python 基础 基本数据类型
基本类型的补充
str --> 一次性创建的,不能被修改,强制修改就会在创建一个而之前的也会在
list -->允许重复的集合 修改 记录 链表,下一个元素的位置,上一个元素的位置
tuplt --> 允许重复的集合 修改
dict---> 允许重复的集合 修改
set -->不允许重复的集合,修改 也是不允许重复的列表
set 集合
创建方式有两种 s = set() s = {,,,,}
s1 = {11,44,55,66,77}
b1 = {11,22,33,44,55,789}
s1.add(88) #添加某一个元素 不能直接打印
print(s1)
结果
{66, 11, 44, 77, 55, 88}
s1.clear() #清空列表 不能清除一个
print(s1)
结果
set()
i = s1.difference (b1) #找s1中存在 b1中不存在的元素,并赋值给i
print(i)
结果‘
{66, 77}
s1.difference_update(b1) #找某一个存在,某一个不存在元素更新自己的
print(s1)
结果
{66, 77}
i = s1.discard(11)
print(s1) #移除指定元素 没有的也不存在保错
结果
{66, 44, 77, 55}
i = s1.remove(11) #移除指定元素,不存在的报错
print(b1)
结果
{33, 11, 44, 789, 22, 55}
i = s1.intersection(b1) #返回两个集合的交集作为一套新的
print(s1)
结果
{66, 11, 44, 77, 55}
i = s1.isdisjoint(b1) #判断有没有交集,有交集就是False,没有交集就是Ture
print(i)
结果
False
i = s1.issubset(b1) #判断是不是子序列
print(i)
结果
False
i = s1.issuperset(b1) #判断是不是父子列
print(i)
结果
False
i = s1.pop() #删除某一个元素 因为是无序的所以是随机 而删除掉的给会赋值给i变量
print(i)
结果
66
i = s1.symmetric_difference(b1)
print(i) #对称交集 就s1中存在 b1中不存在的 b1中存在 s1中不存在的 并进行合集!
结果
{33, 789, 22, 77}
i = s1.union(b1)
print(i) #并集 合并到一个新的集合
结果
{33, 11, 44, 77, 789, 22, 55}
li = [123,321,32113243]
s1.update()
print(li)
执行结果:[123, 321, 32113243]
三目运算 三元运算
name= 值1 if 1 == 1 sles 值2 如果条件成立就把值1赋给变量 如果条件不成立就把值2 赋给变量
q = 'erzi' if 1==1 else 'sunzi'
