spring+mybatis+mysql5.7实现读写分离,主从复制
申明:请尽量与我本博文所有的软件版本保持一致,避免不必要的错误。
所用软件版本列表:
MySQL 5.7
spring5
mybaties3.4.6
首先搭建一个完整的spring5+springMVC5+Mybatis3.4的完整框架,如果嫌麻烦,可以直接去我github上下载完整测试代码,代码地址 https://github.com/hlmk/project/tree/master/studyProject/read_and_write_separate
Mysql中,当数据和并发量到达一定的级别时,单库的处理能力显得力不从心,TPS/OPS 越来越低,因此到了这个阶段,DBA会将数据库设置为读写分离状态(生产环境一般会采用一主一从或者一主多从),由Master负责写操作,而Slave作为备库,不会开放写操作,但可以允许读操作,主从之间保持数据同步即可。根据二八法则,80%的数据库操作是读操作,剩下的20%是写操作,读写分离后,可以大大提升单库无法支撑的负载压力,如图5-1所示。在此需要注意,如果Master存在TPS较高的情况,Master与Slave数据库之间数据同步是会存在一定延迟的,因此在写入Master之前最好将同一份数据落到缓存中,以避免高并发的情况下,从Slave中获取不到指定数据的情况。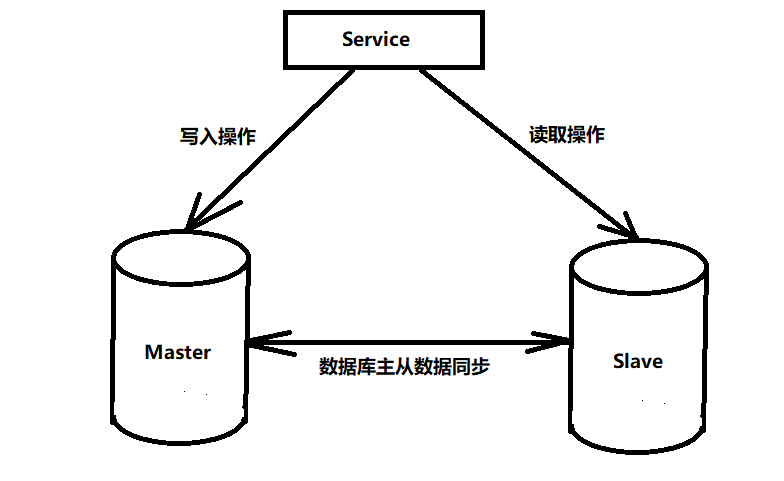
mybatis配置读写分离
配置文件主要是修改Mybatis相关的配置文件即可,原理就是通过springAOP切面和Mybatis插件结合,为service层调用的dao层根据方法名来选择是读数据库还是写数据库,具体配置如下:
Mybatis.xml配置
写数据源配置
<bean id="writeDataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<description>写数据库连接</description>
<property name="driverClassName" value="${db.driver}" />
<property name="url" value="${db.writer.url}" />
<property name="username" value="${db.writer.username}" />
<property name="password" value="${db.writer.password}" />
<!-- 配置初始化大小、最小、最大 -->
<property name="initialSize" value="${db.writer.initialSize}" />
<property name="minIdle" value="${db.writer.maxIdle}" />
<property name="maxActive" value="${db.writer.maxActive}" />
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="${db.writer.maxWait}" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="${db.timeBetweenEvictionRunsMillis}" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="${db.minEvictableIdleTimeMillis}" />
<property name="validationQuery" value="SELECT 'x'" />
<property name="testWhileIdle" value="true" />
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<!-- 打开PSCache,并且指定每个连接上PSCache的大小 -->
<property name="poolPreparedStatements" value="false" />
<property name="maxPoolPreparedStatementPerConnectionSize" value="20" />
<!-- 打开Druid的监控统计功能 -->
<property name="filters" value="slf4j" />
<property name="proxyFilters">
<list>
<ref bean="stat-filter" />
</list>
</property>
<property name="timeBetweenLogStatsMillis" value="300000" />
</bean>
读数据源配置
<bean id="readDataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<description>只读数据库连接</description>
<property name="driverClassName" value="${db.driver}" />
<property name="url" value="${db.reader.url}" />
<property name="username" value="${db.reader.username}" />
<property name="password" value="${db.reader.password}" />
<!-- 配置初始化大小、最小、最大 -->
<property name="initialSize" value="${db.reader.initialSize}" />
<property name="minIdle" value="${db.reader.maxIdle}" />
