r-cnn学习(一)
http://closure11.com/rcnn-fast-rcnn-faster-rcnn%E7%9A%84%E4%B8%80%E4%BA%9B%E4%BA%8B/
首先看fast r-cnn这篇论文,中间加入了有些博友的想法。
问题
目标检测主要面临两个问题:过多的候选位置(proposals);必须由这些粗略的候选位置中选出准确的位置。
这篇论文将学习目标proposals分类和精确定位结合起来。
1、 R-CNN和SPPnet存在的问题
(1)R-CNN的问题
训练需要多阶段:先用ConvNet进行微调,再用SVM进行分类,最后通过regression对 bounding box进行微调。在R-CNN中,
20类即20个SVM分类器训练,20个bounding box回归器训练(测试同),非常繁琐;
训练代价大:在SVM和regression过程中,一张图需要2k个proposals(有大量重叠),提取每个proposals的特征
(重叠)并写入磁盘,耗时耗空间;
R-CNN需要先对proposals进行形变操作(227*227),再输入CNN提取特征,而AlexNet CNN在特征提取过程中并不
固定图像的大小,只是在全连接时才需要固定尺寸,然后使用SVM分类。
(2)SPPnet
R-CNN慢是因为其需要对每个proposals进行前向计算而没有共享,SPPnets通过共享来加速r-cnn,SPPnet先计算
整张图像的卷积特征图,然后通过提取特征图中特征向量对proposals进行分类。使用max pooling将特征映射为固定大
小。不同于R-CNN,微调算法不能更新spatial pyramid pooling前面的卷积层,只能更新后面的全连接层,这限制了其精度。
2、论文工作
(1)通过使用多任务损失,使训练成为单阶段的。
(2)训练可在所有层中更新
(3)不需要在磁盘中存储特征
3、如何做到呢
(1)fast r-cnn架构和训练

输入为整张图像和一系列的object proposals(大小不同)。网络首先用几层卷积和max pooling处理
整张图像,生成特征图;对于每个object proposal,使用RoI pooling从特征图中提取固定大小的特
征向量;将特征向量送入全连接层(fc layer),进而分出两支:一支输出K类物体的softmax 概率+背景,
另一支输出K个类别的四个值(每个类别框的位置和大小)。那么什么是RoI pooling?
(2)RoI Pooling
RoI pooling层使用 max pooling将不同大小的特征转为固定大小的小特征(W*H)。那么它是如何做到的呢?
对于一个h*w的区域,将其划分为H * W大小的格子,每个格子中有h/H * w/W个格子,对这些格子做 max pooling
就行了。
(3)预训练前网络的初始化
当用fast r-cnn初始化预训练网络时,它需要经历三种变换:
首先用RoI pooling层替代最后一个max pooling层,在送入全连接层前将其变为H*W;
其次,将最后一个全连接层和softmax替换为两个分支层(参考前文);
这个模型需要两个输入,一个为一系列图像,另一个为这些图像的一系列RoI(region of intrest)。
(4) 检测时的微调
首先阐述为啥SPPnet不能在spatial pyramid pooling layer下更新权重:这是因为在训练网络时,每个训练样本(RoI)来自
于不同的图像,而bp算法通过SPP layer是远远不够的(?)。这种不够是因为,每个RoI可能拥有非常大的感受野,经常跨越
整副输入图像。因为前向传输时必须处理整个感受野,训练输入时会很大(通常为整副图像)。
本文在训练时通过特征共享来提高效率。在训练时,SGD分层次采样,首先采样N张图像,然后在每张图像上采样R/N个RoI。
来自于同一张图像的RoIs共享计算和内存,这就将计算量降低了N倍。比如当N=2,R=128时,这种方法大约比在128张图像上提
取一个RoI(R-CNN和SPPnet的方法)快64倍。
除了分层采样,本文还采用流水线训练过程:使用一个微调阶段,将softmax分类器和bounding-box regressors联合优化,而不是
将训练softmax,SVM和regressors分成三个阶段。那个这个过程中的各个组成(包括loss,mini-batch采样策略,通过RoI pooling层的bp算法和
SGD参数)是怎么样的呢?