print(q) q = 'xin' if 1 !=1 else 'pi'
print(q) D:\python3.5\python.exe D:/untitled/.idea/sanyuan.py
erzi
pi
Process finished with exit code 0
深浅拷贝。 深浅拷贝有copy模块。
导入模块:import copy
浅拷贝:copy.copy
深拷贝:deepcopy
字面理解:浅拷贝指仅仅拷贝数据集合的第一层数据,深拷贝指拷贝数据集合的所有层。
所以对于只有一层的数据集合来说深浅拷贝的意义是一样的,比如字符串,数字。
import copy 先导入模块
q1 = 123
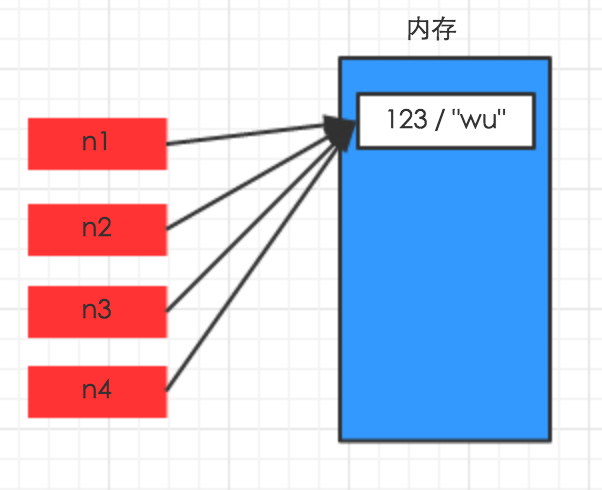
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,其内存地址的变化是不同
赋值 只是创建一个变量,该变量指向原来内存地址,如:
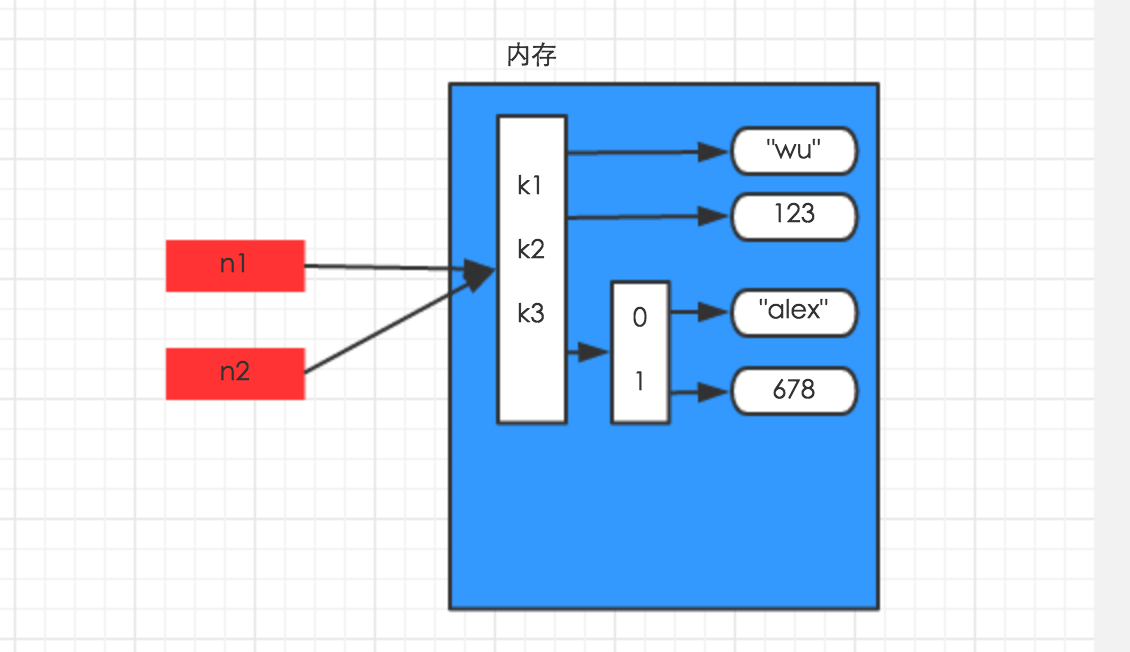
q1 = {'k1':'v1','k2':'v2','k3':['xin',321]}
q2 = q1
print(id(q2))
D:\python3.5\python.exe D:/untitled/q1.py
10040584
Process finished with exit code 0
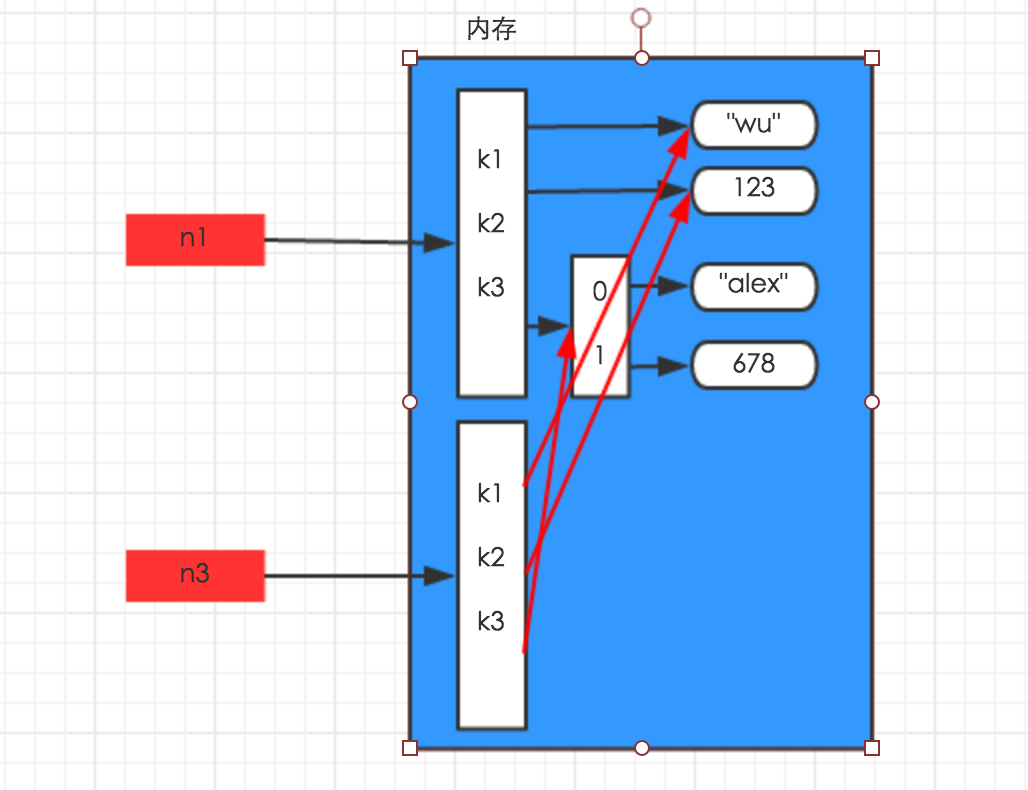
浅拷贝 ,在内存中只额外创建第一层数据 拷贝加赋值 的id地址都一样的
q1 = {'k1':'v1','k2':'v2','k3':['xin',321]}
q2 = copy.copy(q1)
print(id(q1),id(q2))
D:\python3.5\python.exe D:/untitled/q1.py
7503144 15611144
Process finished with exit code 0
深拷贝,全部拷贝,除了最后一层的值
在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
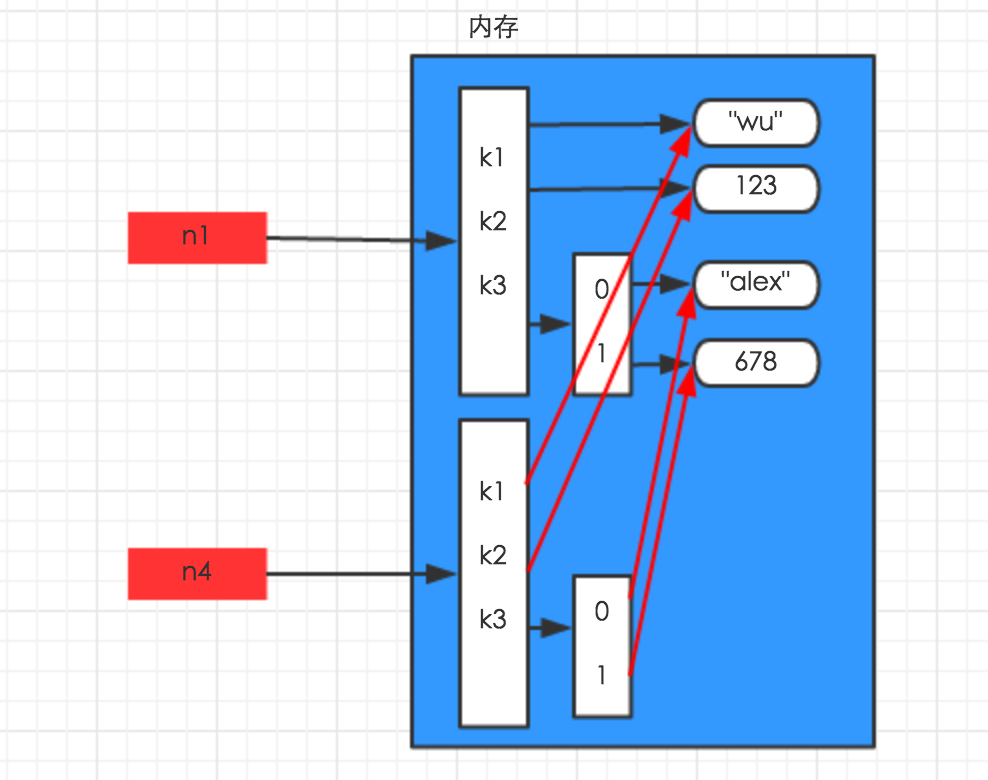
q1 = {'k1':'v1','k2':'v2','k3':['xin',321]}
q2 = copy.deepcopy(q1)
print(id(q1),id(q2))
D:\python3.5\python.exe D:/untitled/q1.py
11238696 12160016
Process finished with exit code 0
函数:
函数 是面向过程编程
函数编程
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
定义函数
def xin(): # 只输入一次 以后可以直接调用 不需要继续重新输入或者复制粘贴
print('qwertryu')
def kai():
