spark on yarn container分配极端倾斜
环境:CDH5.13.3 spark2.3
在提交任务之后,发现executor运行少量几台nodemanager,而其他nodemanager没有executor分配。
测试环境通过spark-shell模拟如下:
第一次尝试分配6个exeutor,具体如下
spark2-shell \
--driver-memory 1G \
--executor-memory 2G \
--num-executors 6 \
--executor-cores 3
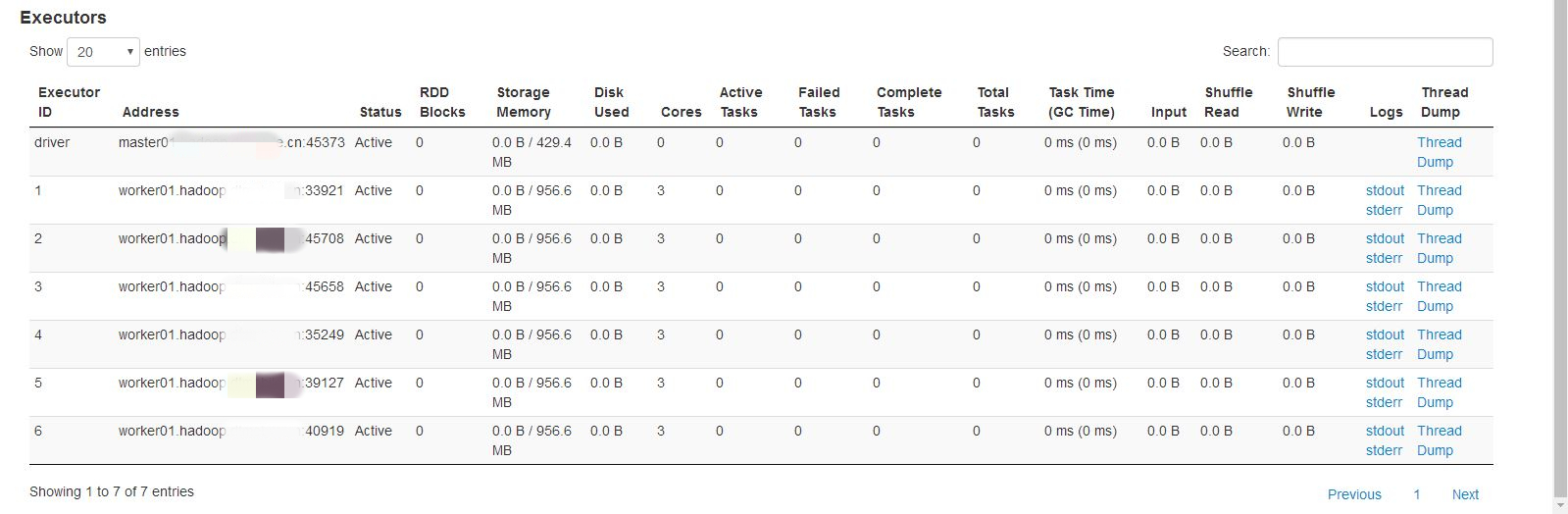
结果:container全部分布在同一个节点上,其他节点没有。
第二次尝试分配20个executor,具体如下
spark2-shell \
--driver-memory 1G \
--executor-memory 2G \
--num-executors 20 \
--executor-cores 3
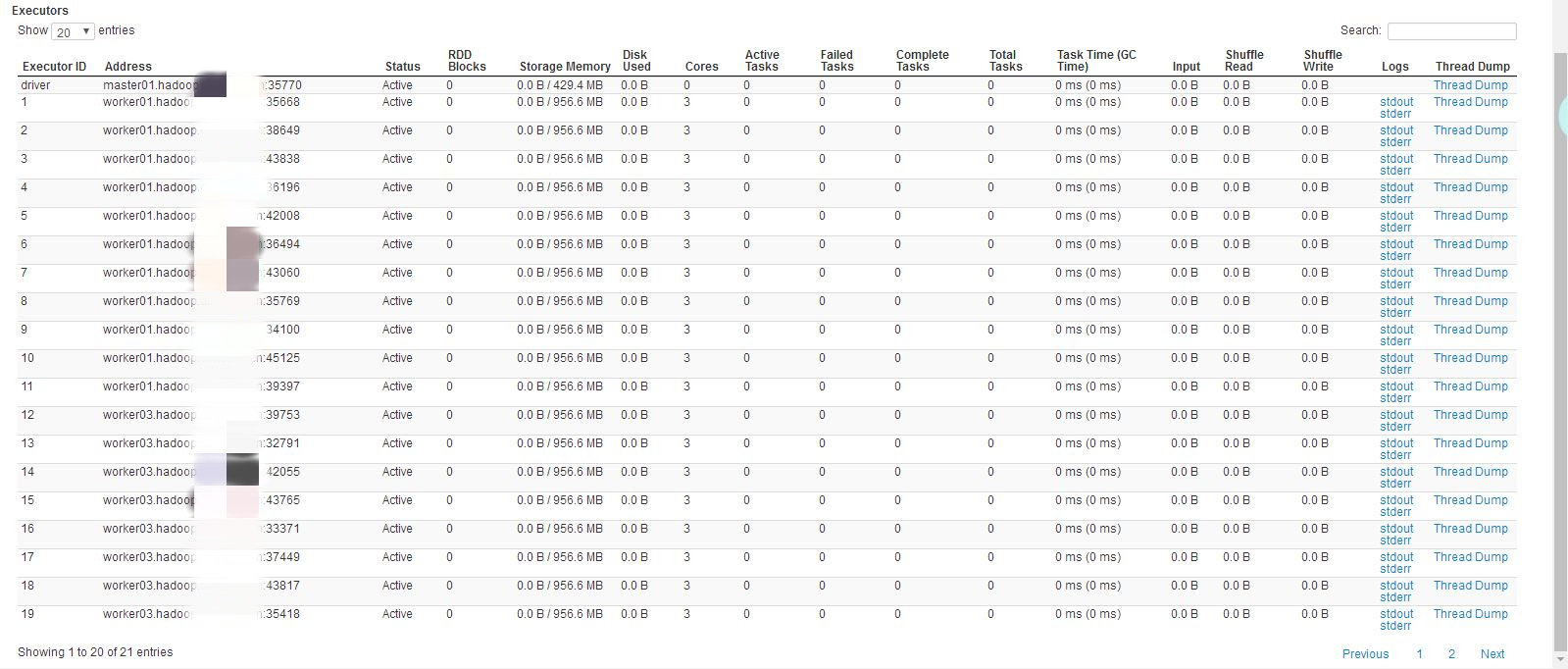
结果:container分布在其中两个节点上,其中一个节点上有11个,另外一个有9个。
spark on yarn实际的资源调度是由yarn来实现的,与standalone不同,目前环境yarn调度策略为公平调度,即FairScheduler,而这种情况是由公平调度中的一个参数有关:
<property>
