用一道题 来 复习 MySQL 的 复杂 sql 语句
1.前言
太久没有在数据库做一些复杂的sql了,基本上将数据库的查询逻辑全放在了Java里做,
一来呢,可以减轻数据库的负担,二来呢,在java写,逻辑感会更强,数据类型更丰富也容易操作。
然而。。。面试却喜欢靠复杂的sql ,好吧,即便我不想,但复习一波还是免不了的。
常用的关系型数据库有 MySQL和Oracle 。Oracle 比较喜欢使用存储过程做业务 ,当然,MySQL也可以,但是没怎么用,
自从工程使用mybatis框架,就不再使用存储过程了,业务基本是增删改查,查询数据的逻辑都是从数据库取相应数据出来后用Java计算,
再从数据库获取最终想要的数据,本来是本着减轻数据库负担才这样做的,并发操作会用上积极锁【乐观锁】,因此也就不需要担心 脏数据问题。
MySQL和Oracle的语法部分是不同的,有时候用着MySQL,写着写着就用上了Oracle的语法,还一脸懵逼的查了半天到底哪里错,不常使用的东西就是容易忘。
总结:
(1)Oracle 使用nvl() 函数,MySQL使用 ifnull() 函数 来对数据进行判断是否为空,
如果是空则使用替代的数据 ,参数一样 ,如if(x.age,0),意思是如果年龄字段为空则
输出 0 .
(2)sum()函数是运算函数,允许 加减乘除计算 ,如果要使用,则必须使用
group by 分组 ,限定好分组 sum获取的计算数据才不会错,否则将会导致全表计算在一起。
(3)avg()函数是计算平均数的,用法根据需要与 group by 分组配合使用,
如果是计算全表某字段的平均分,则不要使用。
(4)having 关键字可以筛选分组后的各组数据,也就是说可对分组完成后的数据做逻辑条件判断 ,与where类似,但是where无法这样使用,因为where关键字无法与聚合函数一起使用
2.复习题
数据库源码


/*
Navicat MySQL Data Transfer Source Server : cen
Source Server Version : 50528
Source Host : localhost:3306
Source Database : kktest Target Server Type : MYSQL
Target Server Version : 50528
File Encoding : 65001 Date: 2020-06-17 08:21:15
*/ SET FOREIGN_KEY_CHECKS=0; -- ----------------------------
-- Table structure for bjb
-- ----------------------------
DROP TABLE IF EXISTS `bjb`;
CREATE TABLE `bjb` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8; -- ----------------------------
-- Records of bjb
-- ----------------------------
INSERT INTO `bjb` VALUES ('1', '一班');
INSERT INTO `bjb` VALUES ('2', '2班');
INSERT INTO `bjb` VALUES ('3', '3班'); -- ----------------------------
-- Table structure for cjb
-- ----------------------------
DROP TABLE IF EXISTS `cjb`;
CREATE TABLE `cjb` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`id_sx` int(11) DEFAULT NULL,
`yw` int(11) DEFAULT NULL,
`sx` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8; -- ----------------------------
-- Records of cjb
-- ----------------------------
INSERT INTO `cjb` VALUES ('1', '1', '77', '67');
INSERT INTO `cjb` VALUES ('2', '2', '32', '27');
INSERT INTO `cjb` VALUES ('3', '3', '98', '78');
INSERT INTO `cjb` VALUES ('4', '4', '68', '63');
INSERT INTO `cjb` VALUES ('5', '5', '66', '77');
INSERT INTO `cjb` VALUES ('6', '6', '99', '88');
INSERT INTO `cjb` VALUES ('7', '7', '75', '45');
INSERT INTO `cjb` VALUES ('8', '8', '77', '88');
INSERT INTO `cjb` VALUES ('9', '9', '65', '81');
INSERT INTO `cjb` VALUES ('10', '10', '83', '89'); -- ----------------------------
-- Table structure for xsb
-- ----------------------------
DROP TABLE IF EXISTS `xsb`;
CREATE TABLE `xsb` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`id_banji` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8; -- ----------------------------
-- Records of xsb
-- ----------------------------
INSERT INTO `xsb` VALUES ('1', '岑', '1');
INSERT INTO `xsb` VALUES ('2', 'cen', '1');
INSERT INTO `xsb` VALUES ('3', 'y', '2');
INSERT INTO `xsb` VALUES ('4', 'u', '3');
INSERT INTO `xsb` VALUES ('5', 'yue', '2');
INSERT INTO `xsb` VALUES ('6', 'kk', '2');
INSERT INTO `xsb` VALUES ('7', 'tom', '1');
INSERT INTO `xsb` VALUES ('8', 'lili', '1');
INSERT INTO `xsb` VALUES ('9', 'kile', '3');
INSERT INTO `xsb` VALUES ('10', 'jack', '2');
INSERT INTO `xsb` VALUES ('11', 'hh', '2'); -- ----------------------------
-- Procedure structure for sp_add3
-- ----------------------------
DROP PROCEDURE IF EXISTS `sp_add3`;
DELIMITER ;;
CREATE DEFINER=`root`@`localhost` PROCEDURE `sp_add3`(a int, b int,out c int)
begin
set c=a+ b;
end
;;
DELIMITER ;
kktest.sql
学生表【字段意思:学生id、姓名、班级id】
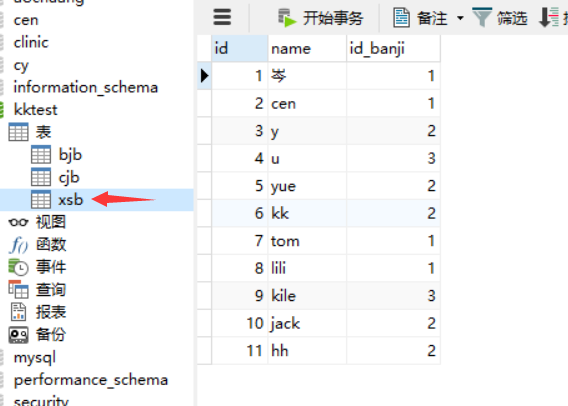
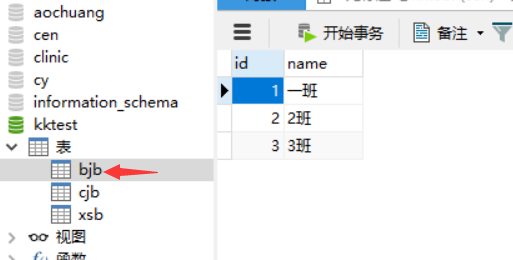
班级表【字段意思:班级id、班级名称】
成绩表【字段意思:成绩id、学生id、语文成绩、数学成绩】

