HashMap源码和并发异常问题分析
要点源码分析
- HashMap允许键值对为null;HashTable则不允许,会报空指针异常;
HashMap<String, String> map= new HashMap<>(2);
map.put(null,null);
map.put("1",null); HashMap初始容量是16,扩容方式为2N:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16,默认大小
//元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置
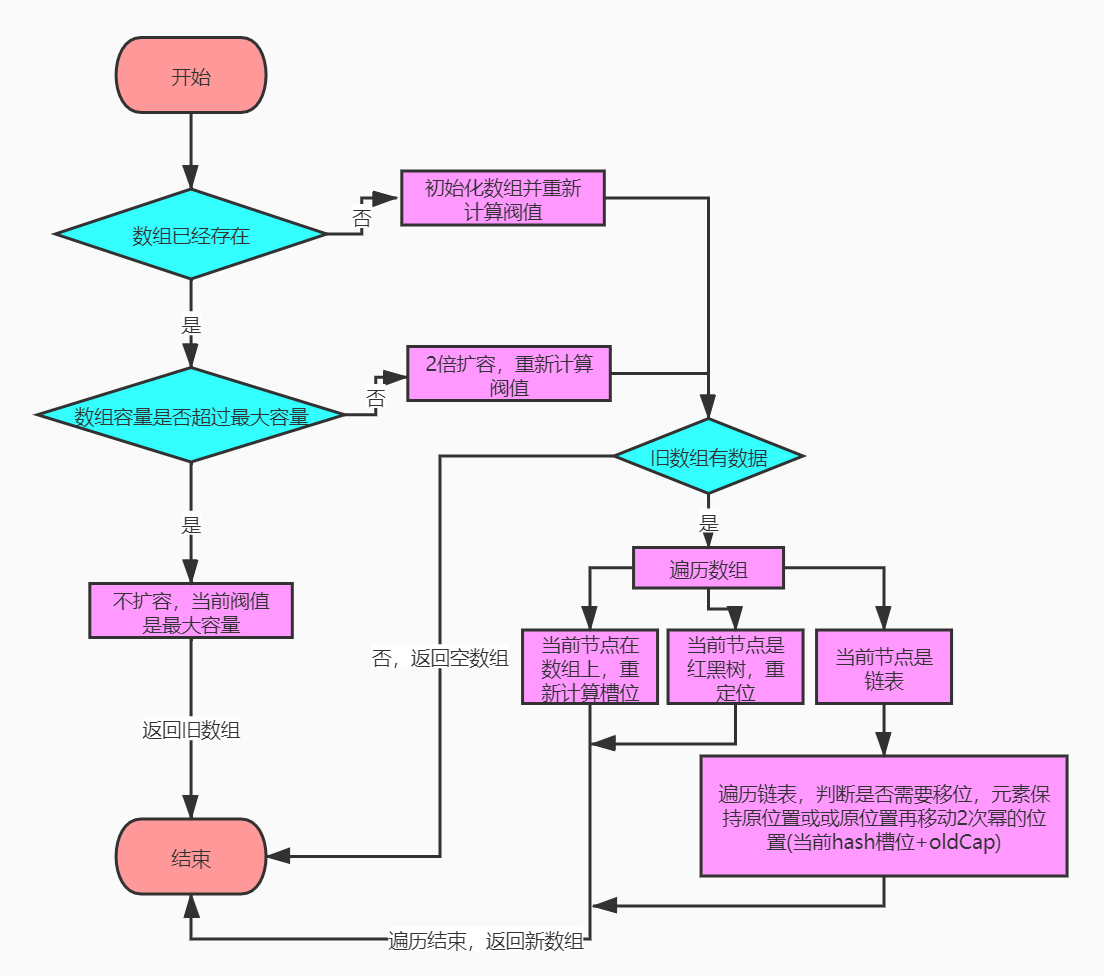
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;//原先的数组,旧数组
int oldCap = (oldTab == null) ? 0 : oldTab.length;//旧数组长度
int oldThr = threshold;//阀值
int newCap, newThr = 0;
if (oldCap > 0) {//数组已经存在不需要进行初始化
if (oldCap >= MAXIMUM_CAPACITY) {//旧数组容量超过最大容量限制,不扩容直接返回旧数组
threshold = Integer.MAX_VALUE;
return oldTab;
}
//进行2倍扩容后的新数组容量小于最大容量和旧数组长度大于等于16
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold,重新计算阀值为原来的2倍
}
//初始化数组
else if (oldThr > 0) // initial capacity was placed in threshold,有阀值,初始容量的值为阀值
newCap = oldThr;
else { // zero initial threshold signifies using defaults,没有阀值
newCap = DEFAULT_INITIAL_CAPACITY;//初始化的默认容量
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//重新计算阀值
}
//有阀值,定义了新数组的容量,重新计算阀值
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;//赋予新阀值
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//创建新数组
table = newTab;
if (oldTab != null) {//如果旧数组有数据,进行数据移动,如果没有数据,返回一个空数组
for (int j = 0; j < oldCap; ++j) {//对旧数组进行遍历
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;//将旧数组的所属位置的旧元素清空
if (e.next == null)//当前节点是在数组上,后面没有链表,重新计算槽位
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)//当前节点是红黑树,红黑树重定位
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order,当前节点是链表
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
//遍历链表
do {
next = e.next;
if ((e.hash & oldCap) == 0) {//不需要移位
if (loTail == null)//头节点是空的
loHead = e;//头节点放置当前遍历到的元素
else
loTail.next = e;//当前元素放到尾节点的后面
loTail = e;//尾节点重置为当前元素
}
else {//需要移位
if (hiTail == null)//头节点是空的
hiHead = e;//头节点放置当前遍历到的元素
else
hiTail.next = e;//当前元素放到尾节点的后面
