浅谈字典树Trie
\(\;\)
本文是作者学习《算法竞赛进阶指南》的所得,有些语言是摘自其中。
\(\;\)
基础知识
定义
\(\;\)
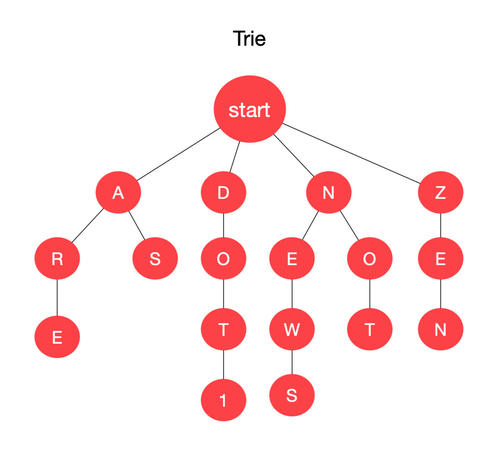
字典树(Trie):是一种支持字符串查询的多叉树结构。其中的每个节点,都有字符指针,指向了它的若干个儿子。
如图:
\(\;\)
空间复杂度
\(\;\)
\(O(NC)\)
其中\(N\)是节点个数,\(C\)是字符集的大小。
\(\;\)
Insert
\(\;\)
找到这个字符串在Trie中的最大前缀,把前缀后面的部分插到这个节点的后面
code
void Insert(char* str,int root)
{
int len = strlen(str);
for(int i=0;i<len;i++)
{
int c = str[i] - 'a'; //转成数字存储
if(!trie[root][c]) trie[root][c] = ++idx; //若指针为空,就新建一个指向c的指针
root = trie[root][c]; //然后继续往下遍历
}
}
Query
\(\;\)
不断地通过字符指针向下检索。直到字符指针为空,或者查询完毕为止。
code
bool Query(char* str,int root)
{
int len = strlen(str);
for(int i=0;i<len;i++)
{
int c = str[i] - 'a';
root = trie[root][c];
if(root == 0) return false; //若指针为空,则字符串不存在
}
return true;
}
Problem 1
\(\;\)
题意
\(\;\)
有\(n\)个字符串\(S_1,S_2,\cdots,S_n\)。接下来有\(M\)次询问,每次询问给定一个字符串\(T\),求\(S_1-S_n\)有多少个字符串是\(T\)的前缀。
其中输入字符串的总长度不超过\(10^6\)
\(\;\)
做法
\(\;\)
我们把\(S_1,S_2,\cdots,S_n\)这些字符串插到一棵字典树里。(参考Insert操作)。在插入的同时,顺便在每个节点上记录一个\(cnt\),表示多少个字符串在这里结尾。
然后对于每次询问,我们在字典树中查询这个字符串\(T\)。在查询过程中,累加上节点上\(cnt\)所得结果就是答案。
其实相当于对\(T\)的每个前缀算一下贡献。
\(\;\)
code
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1000010;
char str[N];
int n, m, tree[N][26], root, idx, end_cnt[N];
void Insert(char* str,int root)
{
int len = strlen(str);
for(int i=0;i<len;i++)
{
int c = str[i] - 'a';
if(!tree[root][c]) tree[root][c] = ++idx;
root = tree[root][c];
}
end_cnt[root] ++;
}
int Query(char* str,int root)
{
int len = strlen(str), res = 0;
for(int i=0;i<len;i++)
{
int c = str[i] - 'a';
root = tree[root][c];
if(root == 0) break;
res += end_cnt[root];
}
return res;
}
int main()
{
cin >> n >> m;
while( n-- )
{
scanf("%s",str);
Insert(str,root);
}
while( m -- )
{
scanf("%s",str);
printf("%d\n",Query(str,root));
}
return 0;
}
\(\;\)
Problem 2
\(\;\)
题意
\(\;\)
给定一颗\(n\)个节点的树,树的每条边都有一个权值。从中选择两个点\(x,y\)。使得\(x\)到\(y\)的路径上的所有边权\(xor\)(异或)起来,得到的结果最大是多少?