【注意:11号同学hh ,他没有成绩,他作弊被取消了考试资格,因此成绩表没有他的信息】
(1)查询所有学生的信息
写法一:
select x.id,x.name,b.name n from xsb x
left join bjb b on b.id = x.id_banji;
查询结果

写法二:
select x.id,x.name,b.name n2 from xsb x,bjb b
where b.id = x.id_banji;
查询结果与上图一样
(2)查询所有人的课程分数
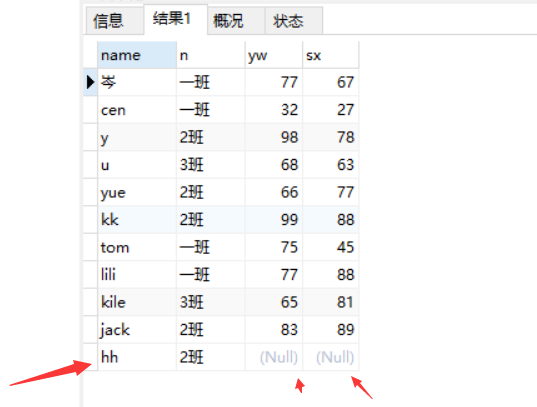
写法一:【查询11号同学为null】
select x.name,b.name n ,c.yw ,c.sx from xsb x
left join bjb b on b.id = x.id_banji
left join cjb c on c.id_sx = x.id ;
查询结果
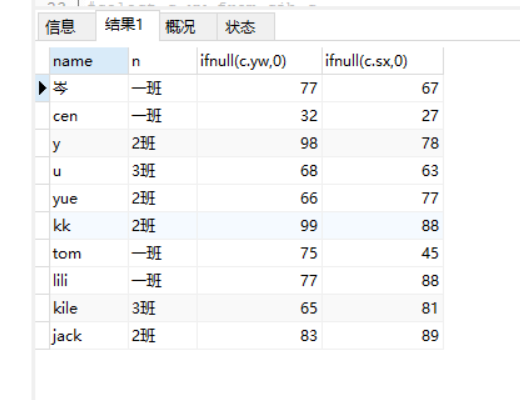
写法二:【查询11号同学为0】
select x.name,b.name n , ifnull(c.yw,0) , ifnull(c.sx,0) from xsb x
left join bjb b on b.id = x.id_banji
left join cjb c on c.id_sx = x.id ;
查询结果