<property name="maxActive" value="${db.reader.maxActive}" />
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="${db.reader.maxWait}" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="${db.timeBetweenEvictionRunsMillis}" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="${db.minEvictableIdleTimeMillis}" />
<property name="validationQuery" value="SELECT 'x'" />
<property name="testWhileIdle" value="true" />
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<!-- 打开PSCache,并且指定每个连接上PSCache的大小 -->
<property name="poolPreparedStatements" value="false" />
<property name="maxPoolPreparedStatementPerConnectionSize" value="20" />
<!-- 打开Druid的监控统计功能 -->
<property name="filters" value=大专栏 spring+mybatis+mysql5.7实现读写分离,主从复制>"slf4j" />
<property name="proxyFilters">
<list>
<ref bean="stat-filter" />
</list>
</property>
<property name="timeBetweenLogStatsMillis" value="300000" />
</bean>
数据源配置
<!--注意这里的配置-->
<bean id="dataSource" class="com.cht.integration.aspect.ChooseDataSource" lazy-init="true">
<description>数据源</description>
<property name="targetDataSources">
<map key-type="java.lang.String" value-type="javax.sql.DataSource">
<!-- write -->
<entry key="write" value-ref="writeDataSource" />
<!-- read -->
<entry key="read" value-ref="readDataSource" />
</map>
</property>
<property name="defaultTargetDataSource" ref="writeDataSource" />
<property name="methodType">
<map key-type="java.lang.String">
<!-- read -->
<entry key="read" value=",get,select,count,list,query," />
<!-- write -->
<entry key="write" value=",add,insert,create,update,delete,remove," />
</map>
</property>
</bean>
数据源切面配置
<!-- 注意这个切面 -->
<bean id="DataSourceAspect" class="com.cht.integration.aspect.DataSourceAspect" />
获取数据源代码
/**
* 获取数据源
*
* @author
* @version
*/
public class ChooseDataSource extends AbstractRoutingDataSource {
public static Map<String, List<String>> METHODTYPE = new HashMap<String, List<String>>();
// 获取数据源名称
protected Object determineCurrentLookupKey() {
return HandleDataSource.getDataSource();
}
// 设置方法名前缀对应的数据源
public void setMethodType(Map<String, String> map) {
for (String key : map.keySet()) {
List<String> v = new ArrayList<String>();
String[] types = map.get(key).split(",");
for (String type : types) {
if (StringUtils.isNotBlank(type)) {
v.add(type);
}
}
METHODTYPE.put(key, v);
}
}
}
AOP切换数据源配置
/**
* 切换数据源(不同方法调用不同数据源)
*
* @author
* @version
*/
@Aspect
@EnableAspectJAutoProxy(proxyTargetClass = true)
public class DataSourceAspect {
private final Logger logger = LoggerFactory.getLogger(DataSourceAspect.class);
//配置切入点
// @Pointcut("execution(* com.zhx.service..*.*(..))")
