sparkRDD:第1节 RDD概述;第2节 创建RDD
RDD的特点:
(1)rdd是数据集;
(2)rdd是编程模型:因为rdd有很多数据计算方法如map,flatMap,reduceByKey等;
(3)rdd相互之间有依赖关系;
(4)rdd是可以分区的,如下图所示:
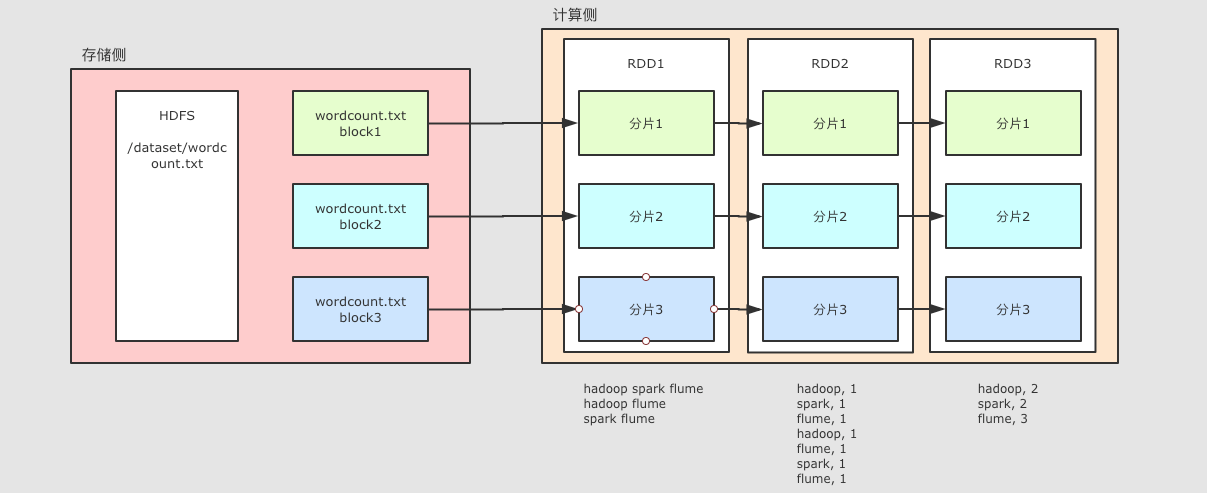
=======================================
Spark计算模型RDD
一、 课程目标
目标1:掌握RDD的原理
目标2:熟练使用RDD的算子完成计算任务
目标3:掌握RDD的宽窄依赖
目标4:掌握RDD的缓存机制
目标5:掌握划分stage
目标6:掌握spark的任务调度流程
二、 弹性分布式数据集RDD
2. RDD概述
2.1 什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将数据缓存在内存中,后续的查询能够重用这些数据,这极大地提升了查询速度。
Dataset:一个数据集合,用于存放数据的。
Distributed:RDD中的数据是分布式存储的,可用于分布式计算。
Resilient:RDD中的数据可以存储在内存中或者磁盘中。
2.2 RDD的属性


1) A list of partitions :一个分区(Partition)列表,数据集的基本组成单位。
对于RDD来说,每个分区都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分区个数,如果没有指定,那么就会采用默认值。(比如:读取HDFS上数据文件产生的RDD分区数跟block的个数相等)
2)A function for computing each split :一个计算每个分区的函数。
Spark中RDD的计算是以分区为单位的,每个RDD都会实现compute计算函数以达到这个目的。
3)A list of dependencies on other RDDs:一个RDD会依赖于其他多个RDD,RDD之间的依赖关系。
RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
4)Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned):一个Partitioner,即RDD的分区函数(可选项)。
当前Spark中实现了两种类型的分区函数,一个是基于哈希的HashPartitioner,另外一 个是基于范围的RangePartitioner。只有对于key-value的RDD,才会有Partitioner(必须要产生shuffle),非key-value的RDD的Parititioner的值是None。
5)Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file):一个列表,存储每个Partition的优先位置(可选项)。
对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置(spark进行任务分配的时候尽可能选择那些存有数据的worker节点来进行任务计算)。
2.3 为什么会产生RDD?
(1) 传统的MapReduce虽然具有自动容错、平衡负载和可拓展性的优点,但是其最大缺点是采用非循环式的数据流模型,使得在迭代计算中要进行大量的磁盘IO操作。RDD正是解决这一缺点的抽象方法。
(2) RDD是Spark提供的最重要的抽象的概念,它是一种具有容错机制的特殊集合,可以分布在集群的节点上,以函数式编程来操作集合,进行各种并行操作。可以把RDD的结果数据进行缓存,方便进行多次重用,避免重复计算。
2.4 RDD在Spark中的地位及作用
(1) 为什么会有Spark?
因为传统的并行计算模型无法有效的解决迭代计算(iterative)和交互式计算(interactive);而Spark的使命便是解决这两个问题,这也是他存在的价值和理由。
(2) Spark如何解决迭代计算?
其主要实现思想就是RDD,把所有计算的数据保存在分布式的内存中。迭代计算通常情况下都是对同一个数据集做反复的迭代计算,数据在内存中将大大提升IO操作。这也是Spark涉及的核心:内存计算。
(3) Spark如何实现交互式计算?