<name>yarn.scheduler.fair.assignmultiple</name>
<value>true</value>
<discription>whether to allow multiple container assignments in one heratbeat defaults to false</discription>
</property>
在一次心跳请求中,是否分配多个container,CDH5.13.3默认设置为true。原生hadoop默认是false
<property>
<name>yarn.scheduler.fair.max.assign</name>
<value>-1</value>
</property>
如果上面设置的允许一次分配多个container,那么最多分配多少个,默认无限制。根据实际资源情况
将yarn.scheduler.fair.assignmultiple设置为false,再测试如下:
spark2-shell \
--driver-memory 1G \
--executor-memory 2G \
--num-executors 6 \
--executor-cores 3
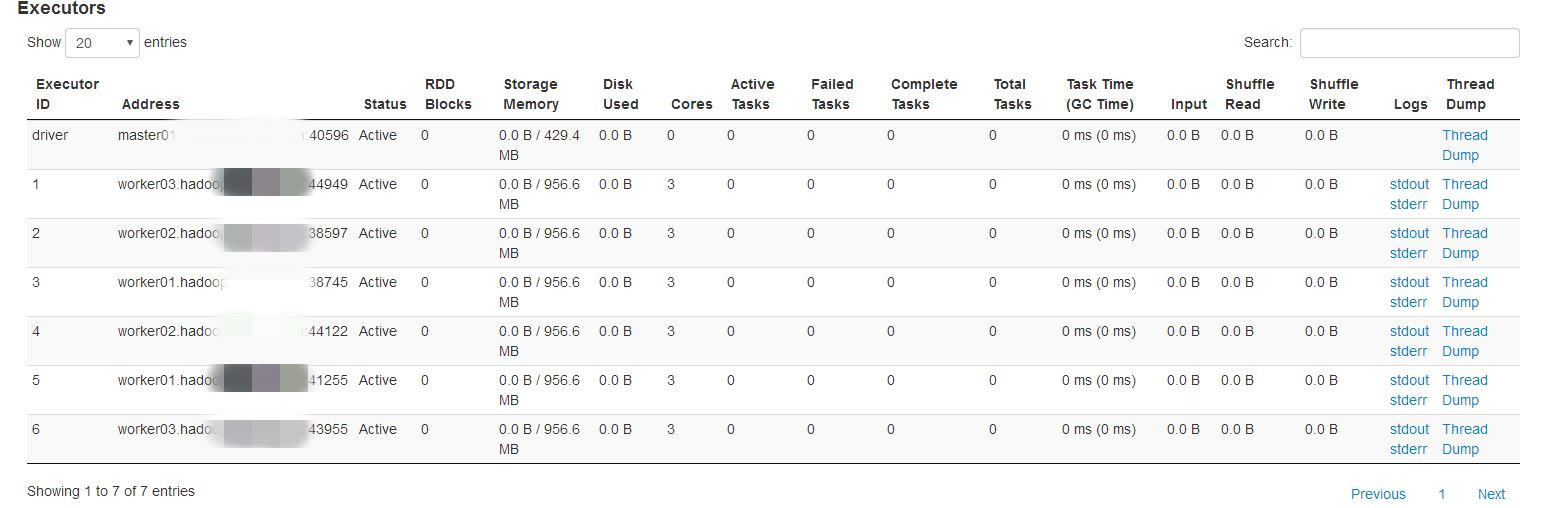
如果在生产环境下,spark任务的executor数量和内存都相对要高很多,所以这种情况会相对有所缓解,具体根据实际情况确定是否需要调整。
Yarn 的三种资源分配方式
FIFO Scheduler