hiTail = e;//尾节点重置为当前元素
}
} while ((e = next) != null);
if (loTail != null) {//不需要移位
loTail.next = null;
newTab[j] = loHead;//原位置
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;//移动到当前hash槽位 + oldCap的位置,即在原位置再移动2次幂的位置
}
}
}
}
}
return newTab;
}当前节点是数组,后面没有链表,重新计算槽位:位与操作的效率比效率高
定位槽位:e.hash & (newCap - 1)
我们用长度16, 待插入节点的hash值为21举例:
(1)取余: 21 % 16 = 5
(2)位与:
21: 0001 0101
&
15: 0000 1111
5: 0000 0101遍历链表,对链表节点进行移位判断:(e.hash & oldCap) == 0
比如oldCap=8,hash是3,11,19,27时,
(1)JDK1.8中(e.hash & oldCap)的结果是0,8,0,8,这样3,19组成新的链表,index为3;而11,27组成新的链表,新分配的index为3+8;
(2)JDK1.7中是(e.hash & newCap-1),newCap是oldCap的两倍,也就是3,11,19,27对(16-1)与计算,也是0,8,0,8,但由于是使用了单链表的头插入方式,即同一位置上新元素总会被放在链表的头部位置;这样先放在一个索引上的元素终会被放到Entry链的尾部(如果发生了hash冲突的话),这样index为3的链表是19,3,index为3+8的链表是 27,11。
也就是说1.7中经过resize后数据的顺序变成了倒叙,而1.8没有改变顺序。
构造方法:
public HashMap() {//默认初始容量为16,加载因子为0.75
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(int initialCapacity) {//指定初始容量为initialCapacity
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
static final int MAXIMUM_CAPACITY = 1 << 30;//最大容量 //当size到达threshold这个阈值时会扩容,下一次扩容的值,根据capacity * load factor进行计算,
int threshold;
/**由于HashMap的capacity都是2的幂,因此这个方法用于找到大于等于initialCapacity的最小的2的幂(initialCapacity如果就是2的幂,则返回的还是这个数)
* 通过5次无符号移位运算以及或运算得到:
* n第一次右移一位时,相当于将最高位的1右移一位,再和原来的n取或,就将最高位和次高位都变成1,也就是两个1;
* 第二次右移两位时,将最高的两个1向右移了两位,取或后得到四个1;
* 依次类推,右移16位再取或就能得到32个1;
* 最后通过加一进位得到2^n。
* 比如initialCapacity = 10 ,那就返回16, initialCapacity = 17,那么就返回32
* 10的二进制是1010,减1就是1001
* 第一次右移取或: 1001 | 0100 = 1101 ;
* 第二次右移取或: 1101 | 0011 = 1111 ;
* 第三次右移取或: 1111 | 0000 = 1111 ;
* 第四次第五次同理
* 最后得到 n = 1111,返回值是 n+1 = 2 ^ 4 = 16 ;
* 让cap-1再赋值给n的目的是另找到的目标值大于或等于原值。这是为了防止,cap已经是2的幂。如果cap已经是2的幂,又没有执行这个减1操作,则执行完后面的几条无符号右移操作之后,返回的capacity将是这个cap的2倍。
* 例如十进制数值8,二进制为1000,如果不对它减1而直接操作,将得到答案10000,即16。显然不是结果。减1后二进制为111,再进行操作则会得到原来的数值1000,即8。
* 问题:tableSizeFor()最后赋值给threshold,但threshold是根据capacity * load factor进行计算的,这是不是有问题?