\(n\leq 10^5\),边权\(\leq 2^{31}-1\)
\(\;\)
转化
\(\;\)
单看路径不太好搞,但是有一个比较套路的性质。
我们定义\(d(x)\)表示\(x\)到根节点\(root\)上边权的异或值
可以发现:对于两个点\(x\)到\(y\)路径上的异或值\(=d(x)\;xor\;d(y)\),因为它们\(LCA\)以上的点都被异或没了(\(a\;xor\;a=0\))。
因此我们要算的其实就是:在\(d(1),d(2),\cdots,d(n)\)中选出两个数,使得它们的异或值最大。
\(\;\)
01字典树
\(\;\)
我们可以把每个数拆分成二进制,因此,我们可以把数看作一个长度为\(31\)的\(01\)串(数值较小时在前补前导\(0\)),插到字典树中(其中最低二进制位为叶子节点)。
接下来,我们对于\(d(i)\)在\(Trie\)中进行一次与\(Query\)类似的操作。由于\(xor\)运算相同得\(0\),不同得\(1\)的性质,每次我们都贪心往与当前位相反的指针向下访问。若与当前位相反的指针为空,则只好访问与\(d(i)\)当前位相同的指针。根据这样的贪心策略,我们可以找到最优解。
\(\;\)
code
#include <cstdio>
#include <vector>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100010, M = 3000010;
#define PII pair<int,int>
int n, son[M][2], root, idx, d[N], res;
vector<PII> G[N];
void Dfs(int u,int fa)
{
for(int i=0;i<G[u].size();i++)
{
int v = G[u][i].first;
if(v == fa) continue;
d[v] = G[u][i].second ^ d[u];
Dfs(v,u);
}
}
void Insert(int root,int x)
{
for(int i=30;~i;i--)
{
int s = x >> i & 1;
if(!son[root][s]) son[root][s] = ++idx;
root = son[root][s];
}
}
int Query(int root,int x)
{
int res = 0;
for(int i=30;~i;i--)
{
int s = x >> i & 1;
if(son[root][s ^ 1])
{
res += 1 << i;
root = son[root][s ^ 1];
}
else
{
root = son[root][s];
}
}
return res;
}
int main()
{
cin >> n;
for(int i=1;i<n;i++)
{
int u, v, w;
scanf("%d%d%d",&u,&v,&w);
G[u].push_back( make_pair (v, w) );
G[v].push_back( make_pair (u, w) );
}
Dfs(1,0);