print('ertyuidfghjcvbnm')
# #执行函数
xin() #从上往下执行
kai()
# return #就是返回值 每次执行完结果都要定义一个返回值,不定义自动返回HONE
def xin ():
print('xinxinxin')
return 'ok' 记得要定义返回值
ret = xin()
print(ret)
D:\python3.5\python.exe D:/untitled/.idea/sanyuan.py
xinxinxin
ok Process finished with exit code 0
def xin(): 定义函数名称
print('qwe')
ret = xin()执行函数
if ret: 如果返回值是真的
prtint('haha')
else: 否则就是假的
print('gun')
D:\python3.5\python.exe D:/untitled/.idea/sanyuan.py
qwe
gun Process finished with exit code 0
参数 分为 形式参数, 实际参数 , 动态参数
形参 ,实参 (默认的,按照顺序)
指定 形参传入实参,可以不按照顺序
函数可以有默认参数,(有默认值的参数一定要放在参数的尾部)
动态参数 *,元祖 ,元祖的元素
**,字典
形式参数 和 实际参数
def kai (i): #(i) 形式参数,
if i == "123456789": #如果形式参数等于实际参数的值
return True # 就返回成功 下面的代码就不执行了
else: #否则
return False #就返回失败 继续执行 q1 = kai('123456789') #实际参数就是定义的返回值
q2 = kai('789465132')
if q1: #如果执行的实际参数是就是形式参数
print('yes') #就是成功了
else: #否则
print('no') #否则就是失败了 D:\python3.5\python.exe D:/untitled/.idea/sanyuan.py
yes Process finished with exit code 0
执行参数:
def xin(w,x ):
print(w,x)
return'sss'
s = xin(x= 'xx',w= '')
print(s)
执行结果:
33 xx
sss
动态参数
加 * 号就是动态参数
def niu(*a):
print(a,type(a)) #元祖类型
niu(123,456,543,654,432,654,423) D:\python3.5\python.exe D:/untitled/.idea/sanyuan.py
(123, 456, 543, 654, 432, 654, 423) <class 'tuple'> Process finished with exit code 0 def niu (**a): # 字典类型
print(a,type(a))