* 注意:在构造方法中,并没有对table这个成员变量进行初始化,table的初始化被推迟到了put方法中,在put方法中会对threshold重新计算。
* 问题:既然put会重新计算threshold,那么在构造初始化threshold的作用是什么?
* 答:在put时,会对table进行初始化,如果threshold大于0,会把threshold当作数组的长度进行table的初始化,否则创建的table的长度为16。
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
public HashMap(int initialCapacity, float loadFactor) {//指定初始容量和加载因子
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)//大于最大容量,设置为最大容量
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))//加载因子小于等于0或为NaN抛出异常
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);//阀值
}
- HashMap允许键值对为null;HashTable则不允许,会报空指针异常;
put/get/remove/containsKey/containsValue/putAll/clear/replace源码分析
put:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}hash计算:key的hash值高16位不变,低16位与高16位异或作为key的最终hash值。(h >>> 16,表示无符号右移16位,高位补0,任何数跟0异或都是其本身,因此key的hash值高16位不变。)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}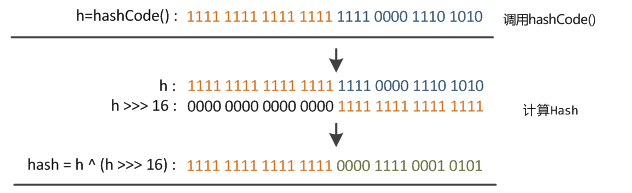
之所以要无符号右移16位,是跟table的下标有关,上面的扩容中对数组槽位的重新计算方式是:e.hash & (newCap - 1),假如newCap=16,从下图可以看出:table的下标仅与hash值的低n位有关,hash值的高位都被与操作置为0了,只有hash值的低4位参与了运算。

putVal:

final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//没有数组可以存放元素进行初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//计算的槽位为空,元素存放到该位置
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {//hash冲突了
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;//同一个key,对value进行覆盖
else if (p instanceof TreeNode)//树节点
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {//链表
// 循环,直到链表中的某个节点为null,或者某个节点hash值和给定的hash值一致且key也相同,则停止循环。
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {//next为空,将添加的元素置为next
p.next = newNode(hash, key, value, null);
//链表长度达到了阀值TREEIFY_THRESHOLD=8,即链表长度达到了7
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 如果链表长度达到了8,且数组长度小于64,那么就重新散列resize(),如果大于64,则创建红黑树
treeifyBin(tab, hash);
//结束循环
break;
}
//节点hash值和给定的hash值一致且key也相同,停止循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//如果给定的hash值不同或者key不同。将next值赋给p,为下次循环做铺垫。即结束当前节点,对下一节点进行判断
p = e;
}
}
//如果e不是null,该元素存在了(也就是key相等)
if (e != null) { // existing mapping for key
// 取出该元素的值
V oldValue = e.value;
// 如果 onlyIfAbsent 是 true,就不用改变已有的值;如果是false(默认),或者value是null,将新的值替换老的值
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//什么都不做
afterNodeAccess(e);
//返回旧值
return oldValue;
}
}
