C++核心编程 1 程序的内存模型
1、内存分区模型
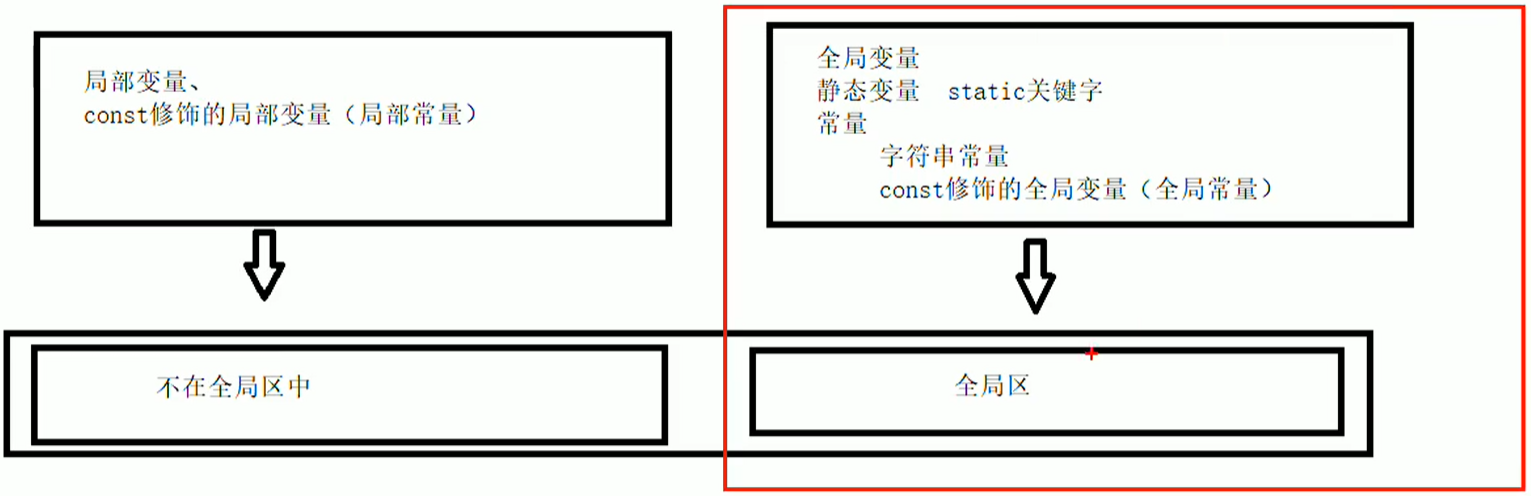
C++程序在执行时,将内存大方向划分为4个区域
代码区:存放函数体的二进制代码,由操作系统进行管理(写的所有代码都在代码区)
全局区:存放全局变量、静态变量以及常量
栈 区:由编译器自动分配释放,存放函数的参数值,局部变量等
堆 区:由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收
内存四区的意义:不同区域的数据,赋予不同的生命周期,给我们更大的灵活编程
程序运行前:
在程序编译后,生成了exe可执行程序,未执行该程序前分为两个区域
代码区:
存放CPU执行的机器指令
代码区是共享的,共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可
代码区是只读的,使其只读的原因是防止程序意外地修改了它的指令
全局区:
全局变量(main函数外面)和静态变量(在普通变量前加static)存放于此
全局区还包含了常量区,字符串常量 ("hello world") 和其他常量(const修饰的全局变量)也存放于此
该区域的数据在程序结束后由操作系统释放
总结:
C++中在程序运行前分为全局区和代码区
代码区特点是共享和只读
全局区中存放全局变量、静态变量、常量
常量区中存放const修饰的全局变量 和 字符串常量
程序运行后:
栈 区:
由编译器自动分配释放,存放函数的参数值,局部变量等
注意:不要返回局部变量的地址,栈区开辟的数据由编译器自动释放
#include<iostream>
using namespace std; //栈区数据注意事项 --- 不要返回局部变量的地址
//栈区的数据由编译器管理开辟和释放 int * func(int b) //形参数据也会放在栈区
{
b = 100;
cout << b << endl;
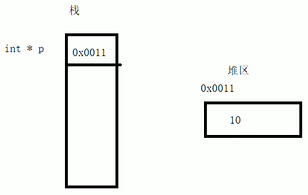
int a = 10; //局部变量 存放栈区,栈区的数据在函数执行完后自动释放
return &a; //返回局部变量的地址
} int main()
{
//接收函数的返回值
int * p = func(1); cout << *p << endl; //第一次可以打印出正确的数据 10 ,是因为编译器防止用户是误操作而做了一次保留
cout << *p << endl; //第二次这个数据就不再保留 打印出来的是乱码 因为局部变量a的内存已经被释放 system("pause");
return 0;
}
打印出来的结果:
堆 区:
由程序员分配释放,若程序员不释放,程序结束时由操作系统回收
在C++中主要利用new在堆区开辟内存
实例:
#include<iostream>
using namespace std; int * func()
{
//利用new关键字 可以将数据开辟到堆区
//指针 本质也是局部变量,放在栈上。指针保存的数据是放在堆区
int * p = new int (10);
return p;
} int main()
{
int * p = func(); //接收函数的返回值 cout << *p << endl;
cout << *p << endl;
system("pause");
return 0;
}
打印结果:
new操作符
C++中利用new操作符在堆区开辟数据