public void aspect() {
}
/**
* 配置前置通知,使用在方法aspect()上注册的切入点
*/
// @Before("com.cht.integration.aspect()")
public void before(JoinPoint point) {
String className = point.getTarget().getClass().getName();
String method = point.getSignature().getName();
logger.info(className + "." + method + "(" + StringUtils.join(point.getArgs(), ",") + ")");
try {
L: for (String key : ChooseDataSource.METHODTYPE.keySet()) {
for (String type : ChooseDataSource.METHODTYPE.get(key)) {
if (method.startsWith(type)) {
logger.info(key);
HandleDataSource.putDataSource(key);
break L;
}
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
HandleDataSource.putDataSource("write");
}
}
// @After("com.cht.integration.aspect()")
public void after(JoinPoint point) {
HandleDataSource.clear();
}
}
数据库配置
主数据库配置
注意:务必保持主从数据库是同一个版本的数据库,否则容易出现兼容问题。
从数据库,一般用于存储,具体配置步骤如下:
1.找到my.ini目录所在位置,默认如下:
2.修改对应的配置。
//server-id 必须保证唯一,不能重复。
server-id=1
//指定二进制日志文件的存储路径和名称
log-bin=mysql-bin
重启mysql主服务
查看主服务器master信息 show master status
从服务器配置
1.找到my.ini目录所在位置,默认如下:
2.修改从服务器配置,如下:
server-id=2
log-bin=mysql-bin
relay_log=mysql-relay-bin
log_slave_updates=1
read_only=1
3.重启从服务器服务
4.如果之前设置过从服务器配置,需要先 reset slave; ,否则跳过这一步
5.指定从服务器的主服务器
change master to master_host='192.168.159.128', --指定主服务器的IP地址
master_port=3306, --指定主服务器的端口
master_use='root', --指定主服务器的操作用户
master_password='root', --指定主服务器的密码
master_log_file='mysql-bin.000003', --指定要同步主服务器的日志文件
master_log_pos='154'; --指定要同步的节点,和show master status 中的 position值保持一致
6.启动从服务器配置 start slave;
7.show slave statusG; 查看从服务状态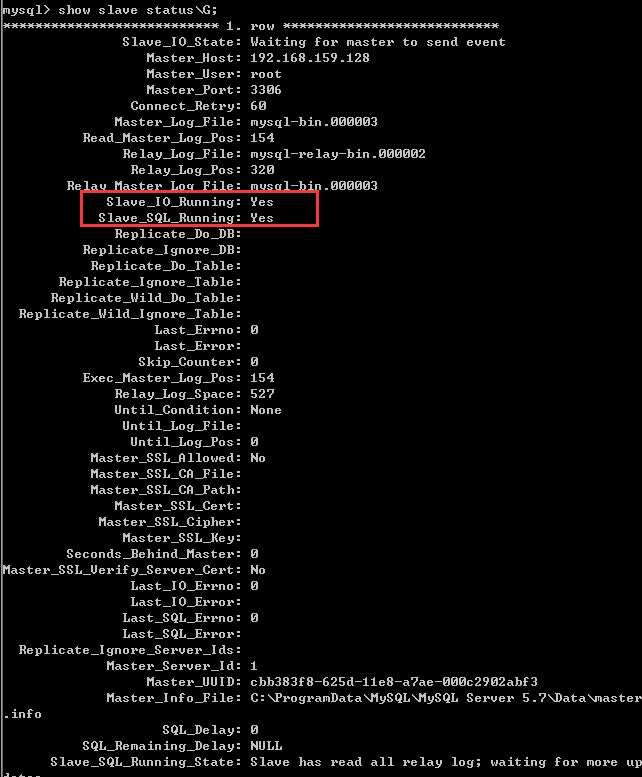
图上标志的两个都为yes时,则标示配置成功
测试是否同步
修改主服务器的数据,会发现数据同步到从服务器中,我这里是测试成功的,具体的就不截图了,如果没同步成功,那么请检查是否主从服务器版本是否为同一个版本,然后在检查配置是否写错,主从同步延时那个就参考其他资料了,这就先介绍到这里。
参考博客:https://blog.csdn.net/juded/article/details/54600294
spring+mybatis+mysql5.7实现读写分离,主从复制的更多相关文章
- Spring+mybatis 实现aop数据库读写分离,多数据库源配置
在数据库层面大都采用读写分离技术,就是一个Master数据库,多个Slave数据库.Master库负责数据更新和实时数据查询,Slave库当然负责非实时数据查询.因为在实际的应用中,数据库都是读多写少 ...
- Spring + Mybatis项目实现数据库读写分离
主要思路:通过实现AbstractRoutingDataSource类来动态管理数据源,利用面向切面思维,每一次进入service方法前,选择数据源. 1.首先pom.xml中添加aspect依赖 & ...
