莫烦python教程学习笔记——总结篇
一、机器学习算法分类:
监督学习:提供数据和数据分类标签。——分类、回归
非监督学习:只提供数据,不提供标签。
半监督学习
强化学习:尝试各种手段,自己去适应环境和规则。总结经验利用反馈,不断提高算法质量
遗传算法:淘汰弱者,留下强者,进行繁衍和变异穿产生更好的算法。
二、选择机器学习算法和数据集
sklearn中有很多真实的数据集可以引入,也可以根据自己的需求自动生成多种数据集。对于数据集可以对其进行归一化处理。
sklearn中的有着多种多样的算法,每一种算法都有其适用的场合、不同的属性和功能,按需选择。
三、评价机器学习算法:
1、算法效果不好:在训练过程中,可能因为数据集问题,学习效率,参数问题可能导致算法效果不好。
2、评价学习算法:将数据集分为训练集和测试集,根据算法在测试集上的表现评价算法,随着训练时间变长,网络层数变多,误差变小,精确度变高,但是变化的速度都是减缓的。
不同的模型有着是个自己的不同的评分方法:
R2-score:衡量回归问题的精度。最大精度也是100%
F1-score:用于测量不均衡数据的精度。
3、交叉验证用于调参(手动写循环):用于算法的调参(不同的参数也就是不同的模型)。
用交叉验证的方法进行调参或者模型选择时不需要手动划分用于k折验证的数据集,只需要将X和Y,还有k作为参数传进去即可:
#for regreesion
losss=-cross_val_score(knn,X,y,cv=10,scoring=’mean_squared_error’)
#for classification
scores=cross_val_score(knn,X,y,cv=10,scoring=’accuracy’)
交叉验证时,对于模型的评分,分类时用精确度accuracy来衡量模型表现,回归时用损失值mean_squard_error来衡量模型表现。
losss和 scores是两个数组,数组的长度为交叉验证的分割份数。
可使用scores.mean()来得到交叉验证的平均分数。
改变Knn中的参数值,根据交叉验证的得分高低来选择合适的模型参数。
4、learn_curve曲线用于过拟合问题:横轴数据量,纵轴模型得分
过拟合:对于样本的过度学习,过分关注样本的细节。
解决过拟合:L1/L2 regularization,dropout(留出法)
为了找出欠拟合和过拟合的节点我们可以绘制learn_curve曲线,这是一个根据数据量不同显示算法性能的图。显示了过拟合问题的两种误差:蓝色是traindata的算法表现,红色是testdata的算法表现。因为模型是基于traindata进行训练的,所以其在traindata上的表现更好一些。

train_sizes,train_loss,test_loss=learning_curve(
SVC(gramma=0.001),
X,
y,
Cv=10.
Scoring=’mean_squard_error’,
Train_sizes=[0.1,0.25,0.5,0.75,1])
Train_loss_mean=-np.mean(train_loss,axis=1) #10次交叉验证结果取平均
Test_loss_mean=-np.mean(test_loss,axis=1)
train_loss,test_loss是二维数组,长度为5,即为Train_sizes的步数
train_loss[0]是一个数组,存放0.1数据量时10个交叉验证的结果。
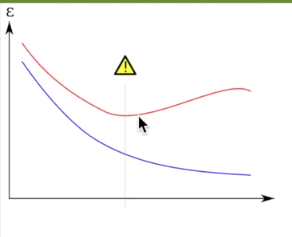
如上图所示,黄色警告处即为欠拟合和过拟合的分界点处。
5、使用交叉验证validation_curve自动调参:横坐标是模型参数,纵坐标是模型交叉验证得分
param_range = np.logspace(-6, -2.3, 5)
train_loss, test_loss = validation_curve(
SVC(), X, y, param_name='gamma', param_range=param_range, cv=10,
scoring='mean_squared_error')
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
plt.plot(param_range, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(param_range, test_loss_mean, 'o-', color="g",
label="Cross-validation")