niu(k1=123,k2=456)
D:\python3.5\python.exe D:/untitled/.idea/sanyuan.py
{'k1': 123, 'k2': 456} <class 'dict'> Process finished with exit code 0 def xin (*a,**aa): 接受和各种类型的参数
print(a,type(a))
print(aa,type(aa))
xin(11,22,k1=23,k2 =123) D:\python3.5\python.exe D:/untitled/.idea/sanyuan.py
(11, 22) <class 'tuple'>
{'k2': 123, 'k1': 23} <class 'dict'> Process finished with exit code 0
一般把一个 *写成 args
** kwargs
也可以写成 *a。**aa。
def q1(* args):
print(args,type(args))
li = [1,2,3,4,5]
q1(li) 元祖里的一个元素
q1(*li) 把每个元素都加入到 元祖里 D:\python3.5\python.exe D:/untitled/.idea/sanyuan.py
([1, 2, 3, 4, 5],) <class 'tuple'>
(1, 2, 3, 4, 5) <class 'tuple'> Process finished with exit code 0
全局变量 局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。
PERSON = 'alex'
###全局变量 全局变量都大写不能被修改 如果要修改的话必须加global
def x1 ():
a = 12
#局部变量 ,都为小写只能在自己的范围内
print(PERSON)
print(a)
x1() D:\python3.5\python.exe D:/untitled/.idea/sanyuan.py
alex
12 Process finished with exit code 0
python 基础 基本数据类型的更多相关文章
- Python基础之数据类型
Python基础之数据类型 变量赋值 Python中的变量不需要声明,变量的赋值操作既是变量声明和定义的过程. 每个变量在内存中创建,都包括变量的标识,名称和数据这些信息. 每个变量在使用前都必须赋值 ...
- 第二章:python基础,数据类型
"""第二章:python基础,数据类型2.1 变量及身份运算补充2.2 二进制数2.3 字符编码每8位所占的空间位一个比特,这是计算机中最小的表示单位.每8个比特组成一 ...
- python基础一数据类型之字典
摘要: python基础一数据类型之一字典,这篇主要讲字典. 1,定义字典 2,字典的基础知识 3,字典的方法 1,定义字典 1,定义1个空字典 dict1 = {} 2,定义字典 dict1 = d ...
