先级,10表示在众多关机启 ...
- 「CF1037D」Valid BFS?
传送门 Luogu 解题思路 考虑直接模拟 \(\text{BFS}\) 的过程. 对于每一个节点的儿子,先遍历在输入序列中靠前的,判断 \(\text{BFS}\) 是否匹配即可. 细节注意事项 注 ...
- SpringBoot项目中自定义注解的使用
1.定义注解接口 @Documented @Retention(RUNTIME) @Target(METHOD) public @interface MyLog { String value() ...
- 笔记||Python3进阶之读取和写入yaml配置文件
yaml是专门用来写配置文件的语言,简洁强大,远比JSON格式方便,yaml在python语言中有PyYAML安装包. - 首先需要pip安装:pip install pyyaml - yaml基本语 ...
- OC中四种遍历方式
标准的C语言for循环.Objective-C 1.0出现的NSEnumerator.Objective-C 1.0出现的for in快速遍历.块遍历. 遍历的话,一般是NSArray.NSDicti ...
- WebGL 渲染管线
WebGL 是以 OpenGL ES 2.0 为基础的 3D 编程应用接口. WebGL依赖GPU的图形渲染能力,即依赖硬件设备,所以其渲染流程和GPU内部的渲染管线是相符的.渲染管线的作用是将3D模 ...
- Q12问题
1.我知道公司对我的工作要求吗? 2.我有做好我的工作所需要的材料和设备吗? 3.在工作中,我每天都有机会做我最擅长做的事吗? 4.在过去的七天里,我因工作出色而受到表扬吗? 5.我觉得我的主管或同事 ...
- SIAMATIC S7-1200 中通过 Modbus RTU 如何读取地址范围 9999 到 65535 的输入字
原文地址 说明 除了需要 STEP 7 >= V13 SP1 (TIA Portal) 的软件,还需要 S7-1200 CPU 固件版本 >= V4 (文章编号: 6ES721x-1xx4 ...