如果没有配置策略的话,所有的任务都提交到一个 default 队列,根据它们的提交顺序执行。富裕资源就执行任务,若资源不富裕就等待前面的任务执行完毕后释放资源,这就是 FIFO Scheduler 先入先出的分配方式。
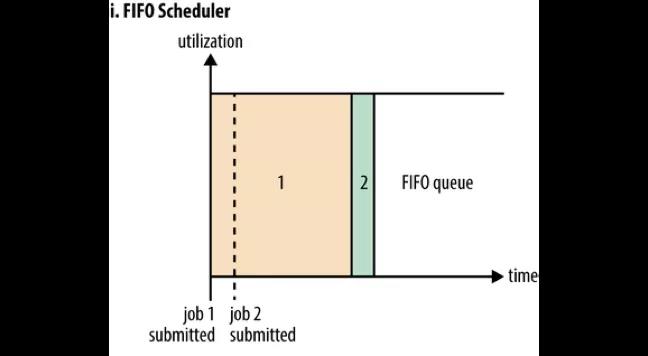
如图所示,在 Job1 提交时占用了所有的资源,不久后 Job2提交了,但是此时系统中已经没有资源可以分配给它了。加入 Job1 是一个大任务,那么 Job2 就只能等待一段很长的时间才能获得执行的资源。所以先入先出的分配方式存在一个问题就是大任务会占用很多资源,造成后面的小任务等待时间太长而饿死,因此一般不使用这个默认配置。
Capacity Scheduler
Capacity Scheduler 是一种多租户、弹性的分配方式。每个租户一个队列,每个队列可以配置能使用的资源上限与下限(譬如 50%,达到这个上限后即使其他的资源空置着,也不可使用),通过配置可以令队列至少有资源下限配置的资源可使用
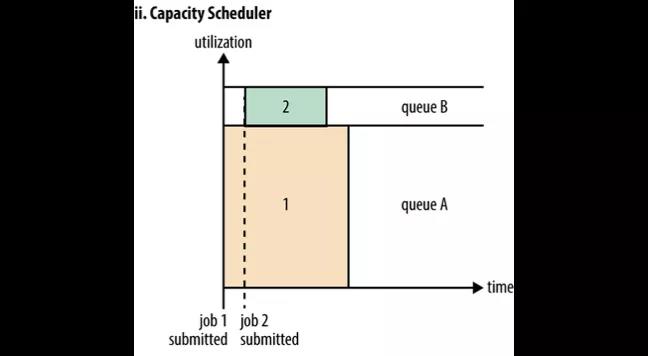
图中队列 A 和队列 B 分配了相互独立的资源。Job1 提交给队列 A 执行,它只能使用队列 A 的资源。接着 Job2 提交给了队列B 就不必等待 Job1 释放资源了。这样就可以将大任务和小任务分配在两个队列中,这两个队列的资源相互独立,就不会造成小任务饿死的情况了。
Fair Scheduler