因为Spark是用scala语言实现的,Spark和scala能够紧密的集成,所以Spark可以完美的运用scala的解释器,使得其中的scala可以向操作本地集合对象一样轻松操作分布式数据集。
(4) Spark和RDD的关系?
RDD是一种具有容错性、基于内存计算的抽象方法,RDD是Spark Core的底层核心,Spark则是这个抽象方法的实现。
3. 创建RDD
1)由一个已经存在的Scala集合创建。
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
2)由外部存储系统的文件创建。包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等。
val rdd2 = sc.textFile("/words.txt")
3)已有的RDD经过算子转换生成新的RDD
val rdd3=rdd2.flatMap(_.split(" "))
sparkRDD:第1节 RDD概述;第2节 创建RDD的更多相关文章
- Spark RDD概念学习系列之如何创建RDD
不多说,直接上干货! 创建RDD 方式一:从集合创建RDD (1)makeRDD (2)Parallelize 注意:makeRDD可以指定每个分区perferredLocations参数,而para ...
- 【Spark】【RDD】从本地文件系统创建RDD
练习作业 完成任务从文件创建三个RDD(math bigdata student) cd ~ touch math touch bigdata touch student pwd 启动Spark-sh ...
- 创建RDD
RDD创建 在Spark中创建RDD的创建方式大概可以分为三种:从集合中创建RDD:从外部存储创建RDD:从其他RDD创建. 由一个已经存在的Scala集合创建,集合并行化,而从集合中创建RDD,Sp ...
- Spark练习之创建RDD(集合、本地文件),RDD持久化及RDD持久化策略
Spark练习之创建RDD(集合.本地文件) 一.创建RDD 二.并行化集合创建RDD 2.1 Java并行创建RDD--计算1-10的累加和 2.2 Scala并行创建RDD--计算1-10的累加和 ...
- 第一节 JavaScript概述
第一节 JavaScript概述 JavaScript:其实就是对HTML+CSS静态页面进行样式修改,使其实现各种动态效果. 编写JS脚本基本步骤: 1. HTML+CSS静态布局: 2. 确定要修 ...
- 弹性分布式数据集RDD概述
[Spark]弹性分布式数据集RDD概述 弹性分布数据集RDD RDD(Resilient Distributed Dataset)是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作 ...
- Spark-Core RDD概述
一.什么是RDD 1.RDD(Resilient Distributed DataSet)弹性分布式数据集 2.是Spark中最基本的数据抽象 3.在代码中是一个抽象类,它代表一个弹性的.不可变的.可 ...
- 无法读取配置节“protocolMapping”,因为它缺少节声明
无法读取配置节“protocolMapping”,因为它缺少节声明 1.正常情况 : Web.config文件中有protocolMapping节点, 发现在IIS部署时使用了.NET 2.0的 ...
- 创建RDD的方式
创建RDD的方法: JavaRDD<String> lines = sc.textFile("hdfs://spark1:9000/spark.txt"); Jav ...
随机推荐
- hadoop学习笔记(六):hadoop全分布式集群的环境搭建
本文原创,如需转载,请注明作者以及原文链接! 一.前期准备: 1.jdk安装 不要用centos7自带的openJDK2.hostname 配置 配置位置:/etc/s ...
- 解密国内BAT等大厂前端技术体系-美团点评之下篇(长文建议收藏)
引言 在上篇中,我已经介绍了美团点评的业务情况.大前端的技术体系,其中大前端的技术全景图如下: 上篇重点介绍了工程化和代码质量的部分,工程化涵盖了客户端持续集成平台-MCI.全端监控平台-CAT.移动 ...
- Python - 用python实现split函数
# pattern支持字符或者字符串 def my_split(string, pattern): ret = [] len_pattern = len(pattern) while True: in ...
- 微信-获取openid
第一步 首先把微信的支付流程与相关的文档熟悉一遍,具体的支付逻辑是怎么实现的,心里要有一定的路数,开发的时候一边看文档,一边写,再一边调试这是最好的选择,首先阅读微信开发文档,因为我们这次是做公众号支 ...
- AcWing - 156 矩阵(二维哈希)
题目链接:矩阵 题意:给定一个$m$行$n$列的$01$矩阵$($只包含数字$0$或$1$的矩阵$)$,再执行$q$次询问,每次询问给出一个$a$行$b$列的$01$矩阵,求该矩阵是否在原矩阵中出现过 ...
- 【PAT甲级】1097 Deduplication on a Linked List (25 分)
题意: 输入一个地址和一个正整数N(<=100000),接着输入N行每行包括一个五位数的地址和一个结点的值以及下一个结点的地址.输出除去具有相同绝对值的结点的链表以及被除去的链表(由被除去的结点 ...
- C# FormData 文件太大报错404 Form表单上传大文件,无法进入后台Action,页面提示404.
web.config中添加如下节点 <system.webServer> <security> <requestFiltering > &l ...
- c# 调用c++sdk时结构体与byte数组互转
/// <summary> /// 由结构体转换为byte数组 /// </summary> public static byte[] StructureToByte<T ...
- sso系统登录以及jsonp原理
登录的处理流程: 1.登录页面提交用户名密码. 2.登录成功后生成token.Token相当于原来的jsessionid,字符串,可以使用uuid. 3.把用户信息保存到redis.Key就是toke ...
- 使用URLConnection获取页面返回的xml数据
public static void main(String[] args) throws Exception { String path="http://flash.weather.com ...