写法三:【查询无11号同学】不使用left join会导致没有成绩的那个同学不显示,因为直接连表查询只会保留所有关联条件成立的数据
select x.name,b.name n , ifnull(c.yw,0) , ifnull(c.sx,0) from xsb x,bjb b,cjb c
WHERE b.id = x.id_banji
and c.id_sx = x.id ;
查询结果
(3)查询语文分数比“yue”的高的学生,【 如果是查询比“yue”的低, 不使用ifnull那么没有成绩的同学无法查看到】
select x.name,b.name n , ifnull(c.yw,0) from xsb x
left join bjb b on b.id = x.id_banji
left join cjb c on c.id_sx = x.id
where ifnull(c.yw,0) >
(
select c.yw from cjb c
left join xsb x on c.id_sx = x.id
where x.name= "yue"
)
查询结果
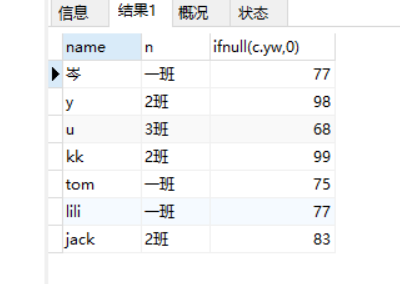
(4)查询各科都合格【分数>=60分】的学生(姓名、语文分数、数学分数)
select x.name , c.yw ,c.sx
from xsb x
left join cjb c on c.id_sx =x.id
WHERE c.yw>60 and c.sx >60
打印结果
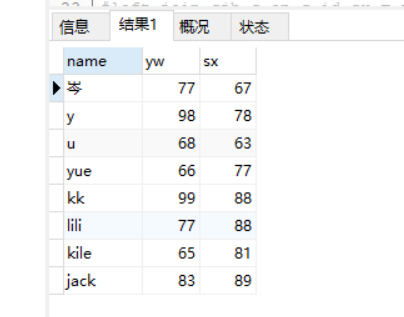
(5)查询总分数(语文+数学)>=150的学生信息(姓名、班级名称、总分数)
select x.name,b.name n ,
ifnull(c.yw,0) as "语文",ifnull(c.sx,0) as "数学",
#sum是运算函数 ,在里面可以做加减乘除
sum(ifnull(c.yw,0) + ifnull(c.sx,0)) as "总分"
from xsb x
left join bjb b on b.id = x.id_banji
left join cjb c on c.id_sx = x.id
where (ifnull(c.yw,0) +ifnull(c.sx,0)) >=150
#计算总分必须要分组,加上这个GROUP BY x.id,表示以一位学生为一组计算总分,否则会全部加在一起
GROUP BY x.id
查询结果
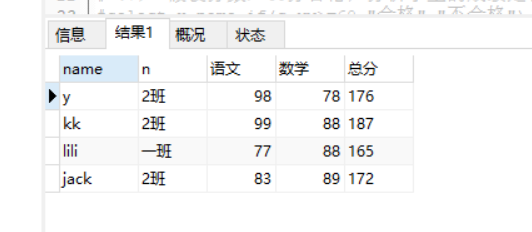
(6)查询没有参加考试【没有成绩表】的学生(姓名、班级名称)
写法一:
select x.name,b.name n from xsb x
left join bjb b on b.id = x.id_banji
left join cjb c on c.id_sx = x.id
where x.id not in (select id_sx from cjb);
查询结果
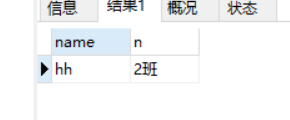
写法二:
select x.name,b.name n from xsb x ,bjb b ,cjb c
WHERE x.id_banji = b.id and x.id not in (select id_sx from cjb)
GROUP BY x.name,b.name ;
查询结果与上图一样
(7)假设分数>=60分合格,分析学生的成绩是否合格
select x.name,if(c.yw>=60,"合格","不合格") as "语文成绩" ,
if(c.sx>=60,"合格","不合格") as "数学成绩"
from xsb x
left join cjb c on c.id_sx = x.id
查询结果

(8)查询有挂科【分数<60分】现象的学生(姓名、语文分数、数学分数)
select x.name ,ifnull( c.yw ,0),ifnull(c.sx,0)
from xsb x
left join cjb c on c.id_sx =x.id
WHERE ifnull( c.yw ,0) <60 or ifnull(c.sx,0)<60;
查询结果
(9)查询所有班级的平均分数(班级编号、班级名称、语文平均分数、数学平均分数)
写法一:
select b.name , AVG(c.yw) as "语文平均分数" ,AVG(c.sx) as "数学平均分数" from xsb x
left join bjb b on b.id = x.id_banji
left join cjb c on c.id_sx = x.id
GROUP BY b.id ;
查询结果

写法二:【主从表换了没影响】
select b.name , AVG(c.yw) as "语文平均分数" ,AVG(c.sx) as "数学平均分数" from bjb b
left join xsb x on b.id = x.id_banji
left join cjb c on c.id_sx = x.id
GROUP BY b.id
查询结果与上图一样
(10)查询班级人数>=3的班级(班级编号、班级名称、人数)
select b.id ,b.name , count(x.id) as "人数"
from bjb b
left join xsb x on b.id = x.id_banji
#HAVING 子句可以让我们筛选分组后的各组数据。
group by b.id having count(x.id) >=3
查询结果