for(int i=1;i<=n;i++)Insert(root, d[i]);
for(int i=1;i<=n;i++)res = max(res, Query(root, d[i]));
printf("%d",res);
return 0;
}
可持久化Trie
\(\;\)
相比于只能维护最新状态的普通的数据结构,可持久化的数据结构可以知道任意时间的历史状态。
它具体是如何实现的?
朴素想法:在每次修改后把整个数据结构\(copy\)一遍。但这样的时间、空间复杂度都是\(O(nm)\)的。(\(n\)为数据结构大小,\(m\)为版本个数)
而可持久化提供了我们一种思想:每次只记录发生变化的部分,这样时间复杂度并无增加,而空间复杂度只会增加与时间同级的规模。
例如:线段树,每次修改至多变化\(log(n)\)个节点,则空间就只会增加\(log(n)\)
下面给大家模拟一下可持久化Trie的过程。
\(\;\)
模拟过程
\(\;\)
1.设当前根节点为\(root\),令\(p=root,idx=0\)
2.建立一个新的节点\(q\),令\(root'=q\)
3.若\(p\)不为空,则对于每种字符\(c\),令\(trie[q][c]=trie[p][c]\)
4.建立一个新的节点:\(trie[q][str_i]=++idx\)。
(而3,4操作其实就是除了字符\(str_i\)外,其他的信息完全相同)
5.令\(p=trie[p][str_i],q=trie[q][str_i]\)(向下遍历)
然后重复\(3-5\)的步骤,直到\(q\)到字符串末尾
图中展示了在可持久化Trie中依次插入\(cat,rat,cab,fry\)的过程。
通过这样的操作,我们就可以得到4个版本的Trie了。
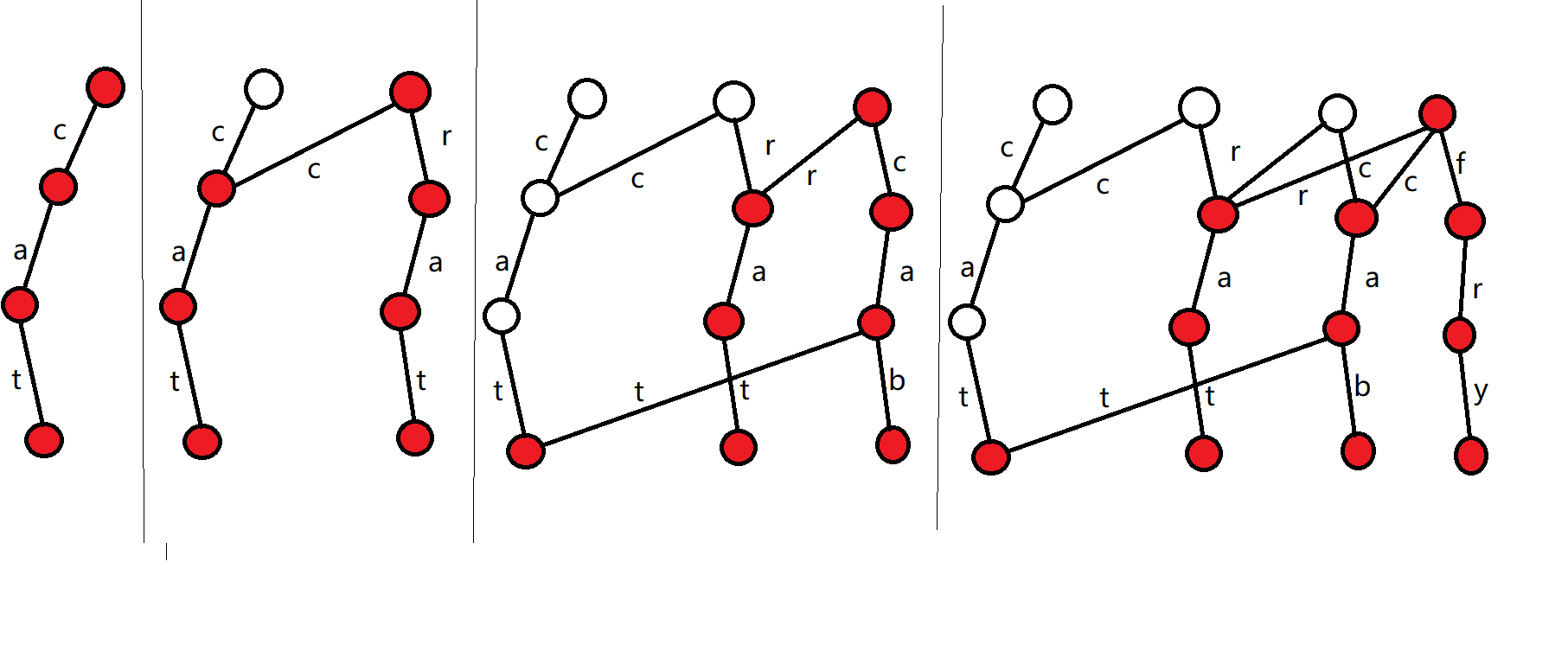
\(\;\)
\(\;\)
Problem 1
\(\;\)
给定一个非负整数序列 \(a\),初始长度为\(n\)。
有 \(m\) 个操作,有以下两种操作类型:
\(A\;\;x\):添加操作,表示在序列末尾添加一个数 \(x\),序列的长度加一。
\(Q\;\;l\;\;r\;\;x\):询问操作,你需要找到一个位置 \(p\),满足\(l\leq p\leq r\),使得:\(a[p] \;xor \;a[p+1]\;xor\; \cdots \;xor\; a[n] \;xor\;x\) 尽可能的大,输出最大值是多少。
\(n,m\leq 3\times 10^5,a[i]\leq 10^7\)
\(\;\)
前缀和
\(\;\)
一般这种一段区间的异或和我们都用前缀和的思路来做。
令\(s_i=a[1]\;xor \;\cdots \;xor\;a[i]\),显然\(a[l] \;xor \;a[l+1]\;xor\; \cdots \;xor\; a[r]=s_{l-1}\;xor\;s_r\)
令\(k=s_n\;xor\;x\)
也就是说:我们要找到一个\(p\;(l-1\leq p\leq r-1),\)使得\(s_p\;xor\;k\)最大。
如果不考虑\(l-1,r-1\)的限制,那么这道题就是我们前面讲的那个\(Problem\;2\)。
但是现在有限制,如何操作?
