Scrapy框架简介及小项目应用
今天来总结一下Scrapy框架的用法。scrapy的架构如下:

Engine :引擎,处理整个系统的数据流处理、触发事务,是整个框架的核心。
Items :项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成该 Items 对象。
Scheduler :调度器,接受 Engine 发过来的请求,并将其加入队列中,在 Engine 再次请求的时候将请求提供给 Engine。
Downloader :下载器,下载网页内容,并将网页容返回给 Spiders。
Spiders : 蜘蛛,其内定义了爬取的逻辑和网页 解析规则 ,它主要负责解析响应并生成提取结果和新的请求。
ItemPipeline :项目管道,负责处理由 Spiders 从网页中提取的项目,它的主要任务是清洗、验证和存储数据。
Downloader Middlewares :下载器中间件,主要处理 Engine与 Downloader 之间的请求及响应。
Spide Middlewares : Spiders 中间件,主要处理 Spiders 输入的响应和输出的结果,及新的请求。
接下来介绍 个简单的项目,完成一遍 Scrapy抓取流程
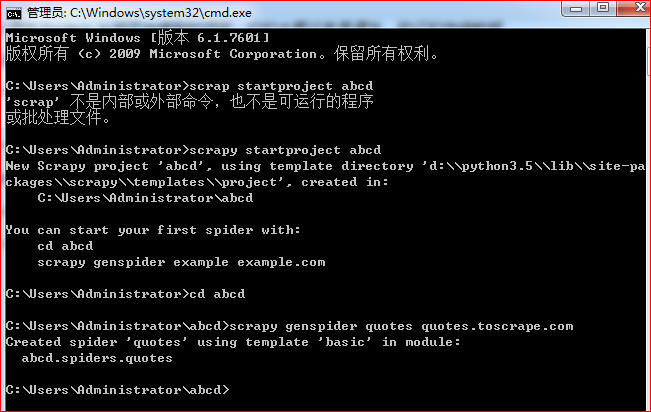
1、打开 cmd 终端窗口, 输入 scrapy startproject abcd,生成一个 abcd 的项目
2、按照提示,输入 cd abcd 进入 abcd 项目所在的文件夹, 输入 scrapy genspider quotes quotes.toscrape.com,
quotes是 spiders 的 .py 文件,quotes.toscrape.com 是爬取的网站域名。
打开项目文件 quotes,里面包含内容如下:

allowed domains :它是允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉
start_urls :它包含了 Spider 在启动时爬取的 url 列表,初始请求是由它来定义的
3、观察目标网站,我们可以获取到到内容有 text 、author、 tags,因此开始定义 Items.py
class AbcdItem(scrapy.Item):
# define the fields for your item here like:
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
4、进入quotes.py文件,在 parse函数下输入 print(response.text), 在终端输入 scrapy crawl quotes,看看能否正常请求到内容
结果报错:UnicodeEncodeError: 'gbk' codec can't encode character '' in position 11162: illegal multibyte sequence
是说编码错误,经过查资料,进行修改就改好了,https://blog.csdn.net/u013155359/article/details/81566807
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gbk')
说是因为编码问题,但我还不太理解原因,暂且这么用
5、接下来进行quotes.py代码编写
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = AbcdItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract()
yield item
终端运行,得到正确的输出
6、抓取下一页的内容
def parse(self, response):
quotes = response.css('.quote') # response 直接就是返回的内容
for quote in quotes:
item = QuoteItem()
text = quote.css('.text::text').extract_first()
author = quote.css('.author::text').extract_first()
tags = quote.css('.tags .tag::text').extract()
item['text'] = text
item['author'] = author
item['tags'] = tags
yield item
next = response.css('.pager .next a::attr(href)').extract_first()
url = response.urljoin(next) # 获取一个绝对的URL
yield scrapy.Request(url=url, callback=self.parse)
url = response.urljoin(next),获取一个绝对的 URL,next='page/2/',url='http://quotes.toscrape.com/page/2/yield scrapy.Request(url=url, callback=self.parse),重新调用 parse()函数,一直循环下去,运行结果正常输出所有内容。
7、将输出的内容保存下来,有一下四种方法,个人感觉保存为 json 或 jl 格式的文件看起来最清晰。
scrapy crawl quotes -o quotes.json
scrapy crawl quotes -o quotes.jl
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.csv
8、保存到MongoDb数据库,这个稍微复杂一点,需要用到 Pipeline.py 文件。
先在 Pipeline.py 中写入以下代码:
import pymongo
from scrapy.exceptions import DropItem class TextPipeline(object):
def __init__(self):
self.limit = 50
def process_item(self, item, spider):
if item['text']:
if len(item['text']) > self.limit: # 对长度大于50的text进行修改
item['text'] = item['text'][0:self.limit].rstrip()+'...'
return item
else:
return DropItem('Missing Text') class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db @classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
) def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db] def process_item(self, item, spider):
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item def close_spider(self, spider):
self.client.close()
定义了 TextPipeline() 和 MongoPipeline() 两个类。
TextPipeline() 和 MongoPipeline() 两个类都有 process_item 的方法,process item ()方法必须返回包含数据的字典或 Item 象,或者抛出 Dropltem 异常,
启用 Item Pipeline 后, Item Pipeline 会自动调用这个方法。
MondoPipeline() 类: from crawler(),通过 crawler 我们可以拿到全局配置的每个配置信息,这个方法的定义主要是用来获取 settings.py 中的配置。
open spider(), Spider 开启时,这个方法被调用
close_spider(), Spider 关闭时,这个方法会调用
process item () 方法则执行了数据插入操作
我们在 settings.py 中加入如下内容:
MONGO_URI='localhost'
MONGO_DB = 'abcd' ITEM_PIPELINES = {
'abcd.pipelines.TextPipeline': 300,
'abcd.pipelines.MongoPipeline': 400
}
在终端运行 scrapy crawl quotes,数据成功在 MongoDb 中保存下来。