//修改计数器+1,为迭代服务
++modCount;
//达到了阀值,需要扩容
if (++size > threshold)
resize();
//什么都不做
afterNodeInsertion(evict);
//返回null
return null;
}
get:
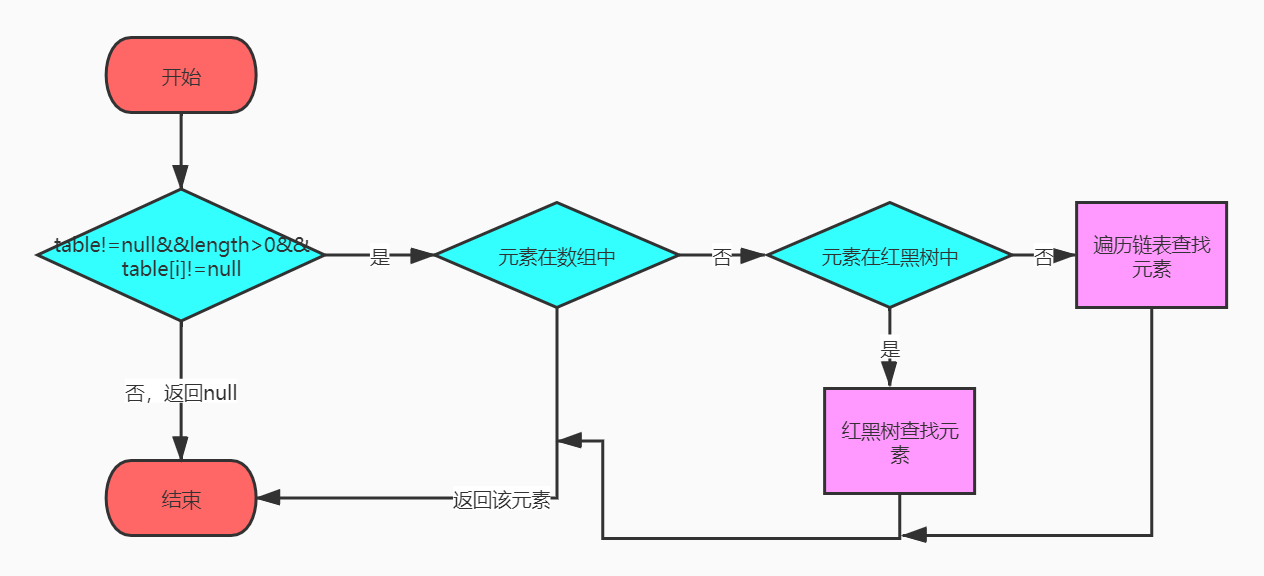
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//数组不为null,数组长度大于0,根据hash计算出来的槽位的元素不为null
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//查找的元素在数组中,返回该元素
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {//查找的元素在链表或红黑树中
if (first instanceof TreeNode)//元素在红黑树中,返回该元素
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {//遍历链表,元素在链表中,返回该元素
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
//找不到返回null
return null;
}remove:
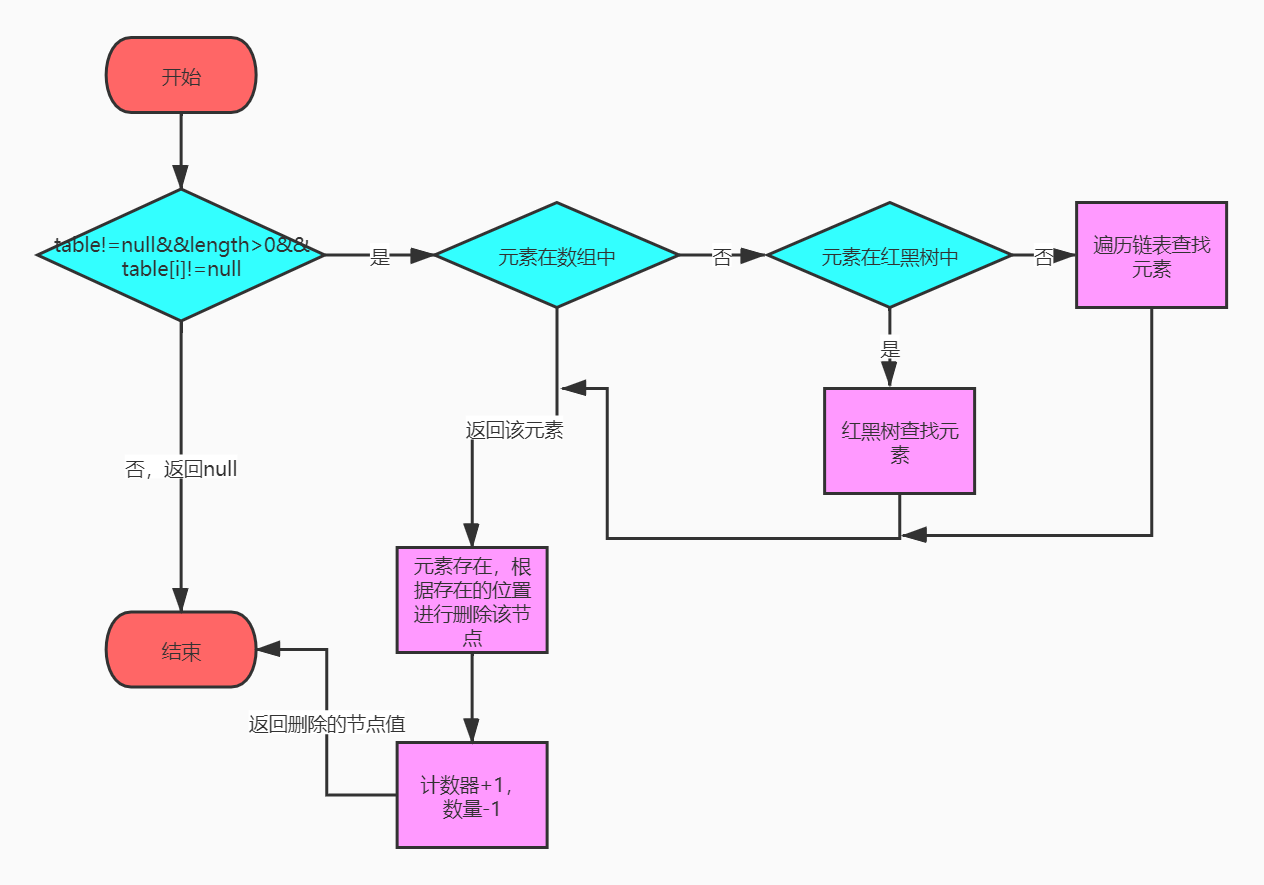
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//数组不为null,数组长度大于0,要删除的元素计算的槽位有元素
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
//当前元素在数组中
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
//元素在红黑树或链表中
else if ((e = p.next) != null) {
if (p instanceof TreeNode)//是树节点,从树种查找节点
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
//hash相同,并且key相同,找到节点并结束
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);//遍历链表
}
}
//找到节点了,并且值也相同
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)//是树节点,从树中移除
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)//节点在数组中,
tab[index] = node.next;//当前槽位置为null,node.next为null
else//节点在链表中
p.next = node.next;//将节点删除
++modCount;//修改计数器+1,为迭代服务
--size;//数量-1
afterNodeRemoval(node);//什么都不做
return node;//返回删除的节点
}
}
return null;
}containsKey:
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;//查看上面的get的getNode
}containsValue:
public boolean containsValue(Object value) {
Node<K,V>[] tab; V v;
//数组不为null并且长度大于0
if ((tab = table) != null && size > 0) {
for (int i = 0; i < tab.length; ++i) {//对数组进行遍历
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
//当前节点的值等价查找的值,返回true
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
}
}
}
return false;//找不到返回false
}putAll:
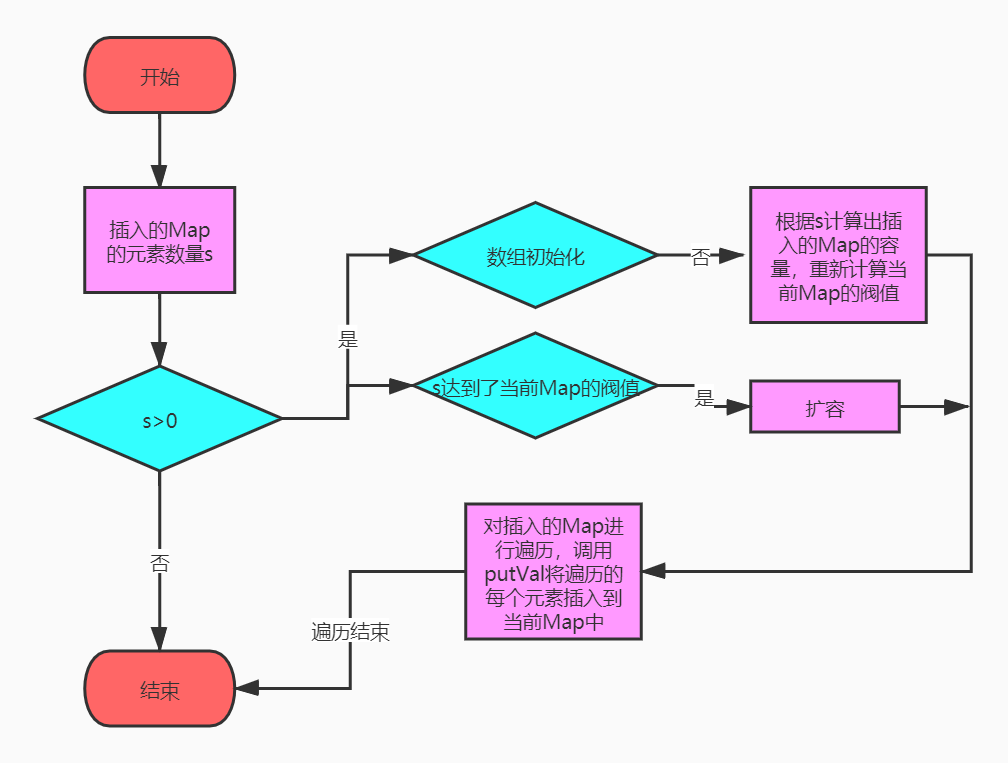
public void putAll(Map<? extends K, ? extends V> m) {
putMapEntries(m, true);
}
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();//获得插入整个m的元素数量
if (s > 0) {
if (table == null) { // pre-size,当前map还没有初始化数组
float ft = ((float)s / loadFactor) + 1.0F;//m的容量
//判断容量是否大于最大值MAXIMUM_CAPACITY