- 第一节 Python基础之数据类型(整型,布尔值,字符串)
数据类型是每一种语言的基础,就比如说一支笔,它的墨有可能是红色,有可能是黑色,也有可能是黄色等等,这不同的颜色就会被人用在不同的场景.Python中的数据类型也是一样,比如说我们要描述一个人的年龄:小 ...
- python基础一数据类型之集合
摘要: python基础一中介绍数据类型的时候有集合,所以这篇主要讲集合. 1,集合的定义 2,集合的功能 3,集合的方法 1,集合的定义 list1 = [1,4,5,7,3,6,7,9] set1 ...
- python基础一数据类型之元祖
摘要: python基础一中写到数据类型元祖,那么这篇主要讲元祖. 1,元祖定义 tuple1 = (1,2,'a','b') 元祖是不可变数据,所以又名只读列表.那么如何让是元祖可变呢?可以在元祖中 ...
- python基础一数据类型之列表
摘要: python基础一中写到列表,那么这篇主要讲列表. 1,定义列表 2,列表.元祖.字符串都属于序列,都可以用用索引和切片. 3,列表的方法 1,定义列表 list1 = ['a','b',1, ...
- Python基础一数据类型之数字类型
摘要: python基础一中提到了数据类型,这里主要讲解的是数字类型. 数字类型: 1,整型 2,长整型 3,浮点型 4,复数型 1,整型(int) 定义a = 1 通过type函数查看数据类型,整型 ...
- python基础(二)----数据类型
Python基础第二章 二进制 字符编码 基本数据类型-数字 基本数据类型-字符串 基本数据类型-列表 基本数据类型-元组 可变.不可变数据类型和hash 基本数据类型-字典 基本数据类型-集合 二进 ...
- Python学习day04 - Python基础(2)数据类型基础
<!doctype html>day04 - 博客 figure:last-child { margin-bottom: 0.5rem; } #write ol, #write ul { ...
随机推荐
- 关于webpack.optimize.CommonsChunkPlugin的使用二
Note:当有多个入口节点的时候,只有所有入口节点都引入了同一个模块的时候,webpack.optimize.CommonsChunkPlugin才会将那个模块提取出来,如果其中一个入口节点没有引入该 ...
- sublime text2 配置代码对齐快捷键
menu under Preferences → Key Bindings – User [{"keys": ["ctrl+shift+r"], "c ...
- Fastlane为iOS带来持续部署
Fastlane是一组工具套件,旨在实现iOS应用发布流程的自动化,并且提供一个运行良好的持续部署流程,只需要运行一个简单的命令就可以触发这个流程. Fastlane是一个ruby脚本集合,其中囊括了 ...
- 搜索引擎关键词劫持之.net篇
摘要:蛋疼写的,有需要的就拿去,注意要保存为Global.asax. 重要说明:为避免编码问题,请在劫持页面(data_url)指向页面加入meta标记来指明编码,如 meta content=tex ...
- Parallel.Invoke并行你的代码
Parallel.Invoke并行你的代码 使用Parallel.Invoke并行你的代码 优势和劣势 使用Parallel.Invoke的优势就是使用它执行很多的方法很简单,而不用担心任务或者线程的 ...
- Construct Binary Tree from Inorder and Postorder Traversal
Construct Binary Tree from Inorder and Postorder Traversal Given inorder and postorder traversal of ...
- git 找回丢失的commit
From : http://dmouse.iteye.com/blog/1797267 git 的错误操作,导致丢失了重要的commit,真是痛不欲生: 最后通过git神器终于找回了丢失的commit ...
- 某站出品2016织梦CMS进阶教程共12课(附文档+工具)
此为广告商内容使用最新版的dede cms建站 V5.7 sp1,经常注意后台的升级信息哦!一.安装DEDE的时候数据库的表前缀,最好改一下,不用dedecms默认的前缀dede_,随便一个名称即可. ...
- warning: #870-D: invalid multibyte character sequence
warning: #870-D: invalid multibyte character sequence2011-03-12 9:18warning: #870-D: invalid multiby ...
- ImageMagick常用指令详解
Imagemagick常用指令 (ImageMagick--蓝天白云) (ImageMagick官网) (其他比较有价值的IM参考) (图片自动旋转的前端实现方案) convert 转换图像格式和大小 ...