\(\;\)
可持久化
\(\;\)
这就要用到可持久化的精髓了。既然\(p\leq r-1\),则\(p\)一定是第\(r-1\)个版本中的\(s_i\)。
右端点处理完了,左端点?
由于我们不可以取\(<l-1\)的\(s_i\),则我们记录一个信息\(maxid[u]\),表示\(Trie\)中以\(u\)为根的子树中以某个二进制数为结尾的\(s_i\)的\(i\)最大是多少。
例如:以\(u\)为根的子树中,有以\(s_1,s_3,s_7\)为结尾的节点,则\(maxid[u]=7\)。
那么,在贪心找相反的指针时,如果这颗子树的\(maxid\)大于\(\geq l-1\),说明其中至少有一个数的编号是\(\geq l-1\)的,我们就可以往其中遍历,否则只能往相同的指针方向走了。
由于插入的时候要维护\(maxid\)这个信息,所以我们采用递归的方式来写。
时间复杂度:\(O((n+m)\;log\;10^7)\)
\(\;\)
code
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 600010, M = N * 24;
int n, q, s[N], tree[M][2], root[N], idx, max_id[M];
inline int read(){
int s=0,w=1;
char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-')w=-1;ch=getchar();}
while(ch>='0'&&ch<='9') s=s*10+ch-'0',ch=getchar();
return s*w;
}
void Insert(int Bits, int Now, int Last, int t)
{
if(Bits < 0)
{
max_id[Now] = t;
return;
}
int v = s[t] >> Bits & 1;
if(Last) tree[Now][v ^ 1] = tree[Last][v ^ 1];
tree[Now][v] = ++idx;
Insert(Bits - 1,tree[Now][v],tree[Last][v],t);
max_id[Now] = max(max_id[tree[Now][0]],max_id[tree[Now][1]]);
}
int Query(int Now, int k, int L)
{
for(int i=23;i>=0;i--)
{
int v = k >> i & 1;
if(tree[Now][v ^ 1] && max_id[tree[Now][v ^ 1]] >= L)Now = tree[Now][v ^ 1];
else Now = tree[Now][v];
}
return k ^ s[max_id[Now]];
}
int main()
{
n = read(); q = read();
root[0] = ++idx;
Insert(23,root[0],0,0);
for(int i=1;i<=n;i++)
{
s[i] = read();
s[i] ^= s[i - 1];
root[i] = ++idx;
Insert(23, root[i], root[i-1], i);
}
while( q-- )
{
char op[2];
scanf("%s",op);
if(op[0] == 'A')
{
n ++;
s[n] = read();
s[n] ^= s[n - 1];
root[n] = ++idx;
Insert(23, root[n], root[n - 1], n);
}
else
{
int l, r, x;
l = read(); r = read(); x = read();
int t = s[n] ^ x;
printf("%d\n",Query(root[r - 1], t, l - 1));
}
}
return 0;
}
浅谈字典树Trie的更多相关文章
- 浅谈可持久化Trie与线段树的原理以及实现(带图)
浅谈可持久化Trie与线段树的原理以及实现 引言 当我们需要保存一个数据结构不同时间的每个版本,最朴素的方法就是每个时间都创建一个独立的数据结构,单独储存. 但是这种方法不仅每次复制新的数据结构需要时 ...
- 浅谈B+树索引的分裂优化(转)
http://www.tamabc.com/article/85038.html 从MySQL Bug#67718浅谈B+树索引的分裂优化 原文链接:http://hedengcheng.com/ ...
- [POJ] #1002# 487-3279 : 桶排序/字典树(Trie树)/快速排序
一. 题目 487-3279 Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 274040 Accepted: 48891 ...