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
//容量达到了阀值,比如插入的m的定义容量是16,但当前map的阀值是12,需要对当前map进行重新计算阀值
if (t > threshold)
threshold = tableSizeFor(t);//重新计算阀值
}
else if (s > threshold)//存放的数量达到了阀值,扩容
resize();
//对m进行遍历,放到当前map中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}clear:
public void clear() {
Node<K,V>[] tab;
modCount++;//修改计数器+1,为迭代服务
if ((tab = table) != null && size > 0) {
size = 0;//将数组的元素格式置为0,然后遍历数组,将每个槽位的元素置为null
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
}
}replace:
public boolean replace(K key, V oldValue, V newValue) {
Node<K,V> e; V v;
//根据hash计算得到槽位的节点不为null,并且节点的值等于旧值
if ((e = getNode(hash(key), key)) != null &&
((v = e.value) == oldValue || (v != null && v.equals(oldValue)))) {
e.value = newValue;//覆盖旧值
afterNodeAccess(e);
return true;
}
return false;
} public V replace(K key, V value) {
Node<K,V> e;
//根据hash计算得到槽位的节点不为null
if ((e = getNode(hash(key), key)) != null) {
V oldValue = e.value;//节点的旧值
e.value = value;//覆盖旧值
afterNodeAccess(e);
return oldValue;//返回旧值
}
return null;//找不到key对应的节点
}
问题分析
HashMap遍历中修改出现ConcurrentModificationException并发修改异常解析:
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.HashMap$HashIterator.nextNode(HashMap.java:1442)
at java.util.HashMap$KeyIterator.next(HashMap.java:1466)- 遍历的几种方式:
//====1=====
for (String key : map.keySet()) {
System.out.println(map.get(key));
map.remove(key);
}
//编译后
Iterator var2 = map.keySet().iterator();
while(var2.hasNext()) {
String key = (String)var2.next();
System.out.println((String)map.get(key));
map.remove(key);
}
//====2=====
for(Map.Entry<String,String> entry:map.entrySet()){
System.out.println(entry.getKey()+":"+entry.getValue());
map.remove(entry.getKey());
}
//编译后
Iterator var2 = map.entrySet().iterator();
while(var2.hasNext()) {
Map.Entry<String, String> entry = (Map.Entry)var2.next();
System.out.println((String)entry.getKey() + ":" + (String)entry.getValue());
map.remove(entry.getKey());
}
//====3=====
for(String values:map.values()){
System.out.println(values);
map.remove(values);
}
//编译后
Iterator var2 = map.values().iterator();
while(var2.hasNext()) {
String values = (String)var2.next();
System.out.println(values);
map.remove(values);
} - 解析:从上面编译后的代码可以看到,hasNext -> next
//====1=====
final class KeySet extends AbstractSet<K> {