Multi-task loss
该模型包括两个分支输出层,第一个输出每个RoI离散的概率值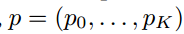 (由softmax得出),有K+1类;
(由softmax得出),有K+1类;
第二个分支输出bounding box的offsets, ,其中tk表示尺度不变的转换相对object proposal的log-space的高度/宽度转换。
,其中tk表示尺度不变的转换相对object proposal的log-space的高度/宽度转换。
每个RoI的标签为类别u,每个bounding box的regression target记为v,本文对每个RoI使用一个multi-task loss来联合训练分类器
和bounding box regression:

其中 ,第二个损失函数(回归操作只针对前景)被定义为对于类别u的bounding box 的regression元组(?)。
,第二个损失函数(回归操作只针对前景)被定义为对于类别u的bounding box 的regression元组(?)。
其中v= ,预测元组
,预测元组 。对于bounding box loss:
。对于bounding box loss:
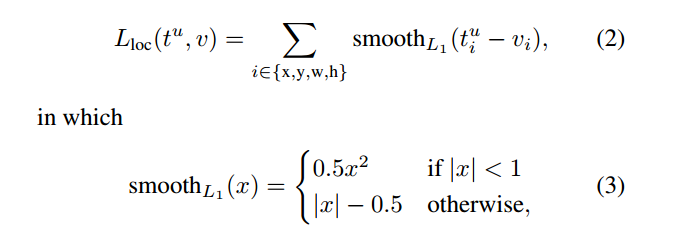
Mini-batch sampling
在微调阶段,每个SGD mini-batch从N=2张图像中构造,均匀随机选择(常见的做法是遍历数据集的排列)。我们使用的
mini-batch的大小为R=128,每张图中采样64个RoI。我们从object proposals中取25%RoIs(正样本比例为25%),
这些object proposals与bounding box至少有0.5的交集。这些RoI包含前景,剩余的RoI也从object proposals中采样(负样本75%),
它们的IoU在0.1至0.5之间,这样是背景。
Back-propagation through RoI pooling layers
经过RoI pooling层的BP算法如何求导呢?
设xi表示RoI pooling层的第i个激活输入,yrj表示该层的第r个RoI的第j个输出,则该层的反向求导为

即反向传播中,L对输入层节点x的梯度为损失函数L对各个有可能的候选区域r输出梯度的累加。
SGD hyper-parameters
全连接层使用softmax分类和bounding box regression,初始化用的是0均值的高斯分布,标准偏差为
0.01和0.001,bias为0。
进行SGD训练时,R-CNN和SPPnet采用RoI-centric sampling,即从所有图片的所有候选区域中均匀取样,这样
每个SGD的mini-batch中包含了不同图像的样本不同图像之间不能共享卷积计算和内存,运算开销大;Fast R-CNN中
采用image-centric sampling:mini-batch采用层次采样,即先对图像采样(N个),再在采样到的图像中对候选区域采样
【每个图像中采样R/N个,一个mini-batch共计R个候选区域样本】,同一图像的候选区域卷积共享计算和内存,降低了运算开销。
Scale invariance
本文采用两种方式来达到尺度不变的目标检测:单一尺度和图像金字塔。
在单一尺度中,不管是训练还是测试,每张图像用固定大小的尺度来处理图像,希望网络从训练数据中直
接学习到尺度不变的特征表达;相比之下,多尺度方法通过图像金字塔提供了一个近似尺度不变给网络。在测试
阶段,图像金字塔为每个object proposal提供近似尺度归一化。在多尺度训练中,当一副图像被采样时,
我们随机采样金字塔尺度。最后的实验表明,多尺度的效果一般。
Fast R-CNN detection
网络输入一张图像和R个object proposals,在测试阶段,R=2000。对于每个测试的RoI r,前向传递输出
一个类别的后验概率分布p,以及一系列的预测bounding box offsets(相对r)。使用估计概率为每个类别k,对
于r,赋于一个检测置信值,并以每个类别使用非极大值抑制。
Truncated SVD for faster detection
对于整个图像分类来说,花在全连接层的时间要比卷积层的时间要少。相反,检测时RoI的数量很大,花费在全连接
层上的时间几乎是前向传播的一半。通过truncated SVD可以很容易加速大的全连接层。
对于u*v个权重的矩阵W,它可以近似分解为:

其中U为u*t,中间为t*t的对角阵,V为v*t的矩阵。SVD将参数由u*v减少为(u+v)*t,为了压缩网络,这个全连接
层变为两个全连接层。
SVM VS softmax
实验表明,采用softmax的效果比SVM的mAP要高。这是因为在softmax在引入了类间竞争,分类效果更好;同时
所有的特征只需存于显存中,不需要额外的磁盘空间。
仍存在的问题
Fast R-CNN中采用selective search算法提取候选区域,而目标检测大多数时间都消耗在这里,而且Fast R-CNN并没有
实现真正意义上的端到端训练模式。
那有没有可能使用CNN直接产生候选区域并对其分类呢?Faster R-CNN框架就是符合这样需求的目标检测框架,请看Faster R-CNN博客。
参考:http://blog.csdn.net/WoPawn/article/details/52463853
r-cnn学习(一)的更多相关文章
- R基础学习
R基础学习 The Art of R Programming 1.seq 产生等差数列:seq(from,to,by) seq(from,to,length) for(i in 1:length(x) ...