- 浅谈oracle树状结构层级查询之start with ....connect by prior、level及order by
浅谈oracle树状结构层级查询 oracle树状结构查询即层次递归查询,是sql语句经常用到的,在实际开发中组织结构实现及其层次化实现功能也是经常遇到的,虽然我是一个java程序开发者,我一直觉得只 ...
- 浅谈oracle树状结构层级查询测试数据
浅谈oracle树状结构层级查询 oracle树状结构查询即层次递归查询,是sql语句经常用到的,在实际开发中组织结构实现及其层次化实现功能也是经常遇到的,虽然我是一个java程序开发者,我一直觉得只 ...
- 『字典树 trie』
字典树 (trie) 字典树,又名\(trie\)树,是一种用于实现字符串快速检索的树形数据结构.核心思想为利用若干字符串的公共前缀来节约储存空间以及实现快速检索. \(trie\)树可以在\(O(( ...
- 字典树trie学习
字典树trie的思想就是利用节点来记录单词,这样重复的单词可以很快速统计,单词也可以快速的索引.缺点是内存消耗大 http://blog.csdn.net/chenleixing/article/de ...
- 字典树(Trie)详解
详解字典树(Trie) 本篇随笔简单讲解一下信息学奥林匹克竞赛中的较为常用的数据结构--字典树.字典树也叫Trie树.前缀树.顾名思义,它是一种针对字符串进行维护的数据结构.并且,它的用途超级广泛.建 ...
- 字典树(Trie Tree)
在图示中,键标注在节点中,值标注在节点之下.每一个完整的英文单词对应一个特定的整数.Trie 可以看作是一个确定有限状态自动机,尽管边上的符号一般是隐含在分支的顺序中的.键不需要被显式地保存在节点中. ...
随机推荐
- spring boot 项目 mvn clean install 报 "Unable to find main class" 的解决方法
按照步骤来总会解决的 检查pom.xml中是否加入了spring boot maven插件 <build> <plugins> <plugin> <group ...
- weblogic漏洞(一)----CVE-2017-10271
WebLogic XMLDecoder反序列化漏洞(CVE-2017-10271) 0x01 漏洞原因: Weblogic的WLS Security组件对外提供webservice服务,其中使用了XM ...
- JS+Selenium+excel追加写入,使用python成功爬取京东任何商品~
之前一直是requests库做爬虫,这次尝试下使用selenium做爬虫,效率不高,但是却没有限制,文章是分别结合大牛的selenium爬虫以及excel追加写入操作而成,还有待优化,打算爬取更多信息 ...
- 二维vector的使用
和数组一样,数组有二维的数组,vector也有二维的vector.下面就介绍一下二维vector的使用方法. 一般声明初始化二维vector有三种方法 (1) vector< vector< ...
- php 超全局变量(整理)
来源:https://www.cnblogs.com/wsybky/p/8745286.html 一.$GLOBALS 在GLOBALS数组中,每一个变量为一个元素,键名对于变量名,值对于变量的内. ...
- Libra教程之:Transaction的生命周期
文章目录 Transaction的生命周期 提交一个Transaction 交易入链的详细过程 接收Transaction 和其他Validators共享这个Transaction 区块Proposi ...
- Spring5参考指南:组件扫描
文章目录 组件扫描 @Component 元注解和组合注解 组件内部定义Bean元数据 为自动检测组件命名 为自动检测的组件提供作用域 生成候选组件的索引 组件扫描 上一篇文章我们讲到了annotat ...
- Session服务器之Redis
Session服务器之Redis Redis与Memcached的区别内存利用率:使用简单的key value (键值对)存储的话,Mermcached 的内存利用率更高,而如果Redis采用hash ...
- Maven+Jmeter+Jenkins的持续集成的新尝试
前言: 这又是一篇迟到很久的文章,四月身体欠佳,根本不在状态. 好了,回到正题,相信大家也在很多博客,看过很多类似乎的文章,那么大家来看看我是如何实现的? 准备工作: 创建一个maven工程 创建一个 ...
- vue2.x学习笔记(二十五)
接着前面的内容:https://www.cnblogs.com/yanggb/p/12677019.html. 过滤器 vue允许开发者自定义过滤器,可被用于一些常见的文本格式化.过滤器可以用在两个地 ...