堆区开辟的数据,由程序员手动开辟,手动释放,释放操作符delete
语法:new 数据类型
利用new创建的数据,会返回该数据对应的类型的指针
实例:1、基本语法
#include<iostream>
using namespace std; int * func()
{
//在堆区创建整型数据
//new返回的是 该数据类型的指针
int * p = new int (10);
return p;
} void test1() //new的基本语法
{
int * p = func();
cout << *p << endl;
cout << *p << endl;
cout << *p << endl;
//堆区数据由程序员管理开辟、释放,若想释放 利用关键字delete
delete p;
cout << *p << endl; //内存已经被释放,再次访问就是非法操作,会报错
}
int main()
{
//int * p = func(); //接收函数的返回值
test1(); system("pause");
return 0;
}
打印结果: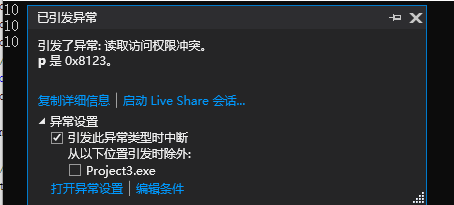 因为delete p 后,p已被释放,故第四次打印出错。
因为delete p 后,p已被释放,故第四次打印出错。
2、在堆区new数组
#include<iostream>
using namespace std; //2、在堆区利用new开辟数组
void test2()
{
//创建10个 整型数据的数组,在堆区
int * arr = new int[10]; //10代表数组有10个元素
for (int i = 0; i < 10; i++)
{
arr[i] = i + 100; //给10个元素赋值 100~109
}
for (int i = 0; i < 10; i++)
{
cout << arr[i] << endl;
}
//释放堆区数组
//释放数组的时候要加[]才可以
delete[] arr;
}
int main()
{
test2();
system("pause");
return 0;
}
打印结果: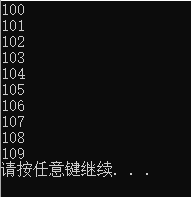
C++核心编程 1 程序的内存模型的更多相关文章
- STM32F4编程手册学习2_内存模型
STM32F4编程手册学习2_内存模型 1. 内存映射 MCU将资源映射到一段固定的4GB可寻址内存上,如下图所示. 内存映射将内存分为几块区域,每一块区域都有一个定义的内存类型,一些区域还有一些附加 ...
- Java并发编程:JMM(Java内存模型)和volatile
1. 并发编程的3个概念 并发编程时,要想并发程序正确地执行,必须要保证原子性.可见性和有序性.只要有一个没有被保证,就有可能会导致程序运行不正确. 1.1. 原子性 原子性:即一个或多个操作要么全部 ...
- Java并发编程:JMM (Java内存模型) 以及与volatile关键字详解
目录 计算机系统的一致性 Java内存模型 内存模型的3个重要特征 原子性 可见性 有序性 指令重排序 volatile关键字 保证可见性和防止指令重排 不能保证原子性 计算机系统的一致性 在现代计算 ...
- JAVA并发编程的艺术 JMM内存模型
锁的升级和对比 java1.6为了减少获得锁和释放锁带来的性能消耗,引入了"偏向锁"和"轻量级锁". 偏向锁 偏向锁为了解决大部分情况下只有一个线程持有锁的情况 ...