public final Iterator<K> iterator() { return new KeyIterator(); }
}
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }//调用HashIterator的nextNode()
}
abstract class HashIterator {
HashIterator() {//构造方法
expectedModCount = modCount;//将当前的期望计数器值进行赋值
Node<K,V>[] t = table;//得到数组
current = next = null;//当前节点和下一个节点为null
index = 0;//当前节点的下标
//通过while循环,得到数组中的第一个不为空的元素下标以及值,并将此元素值赋给next
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
}
}
public final boolean hasNext() {
return next != null;
}
//返回下一节点
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;//返回的节点
//问题在这里,计数器跟期望的计数器不一致导致异常,每次的remove和put都会重新对计数器进行+1,但期望的计数器在HashIterator初始化时就定义了,后面的调用HashIterator的nextNode就没有重新对期望的计数器进行重置
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)//节点为null返回异常
throw new NoSuchElementException();
//当前节点遍历结束,while遍历其他节点的,将下一节点赋予next,直到数组为空结束
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
}
//====2=====
final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public final Iterator<Map.Entry<K,V>> iterator() {
return new EntryIterator();
}
}
final class EntryIterator extends HashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }//调用HashIterator的nextNode()
}
//====3=====
final class Values extends AbstractCollection<V> {
public final Iterator<V> iterator() { return new ValueIterator(); }
}
final class ValueIterator extends HashIterator
implements Iterator<V> {
public final V next() { return nextNode().value; }//调用HashIterator的nextNode()
} 解决方式:从下面的代码可以看出,将map.keySet转换为ArrayList后,获取到的是ArrayList的迭代器,这样迭代next和删除remove操作的是不同的对象(ArrayList和HashMap),没有并发修改异常,上面的三种方式迭代和删除的对象都是HashMap,导致出现问题。
ArrayList<String> strings = new ArrayList<>(map.keySet());
for(String key : strings){
System.out.println(map.get(key));
System.out.println(map.remove(key)); }
//编译后
ArrayList<String> strings = new ArrayList(map.keySet());
Iterator var3 = strings.iterator(); while(var3.hasNext()) {
String key = (String)var3.next();
System.out.println((String)map.get(key));
System.out.println((String)map.remove(key));
}- 或可以使用ConcurrentHashMap解决并发修改异常:使用ConcurrentHashMap后上面的三种方式都不会出现并发异常问题。
ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>(2);
- 或可以使用ConcurrentHashMap解决并发修改异常:使用ConcurrentHashMap后上面的三种方式都不会出现并发异常问题。
- 遍历的几种方式:
ArrayList的遍历中修改同样出现ConcurrentModificationException并发修改异常:
- 解析:使用Iterator迭代器(增强for循环也是使用Iterator)在next进行判断,然后使用ArrayList的add()、remove()进行修改操作
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
final void checkForComodification() {
//判断计数器和期望的计数器是否一致,由于ArrayList的add()、remove()、trimToSize()都会对modCount+1,导致遍历时修改会抛出异常
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
} 解决方式:
- 直接使用普通for同时遍历和修改:
for(int i=0;i<list.size();i++){
String str = list.get(i);
if("str".equals(str)){
list.remove(str);
i= i-1;
}
}
public E get(int index) {
rangeCheck(index);//检查索引范围
return elementData(index);//直接从数组中获取元素
}
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
E elementData(int index) {
return (E) elementData[index];
} - 使用ListIterator列表迭代器进行遍历时添加使用ListIterator的add()(只有添加操作),替换ArrayList的add():
//====案例====
ArrayList list = new ArrayList();
list.add(1);
ListIterator lit = list.listIterator();
while (lit.hasNext()){
System.out.println(lit.next());
lit.add(2);
}
//====解析====
public ListIterator<E> listIterator() {
return new ListItr(0);
}
private class ListItr extends Itr implements ListIterator<E> {
public void add(E e) {
checkForComodification(); try {
int i = cursor;
ArrayList.this.add(i, e);
cursor = i + 1;
lastRet = -1;
//将期望的计数器更新为修改计数器值,这样下次next判断就不会出现问题
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
} - 使用Iterator迭代器进行遍历时删除使用Iterator的remove()(只有删除操作),替换ArrayList的remove():
//====案例====
ArrayList list = new ArrayList();
list.add(1);
list.add(2);
Iterator lit = list.iterator();
while (lit.hasNext()){
Integer i = (Integer)lit.next();
if(1==i) {
lit.remove();
}
}
System.out.println(list);
//====解析====
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
//删除当前遍历到的元素
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
//将期望的计数器更新为修改计数器值,这样下次next判断就不会出现问题
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
}
- 直接使用普通for同时遍历和修改:
- 解析:使用Iterator迭代器(增强for循环也是使用Iterator)在next进行判断,然后使用ArrayList的add()、remove()进行修改操作
HashMap源码和并发异常问题分析的更多相关文章
- 【源码】HashMap源码及线程非安全分析
最近工作不是太忙,准备再读读一些源码,想来想去,还是先从JDK的源码读起吧,毕竟很久不去读了,很多东西都生疏了.当然,还是先从炙手可热的HashMap,每次读都会有一些收获.当然,JDK8对HashM ...
- HashMap源码剖析及实现原理分析(学习笔记)
一.需求 最近开发中,总是需要使用HashMap,而为了更好的开发以及理解HashMap:因此特定重新去看HashMap的源码并写下学习笔记,以便以后查阅. 二.HashMap的学习理解 1.我们首先 ...
- HashMap源码深度剖析,手把手带你分析每一行代码,包会!!!