- 卷积神经网络(CNN)学习笔记1:基础入门
卷积神经网络(CNN)学习笔记1:基础入门 Posted on 2016-03-01 | In Machine Learning | 9 Comments | 14935 Vie ...
- R语言学习 第四篇:函数和流程控制
变量用于临时存储数据,而函数用于操作数据,实现代码的重复使用.在R中,函数只是另一种数据类型的变量,可以被分配,操作,甚至把函数作为参数传递给其他函数.分支控制和循环控制,和通用编程语言的风格很相似, ...
- CNN学习笔记:批标准化
CNN学习笔记:批标准化 Batch Normalization Batch Normalization, 批标准化, 是将分散的数据统一的一种做法, 也是优化神经网络的一种方法. 在神经网络的训练过 ...
- CNN学习笔记:目标函数
CNN学习笔记:目标函数 分类任务中的目标函数 目标函数,亦称损失函数或代价函数,是整个网络模型的指挥棒,通过样本的预测结果与真实标记产生的误差来反向传播指导网络参数学习和表示学习. 假设某分类任务共 ...
- CNN学习笔记:卷积神经网络
CNN学习笔记:卷积神经网络 卷积神经网络 基本结构 卷积神经网络是一种层次模型,其输入是原始数据,如RGB图像.音频等.卷积神经网络通过卷积(convolution)操作.汇合(pooling)操作 ...
- CNN学习笔记:全连接层
CNN学习笔记:全连接层 全连接层 全连接层在整个网络卷积神经网络中起到“分类器”的作用.如果说卷积层.池化层和激活函数等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的特征表示映射到样 ...
- CNN学习笔记:池化层
CNN学习笔记:池化层 池化 池化(Pooling)是卷积神经网络中另一个重要的概念,它实际上是一种形式的降采样.有多种不同形式的非线性池化函数,而其中“最大池化(Max pooling)”是最为常见 ...
- CNN学习笔记:卷积运算
CNN学习笔记:卷积运算 边缘检测 卷积 卷积是一种有效提取图片特征的方法.一般用一个正方形卷积核,遍历图片上的每一个像素点.图片与卷积核重合区域内相对应的每一个像素值乘卷积核 .内相对应点的权重,然 ...
- CNN学习笔记:激活函数
CNN学习笔记:激活函数 激活函数 激活函数又称非线性映射,顾名思义,激活函数的引入是为了增加整个网络的表达能力(即非线性).若干线性操作层的堆叠仍然只能起到线性映射的作用,无法形成复杂的函数.常用的 ...
随机推荐
- AspectJ基础学习之一简介(转载)
AspectJ基础学习之一简介(转载) 一.为什么写这个系列的博客 Aspectj一个易用的.功能强大的aop编程语言.其官网地址是:http://www.eclipse.org/aspectj/ ...
- linux配置oracle11G监听及本地网络服务 及 数据库建库
配置监听及本地网络服务 在oracle用户的图形界面oracle用户中,新开启一个终端,输入命令netca 会弹出如下界面. 数据库建库 在oracle用户的图形界面oracle用户中,新开启一个终端 ...
- Visual Studio 2012优化
http://msdn.microsoft.com/en-us/library/ms182372.aspx
- Linux下MySQL忘记密码
系统:CentOS6.6 64位 参考文档(截图请看原网址): Linux下MySQL忘记root密码怎么办_百度经验 http://jingyan.baidu.com/article/1709ad8 ...
- memcache相同主域名下的session共享
本配置适合具有相同主域名的多台服务器进行session共享. 例如:www.lee.com , bbs.lee.com(多个子域名). 配置session保存在memcache: ini_set(&q ...
- Oracle VM Virtual
版本5.xx不能导入 要用旧版的4.3.10
- 缺少索引导致的服务器和MYSQL故障。
故障现象: 网站访问缓慢. 数据库RDS: CPU满,连接数满,其他值都是空闲. apache服务器:CPU正常,IO正常,流量报警,内存爆满. 解决思路: 一.没遇到过此情况,一脸懵逼. 二.请教大 ...
- MongoDB学习笔记(索引)(转)
一.索引基础: MongoDB的索引几乎与传统的关系型数据库一模一样,这其中也包括一些基本的优化技巧.下面是创建索引的命令: > db.test.ensureIndex({" ...
- 关于MySQL的SLEEP(N)函数
都知道通过在MySQL中执行select sleep(N)可以让此语句运行N秒钟: ? 1 2 3 4 5 6 7 mysql> select sleep(1); +----------+ | ...
- webapp中的meta
<!--开发后删除--> <meta http-equiv="Pragma" name="no-store" /><!--必须联网 ...