- java并发编程(9)内存模型
JAVA内存模型 在多线程这一系列中,不去探究内存模型的底层 一.什么是内存模型,为什么需要它 在现代多核处理器中,每个处理器都有自己的缓存,定期的与主内存进行协调: 想要确保每个处理器在任意时刻知道 ...
- 【Windows核心编程】一个使用内存映射文件进行进程间通信的例子
进程间通信的方式有很多种,其底层原理使用的都是内存映射文件. 本文实现了Windows核心编程第五版475页上的demo,即使用内存映射文件来在进程间通信. 进程1 按钮[Create mappin ...
- [Windows核心编程]32bit程序在64bit操作系统下处理重定向细节[1]
这段时间,都在做Ring3层的普通32bit程序兼容64bit操作系统的代码修改,在此记录修改和学习心德.编程领域太广, 任何人经历有限,本人不是专家,所以我一贯原则是: 用到的时候,才去研究,在去记 ...
- Windows核心编程 第十七章 -内存映射文件(下)
17.3 使用内存映射文件 若要使用内存映射文件,必须执行下列操作步骤: 1) 创建或打开一个文件内核对象,该对象用于标识磁盘上你想用作内存映射文件的文件. 2) 创建一个文件映射内核对象,告诉系统该 ...
- Windows核心编程 第十七章 -内存映射文件(上)
第1 7章 内存映射文件 对文件进行操作几乎是所有应用程序都必须进行的,并且这常常是人们争论的一个问题.应用程序究竟是应该打开文件,读取文件并关闭文件,还是打开文件,然后使用一种缓冲算法,从文件的各个 ...
随机推荐
- 华为oj-判断输入的字符串是不是一个有效的IP地址
题目标题: 判断输入的字符串是不是一个有效的IP地址 详细描述: 请实现如下接口 boolisIPAddressValid(constchar* pszIPAddr) 输入:pszIPAddr 字符串 ...
- Python - 面向对象编程 - @property
前言 前面讲到实例属性的时候,我们可以通过 实例对象.实例属性 来访问对应的实例属性 但这种做法是不建议的,因为它破坏了类的封装原则 正常情况下,实例属性应该是隐藏的,只允许通过类提供的方法来间接实现 ...
- PyQt4制作GUI
时间:2018-11-30 记录:byzqy 标题:PyQt4入门学习笔记(一) 地址:https://www.cnblogs.com/chuxiuhong/p/5865201.html 标题:PyQ ...
- JVM(一)类加载器与类加载过程
JVM是面试必面的一个知识点,也是高级程序员必备的一个技能.以下是JVM整体核心内容,包括类加载系统,运行时数据区内部结构,执行引擎,本地方法接口. 首先来学习类的加载器,虚拟机把描述类的数据从Cla ...
- noip模拟44
A. Emotional Flutter 直接将所有黑块平移到 \([1-k,0]\) 的区间即可,然后找有没有没被覆盖过的整点 注意特判 \(1-k\) 以及 \(0\) 的可行性,考场这里写挂成 ...
- mac、ip、udp头解析
一.MAC帧头定义 /*数据帧定义,头14个字节,尾4个字节*/ typedef struct _MAC_FRAME_HEADER { char m_cDstMacAddress[6]; // ...
- Abp Vnext3 vue-admin-template(三获取用户信息)
因为获取用户比较简单,只需要把用户名及头像地址赋值即可(也许理解错误,如果发现请告知谢谢), 首先将src\api\usr.js中的url请求地址改为以下代码 export function getI ...
- Nginx:多项目开发配置跨域代理
简述Nginx应用场景(前后端) 当我们开发 vue 项目中可以通过 proxyTable 进行跨域,但如果是原生的 html+css+js ,或者其他没有跨域插件的项目中,想要跨域就要引入配置许多的 ...
- Servlet体系结构
一.使用HttpServlet 其中,HttpServlet在重写的service()方法中对http请求的共7中提交方式进行了判断,所以只要我们只要重写对应的请求方式处理逻辑方法 doGet()和d ...
- XML解析——Jsoup解析器
一.Jsoup解析器快速入门案例 Docement对象,文本对象,包含着各个Dom树结构 1.引入Jsoup解析器的jar包放在lib文件夹下后,写java代码 其中, 二.Jsoup对象 1.Jso ...