HashMap源码深度剖析,手把手带你分析每一行代码! 在前面的两篇文章哈希表的原理和200行代码带你写自己的HashMap(如果你阅读这篇文章感觉有点困难,可以先阅读这两篇文章)当中我们仔细谈到了哈 ...
- HashMap源码分析(一)
前言:相信不管在生产过程中还是面试过程中,HashMap出现的几率都非常的大,因此有必要对其源码进行分析,但要注意的是jdk1.8对HashMap进行了大量的优化,因此笔者会根据不同版本对HashMa ...
- HashMap源码分析-jdk1.7
注:转载请注明出处!!!!!!!这里咱们看的是JDK1.7版本的HashMap 学习HashMap前先知道熟悉运算符合 *左移 << :就是该数对应二进制码整体左移,左边超出的部分舍弃,右 ...
- 最通俗易懂的 HashMap 源码分析解读
HashMap 作为最常用的集合类之一,有必要深入浅出的了解一下.这篇文章会深入到 HashMap 源码,刨析它的存储结构以及工作机制. 1. HashMap 的存储结构 HashMap 的数据存储结 ...
- HashMap源码分析
最近一直特别忙,好不容易闲下来了.准备把HashMap的知识总结一下,很久以前看过HashMap源码.一直想把集合类的知识都总结一下,加深自己的基础.我觉的java的集合类特别重要,能够深刻理解和应用 ...
- Java中的HashMap源码记录以及并发环境的几个问题
HashMap源码简单分析: 1 一切需要从HashMap属性字段说起: /** The default initial capacity - MUST be a power of two. 初始容量 ...
- Java容器之HashMap源码分析
在java的容器框架中,hashMap是最常用的容器之一,下面我们就来深入了解下它的数据结构和实现原理 先看下HashMap的继承结构图 下面针对各个实现类的特点进行下说明:1)HashMap: 它是 ...
随机推荐
- Spring Boot 教程(2) - Mybatis
Spring Boot 教程 - Mybatis 1. 什么是Mybatis? MyBatis 是一款优秀的持久层框架,它支持自定义 SQL.存储过程以及高级映射.MyBatis 免除了几乎所有的 J ...
- var、let、const三者的区别
var定义的变量,没有块的概念,可以跨块访问, 不能跨函数访问. let定义的变量,只能在块作用域里访问,不能跨块访问,也不能跨函数访问. const用来定义常量,使用时必须初始化(即必须赋值),只能 ...
- Linux,Mac下MySQL的安装及一些知识点的整理
Linux下载安装 在服务器上下载的话,需要安装Mysql5.7相关的yum源 wget https://dev.mysql.com/get/mysql80-community-release-el7 ...
- 怎样实现登录?| Cookie or JWT
先问小伙伴们一个问题,登录难吗?"登录有什么难得?输入用户名和密码,后台检索出来,校验一下不就行了."凡是这样回答的小伙伴,你明显就是产品思维,登录看似简单,用户名和密码,后台校验 ...
- .net core 上传大文件
using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Thr ...
- 腾讯云EMR大数据实时OLAP分析案例解析
OLAP(On-Line Analytical Processing),是数据仓库系统的主要应用形式,帮助分析人员多角度分析数据,挖掘数据价值.本文基于QQ音乐海量大数据实时分析场景,通过QQ音乐与腾 ...
- Protocol Buffers工作原理
这里记录一下学习与使用Protocol Buffer的笔记,优点缺点如何使用这里不再叙述,重点关注与理解Protocol Buffers的工作原理,其大概实现. 我们经常使用Protocol Buff ...
- Java实现 蓝桥杯 算法训练 寻找数组中最大值
算法训练 寻找数组中最大值 时间限制:1.0s 内存限制:512.0MB 提交此题 问题描述 对于给定整数数组a[],寻找其中最大值,并返回下标. 输入格式 整数数组a[],数组元素个数小于1等于10 ...
- java实现拉丁方块填数字
"数独"是当下炙手可热的智力游戏.一般认为它的起源是"拉丁方块",是大数学家欧拉于1783年发明的. 如图[1.jpg]所示:6x6的小格被分为6个部分(图中用 ...
- Java实现 蓝桥杯 历届试题 数字游戏
问题描述 栋栋正在和同学们玩一个数字游戏. 游戏的规则是这样的:栋栋和同学们一共n个人围坐在一圈.栋栋首先说出数字1.接下来,坐在栋栋左手边的同学要说下一个数字2.再下面的一个同学要从上一个同学说的数 ...