plt.xlabel("gamma")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
train_loss,test_loss是二维数组,长度为参数的取值个数
train_loss[0]是一个数组,存放参数为某一个值时10个交叉验证的结果。
以模型参数为横坐标,以模型交叉验证得分为纵坐标绘图,最低点即为最佳参数。
莫烦python教程学习笔记——总结篇的更多相关文章
- 莫烦python教程学习笔记——保存模型、加载模型的两种方法
# View more python tutorials on my Youtube and Youku channel!!! # Youtube video tutorial: https://ww ...
- 莫烦python教程学习笔记——validation_curve用于调参
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦python教程学习笔记——learn_curve曲线用于过拟合问题
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦python教程学习笔记——利用交叉验证计算模型得分、选择模型参数
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦python教程学习笔记——数据预处理之normalization
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦python教程学习笔记——线性回归模型的属性
#调用查看线性回归的几个属性 # Youtube video tutorial: https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg # ...
- 莫烦python教程学习笔记——使用波士顿数据集、生成用于回归的数据集
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦python教程学习笔记——使用鸢尾花数据集
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦大大TensorFlow学习笔记(9)----可视化
一.Matplotlib[结果可视化] #import os #os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf i ...
随机推荐
- OpenShift S2I 概念及流程
S2I 概念 S2I(Source To Image)即从源码到镜像的一个过程,OpenShift 将它作为基础功能提供给用户,包含 S2I CLI 工具 与 S2I 流程.通过这些工具和既定流程,能 ...
- 设计模式学习-使用go实现观察者模式
观察者模式 定义 适用场景 优点 缺点 代码实现 不同场景的实现方式 观察模式和发布订阅模式 参考 观察者模式 定义 观察者模式(Observer Design Pattern)定义了一种一对多的依赖 ...
- 躺平吧,平铺的窗口「GitHub 热点速览 v.21.47」
作者:HelloGitHub-小鱼干 用 macOS 系统经常会遇到的一个问题便是多开窗口如何快速找寻的问题,本周特推项目 yabai 便是来解决这个问题的.直接把所有窗口平铺,是不是很"正 ...
- [luogu7831]Travelling Merchant
考虑不断找到以下两种类型的边,并维护答案: 1.终点出度为0的边,那么此时即令$ans_{x}=\min(ans_{x},\max(r,ans_{y}-p))$ 2.(在没有"终点出度为0 ...
- Maven的pom.xml的格式与约束
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/20 ...
- 基于Vue简易封装的快速构建Echarts组件 -- fx67llQuickEcharts
fx67llQuickEcharts A tool to help you use Echarts quickly! npm 组件说明 这本来是一个测试如何发布Vue组件至npm库的测试项目 做完之后 ...
- Codeforces 566C - Logistical Questions(点分治)
Codeforces 题目传送门 & 洛谷题目传送门 神仙题 %%% 首先考虑对这个奇奇怪怪的 \(t^{3/2}\) 进行一番观察.考虑构造函数 \(f(x)=ax^{3/2}+b(d-x) ...
- WC 2007 剪刀石头布
WC 2007 剪刀石头布 看到这个三元环的问题很容易可以考虑到求不合法的三元环的数量的最小值. 什么情况不合法?既然不合法,当且仅当三元环中有一个人赢了另外两个人.所以我们考虑对于一个人而言,如果她 ...
- 【GS基础】植物基因组选择研究人员及数量遗传学发展一览
目录 1.GS研究 2.数量遗传发展 GS应用主要在国外大型动物和种企,国内仍以学术为主.近期整理相关学术文献,了解到一些相关研究人员,记录下备忘查询,但不可能全面. 1.GS研究 Theo Meuw ...
- Perl调用和管理外部文件中的变量(如软件和数据库配置文件)
编写流程时,有一个好的习惯是将流程需要调用的软件.数据库等信息与脚本进行分离,这样可以统一管理流程的软件和数据库等信息,当它们路径改变或者升级的时候管理起来就很方便,而不需要去脚本中一个个寻找再修改. ...