Fair Scheduler 是一种公平的分配方式,所谓的公平就是集群会尽可能地按配置的比例分配资源给队列。
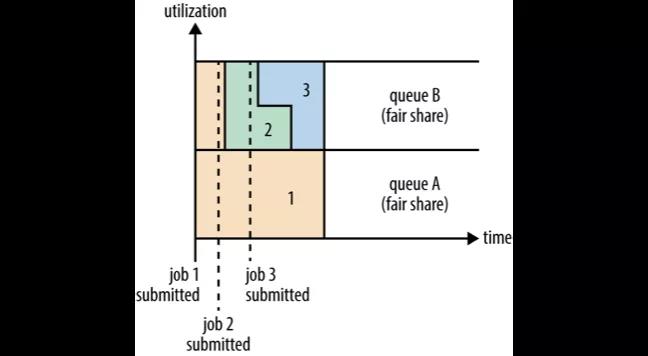
图中 Job1 提交给队列 A,它占用了集群的所有资源。接着 Job2 提交给了队列 B,这时 Job1 就需要释放它的一半的资源给队列 A 中的 Job2 使用。接着 Job3 也提交给了队列 B,这个时候 Job2 如果还未执行完毕的话也必须释放一半的资源给 Job3。这就是公平的分配方式,在队列范围内所有任务享用到的资源都是均分的。
spark on yarn container分配极端倾斜的更多相关文章
- Spark On YARN内存分配
本文转自:http://blog.javachen.com/2015/06/09/memory-in-spark-on-yarn.html?utm_source=tuicool 此文解决了Spark ...
- spark on yarn 内存分配
Spark On YARN内存分配 本文主要了解Spark On YARN部署模式下的内存分配情况,因为没有深入研究Spark的源代码,所以只能根据日志去看相关的源代码,从而了解“为什么会这样,为什么 ...
- Spark记录-Spark On YARN内存分配(转载)
Spark On YARN内存分配(转载) 说明 按照Spark应用程序中的driver分布方式不同,Spark on YARN有两种模式: yarn-client模式.yarn-cluster模式. ...