- 170301、使用Spring AOP实现MySQL数据库读写分离案例分析
使用Spring AOP实现MySQL数据库读写分离案例分析 原创 2016-12-29 徐刘根 Java后端技术 一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案 ...
- MyBatis多数据源配置(读写分离)
原文:http://blog.csdn.net/isea533/article/details/46815385 MyBatis多数据源配置(读写分离) 首先说明,本文的配置使用的最直接的方式,实际用 ...
- mybatis用spring的动态数据源实现读写分离
一.环境: 三个mysql数据库.一个master,两个slaver.master写数据,slaver读数据. 二.原理: 借助Spring的 AbstractRoutingDataSource 这个 ...
- 161220、使用Spring AOP实现MySQL数据库读写分离案例分析
一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案,更是最大限度了提高了应用中读取 (Read)数据的速度和并发量. 在进行数据库读写分离的时候,我们首先要进行数据库 ...
- 使用Spring AOP实现MySQL数据库读写分离案例分析
一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案,更是最大限度了提高了应用中读取 (Read)数据的速度和并发量. 在进行数据库读写分离的时候,我们首先要进行数据库 ...
- 使用Spring AOP实现MySql的读写分离
转自:http://blog.csdn.net/xlgen157387/article/details/53930382 一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解 ...
- SpringMVC4+MyBatis+SQL Server2014实现读写分离
前言 基于mybatis的AbstractRoutingDataSource和Interceptor用拦截器的方式实现读写分离,根据MappedStatement的boundsql,查询sql的sel ...
随机推荐
- Spring核心实现篇
一.Spring Framework的核心:IoC容器的实现 1.1Spring IoC的容器概述 1.1.1 IoC容器和控制反转模式 依赖控制反转的实现有很多种方式.在Spring中,IOC容器是 ...
- TensorFlow 实例一(一元线性回归)
使用TensorFlow进行算法设计与训练的核心步骤: 准备数据 构建模型 训练模型 进行预测 问题描述: 通过人工数据集,随机生成一个近似采样随机分布,使得w = 2.0 ,b= 1,并加入一个噪声 ...
- 判断1/N是否为无限小数
给定一个正整数N,请判断1/N是否为无限小数,若是输出YES,若不是请输出NO. 思路: 只要被除数n可以转换成2的次幂或者2与5的组合即为有限小数,否则为无线小数 代码如下: #include &l ...
- Pickle的简单使用
单词Pickle的中文意思是“泡菜.腌菜.菜酱”的意思,Pickle是Python的一个包,主要功能是对数据进行序列化和反序列化.那么什么叫序列化和反序列化呢? 其序列化过程就是把数据转化成二进制数据 ...
- Sqlite教程(4) Activity
之前我们已经有了DbHelper.Data Access Object.Configuration. 那麽现在就是由Activity去创建它们,然後就可以存取Sqlite. 架构图表示了它们的关系. ...
- 24)PHP,数据库的基本知识
(1)数据库操作的基本流程: • 建立连接(认证身份) • 客户端向服务器端发送sql命令 • 服务器端执行命令,并返回执行的结果 • 客户端接收结果(并显示) • 断开连接 (2)php中操作数据库 ...
- day26-socket(server和client通信)
# socket是应用层与TCP/IP协议通信的中间软件抽象层,它是一组接口.它把复杂的TCP/IP协议隐藏到socket #接口的后面,让socket去组织数据,以符合指定的协议. # socket ...
- 记一次关于JDBCUtils工具类的编写
jdbc.properties数据库配置的属性文件内容如下 jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://localhost/xxxx ...
- 常见的Java不规范代码
1.格式化源代码 Ctrl + Shift + F – 格式化源代码. Ctrl + Shift + O – 管理import语句并移除未使用的语句 除了手动执行这两个功能外,你还可以让Eclipse ...
- QLIKVIEW基础设置及初步了解
改变语言环境 开发工具条勾选出来 创建selection box 创建search box 编辑脚本 重加载数据 基本联动思路:table view tableview load FSUPPLIERI ...