Scrapy框架简介及小项目应用的更多相关文章
- 爬虫基础(五)-----scrapy框架简介
---------------------------------------------------摆脱穷人思维 <五> :拓展自己的视野,适当做一些眼前''无用''的事情,防止进入只关 ...
- 爬虫开发7.scrapy框架简介和基础应用
scrapy框架简介和基础应用阅读量: 1432 scrapy 今日概要 scrapy框架介绍 环境安装 基础使用 今日详情 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数 ...
- Scrapy 框架简介
Scrapy 框架 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的 ...
- 爬虫(九)scrapy框架简介和基础应用
概要 scrapy框架介绍 环境安装 基础使用 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能 ...
- 10.scrapy框架简介和基础应用
今日概要 scrapy框架介绍 环境安装 基础使用 今日详情 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被 ...
- scrapy框架简介和基础应用
scrapy框架介绍 环境安装 基础使用 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性 ...
- 爬虫 (5)- Scrapy 框架简介与入门
Scrapy 框架 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页 ...
- (六--一)scrapy框架简介和基础应用
一 什么是scrapy框架 官方解释 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 ( ...
- scrapy的一个简单小项目
使用scrapy抓取目标url下所有的课程名和价格,并将数据保存为json格式url=http://www.tanzhouedu.com/mall/course/initAllCourse 观察网页并 ...
随机推荐
- 【Java8新特性】重复注解与类型注解,你真的学会了吗?
写在前面 在Java8之前,在某个类或者方法,字段或者参数上标注注解时,同一个注解只能标注一次.但是在Java8中,新增了重复注解和类型注解,也就是说,从Java8开始,支持在某个类或者方法,字段或者 ...
- Java实现 蓝桥杯VIP 算法提高 3-2字符串输入输出函数
算法提高 3-2字符串输入输出函数 时间限制:1.0s 内存限制:512.0MB 描述 编写函数GetReal和GetString,在main函数中分别调用这两个函数.在读入一个实数和一个字符串后,将 ...
- Java实现 LeetCode 118 杨辉三角
118. 杨辉三角 给定一个非负整数 numRows,生成杨辉三角的前 numRows 行. 在杨辉三角中,每个数是它左上方和右上方的数的和. 示例: 输入: 5 输出: [ [1], [1,1], ...
- Java实现第九届蓝桥杯字母阵列
字母阵列 题目描述 仔细寻找,会发现:在下面的8x8的方阵中,隐藏着字母序列:"LANQIAO". SLANQIAO ZOEXCCGB MOAYWKHI BCCIPLJQ SLAN ...
- 【Spring注解驱动开发】聊聊Spring注解驱动开发那些事儿!
写在前面 今天,面了一个工作5年的小伙伴,面试结果不理想啊!也不是我说,工作5年了,问多线程的知识:就只知道继承Thread类和实现Runnable接口!问Java集合,竟然说HashMap是线程安全 ...
- sql server 连接种类
一.连接种类 内连接 inner join 如果分步骤理解的话,内连接可以看做先对两个表进行了交叉连接后,再通过加上限制条件(SQL中通过关键字on)剔除不符合条件的行的子集,得到的结果就是内连接了. ...
- 因为 MongoDB 没入门,我丢了一份实习工作
有时候不得不感慨一下,系统升级真的是好处多多,不仅让我有机会重构了之前的烂代码,也满足了我积极好学的虚荣心.你看,Redis 入门了.Elasticsearch 入门了,这次又要入门 MongoDB, ...
- springMVC 异常
springMVC 异常 0.依赖(不只是本次案例所需) <?xml version="1.0" encoding="UTF-8"?> <p ...
- 一篇文章教会你用Python抓取抖音app热点数据
今天给大家分享一篇简单的安卓app数据分析及抓取方法.以抖音为例,我们想要抓取抖音的热点榜数据. 要知道,这个数据是没有网页版的,只能从手机端下手. 首先我们要安装charles抓包APP数据,它是一 ...
- 高效开发(James)
1.对自己的要求 定位自己Level,清晰自己的目标. 学一个点,明确自己通过学习,需要达到的程度 怎么学一门技术 比如: Spring Cloud 它为什么出现? 它解决了什么问题? 它是怎么解决的 ...