用一道题 来 复习 MySQL 的 复杂 sql 语句的更多相关文章
- MySQL 常用的sql语句小结(待续)
mysql 常用的sql语句 1.查看数据库各个表中的记录数 USE information_schema; SELECT table_name,table_rows FROM tables WHER ...
- mysql使用基础 sql语句(一)
csdn博文地址:mysql使用基础 sql语句(一) 点击进入 命令行输入mysql -u root -p,回车再输入密码,进入mysql. 终端命令以分号作为一条语句的结束,可分为多行输入,只需 ...
- 监控mysql执行的sql语句
linux平台 监控mysql执行的sql语句 为了做好配合开发做性能和功能测试,方便监控正在执行的sql语句, 可以在/etc/mysqld中添加如下: log =/usr/local/mys ...
- MySQL的常用SQL语句.md
修改密码 这是常见的大家一般都要用的 首先 安装成功了打开cmd --> mysql -u root -p -->输入你的密码 修改mysql root用户密码 格式 ...
- mysql统计类似SQL语句查询次数
mysql统计类似SQL语句查询次数 vc-mysql-sniffer 工具抓取的sql分析. 1.先用shell脚本把所有enter符号替换为null,再根据语句前后的字符分隔语句 grep -Ev ...
- MySQL中执行sql语句错误 Error Code: 1093. You can't specify target table 'car' for update in FROM clause
MySQL中执行sql语句错误 Error Code: 1093. You can't specify target table 'car' for update in FROM clause 201 ...
- Oracle,SQL Server 数据库较MySql数据库,Sql语句差异
原文:Oracle,SQL Server 数据库较MySql数据库,Sql语句差异 Oracle,SQL Server 数据库较MySql数据库,Sql语句差异 1.关系型数据库 百度百科 关系数据库 ...
- 浅谈MySQL中优化sql语句查询常用的30种方法 - 转载
浅谈MySQL中优化sql语句查询常用的30种方法 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中使 ...
- mysql(数据库,sql语句,普通查询)
第1章 数据库 1.1 数据库概述 l 什么是数据库 数据库就是存储数据的仓库,其本质是一个文件系统,数据按照特定的格式将数据存储起来,用户可以对数据库中的数据进行增加,修改,删除及查询操作. l 什 ...
随机推荐
- 关于python中显存回收的问题
技术背景 笔者在执行一个Jax的任务中,又发现了一个奇怪的问题,就是明明只分配了很小的矩阵空间,但是在多次的任务执行之后,显存突然就爆了.而且此时已经按照Jax的官方说明配置了XLA_PYTHON_C ...
- AtCoder Beginner Contest 184 题解
AtCoder Beginner Contest 184 题解 目录 AtCoder Beginner Contest 184 题解 A - Determinant B - Quizzes C - S ...
- 盘点 2021|「避坑宝典」为大家分享一下笔者在 2021 年所遇到“匪夷所思”的 Bug 趣事(上)
正版内容:https://xie.infoq.cn/article/3145cd5f525fe26ce9d574c8d 2021尾声想跟大家说的话 虚则实之 引用 https://xie.infoq. ...
- 制作ota差分包
制作ota包 . build/envsetup.sh lunch [product] make -j8 make otapackage -j8 cp out/target/product/projec ...
- Solon 1.6.10 重要发布,现在有官网喽!
关于官网 千呼万唤始出来: https://solon.noear.org .整了一个月多了,总体样子有了...还得不断接着整! 关于 Solon Solon 是一个轻量级应用开发框架.支持 Web. ...
- 使用iframe实现上下窗口结构及登录页全窗口展示Demo
iframe.html 首页 <!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> < ...
- flink使用命令开始、停止任务
命令操作 进行flink的安装目录 动态上传jar包启动job ./bin/flink run -c com.test.CountMain -P 3 Test-1. 0-SNAPSHOT.jar -- ...
- Xftp设置指定记事本(notepad++)打开文件
右键
- 使用WebUploader进行文件图片上传
官方文档:http://fex.baidu.com/webuploader/getting-started.html 引入Webuploader的css和js文件,下载地址:http://fex.ba ...
- [LeetCode] 448. Find All Numbers Disappeared in an Array 找到数组中消失的数字
题目描述 给定n个数字的数组,里面的值都是1-n,但是有的出现了两遍,因此有的没有出现,求没有出现值这个数组中的值有哪些. 要求不能用额外的空间(除了返回列表之外),时间复杂度n 思路 因为不能用额外 ...