- spark on yarn模式下内存资源管理(笔记2)
1.spark 2.2内存占用计算公式 https://blog.csdn.net/lingbo229/article/details/80914283 2.spark on yarn内存分配** 本 ...
- Spark on Yarn:任务提交参数配置
当在YARN上运行Spark作业,每个Spark executor作为一个YARN容器运行.Spark可以使得多个Tasks在同一个容器里面运行. 以下参数配置为例子: spark-submit -- ...
- 【原创】大数据基础之Spark(2)Spark on Yarn:container memory allocation容器内存分配
spark 2.1.1 最近spark任务(spark on yarn)有一个报错 Diagnostics: Container [pid=5901,containerID=container_154 ...
- spark on yarn模式下内存资源管理(笔记1)
问题:1. spark中yarn集群资源管理器,container资源容器与集群各节点node,spark应用(application),spark作业(job),阶段(stage),任务(task) ...
- spark调优篇-Spark ON Yarn 内存管理(汇总)
本文旨在解析 spark on Yarn 的内存管理,使得 spark 调优思路更加清晰 内存相关参数 spark 是基于内存的计算,spark 调优大部分是针对内存的,了解 spark 内存参数有也 ...
- Spark on YARN两种运行模式介绍
本文出自:Spark on YARN两种运行模式介绍http://www.aboutyun.com/thread-12294-1-1.html(出处: about云开发) 问题导读 1.Spark ...
随机推荐
- 转发-[原创]ASR1K 在Rommon导入IOS-XE启动
在相对较老的设备平台可以通过在rommon下使用以下命令导入IOS. rommon 1 > IP_ADDRESS=192.168.1.2rommon 2 > IP_SUBNET_MASK= ...
- linux磁盘空间挂载
(1)查看磁盘空间 df -hl (3)查看硬盘及分区信息 fdisk -l (4)格式化新分区 mkfs.ext3 /dev/xvdb (5)将磁盘挂载在/www/wwwroot/default目录 ...
- 关于定时执行任务:Crontab的20个例子
关于定时执行任务:Crontab的20个例子 LeeLom 关注 2016.09.28 19:53* 字数 713 阅读 9186评论 6喜欢 15 简介 Linux crontab和Windows ...
- day2-1流程控制语句及对象
流程控制语句: Switch (a){ Case x: ....; } 当a===x(全等)时执行该语句 对象: 使用构造函数创建,new Object() var person = new Obje ...
- java模式之单例
懒汉式:需要实例的时候new public class Singleton_Lazy { private static Singleton_Lazy mSingleton; private Singl ...
- 杭电2024 C语言合法标识符
链接:http://acm.split.hdu.edu.cn/showproblem.php?pid=2024 开始真的对这题是一点头绪都没有,简直了.然后事实证明是我想多了,这题主要是把概念给弄清楚 ...
- JDBC 操作插入表出现javax.sql.rowset.serial.SerialBlob cannot be cast to oracle.sql.BLOB
/** * 接口方法 */ public void excuteInputDB(SynchServiceConfig synchServiceConfig) throws Exception { tr ...
- 重構電影網源碼 1905.com - 數據庫結構表
最近閒來無事,想著克隆一個電影網站. WWW.ROAK.COM 技術語言:JAVA EE * j2ee核心组件:jsp.servlet.jdbc.ejb.jndi * 数据通信:xml标记语言 * ...
- Springboot + redis + 注解 + 拦截器来实现接口幂等性校验
Springboot + redis + 注解 + 拦截器来实现接口幂等性校验 1. SpringBoot 整合篇 2. 手写一套迷你版HTTP服务器 3. 记住:永远不要在MySQL中使用UTF ...
- 安装本地jar到maven仓库
mvn install:install-file -DgroupId=com.alibaba -DartifactId=dubbo -Dversion=2.8.4 -Dpackaging=jar -D ...