selenium在爬虫中的使用
一. selenium概述
1.1 定义
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,Selenium 可以直接调用浏览器,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器),可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏等。我们可以使用selenium很容易完成爬虫的编写。
1.2 作用与工作原理
利用浏览器原生的API,封装成一套更加面向对象的Selenium WebDriver API,直接操作浏览器页面里的元素,甚至操作浏览器本身(截屏,窗口大小,启动,关闭,安装插件,配置证书之类的)
二. selenium的安装
2.1 在python中安装selenium模块
pip install selenium
2.2下载webdriver(以edge浏览器为例)
查看edge浏览器的版本,可以看到我这里为98.0.1108.62
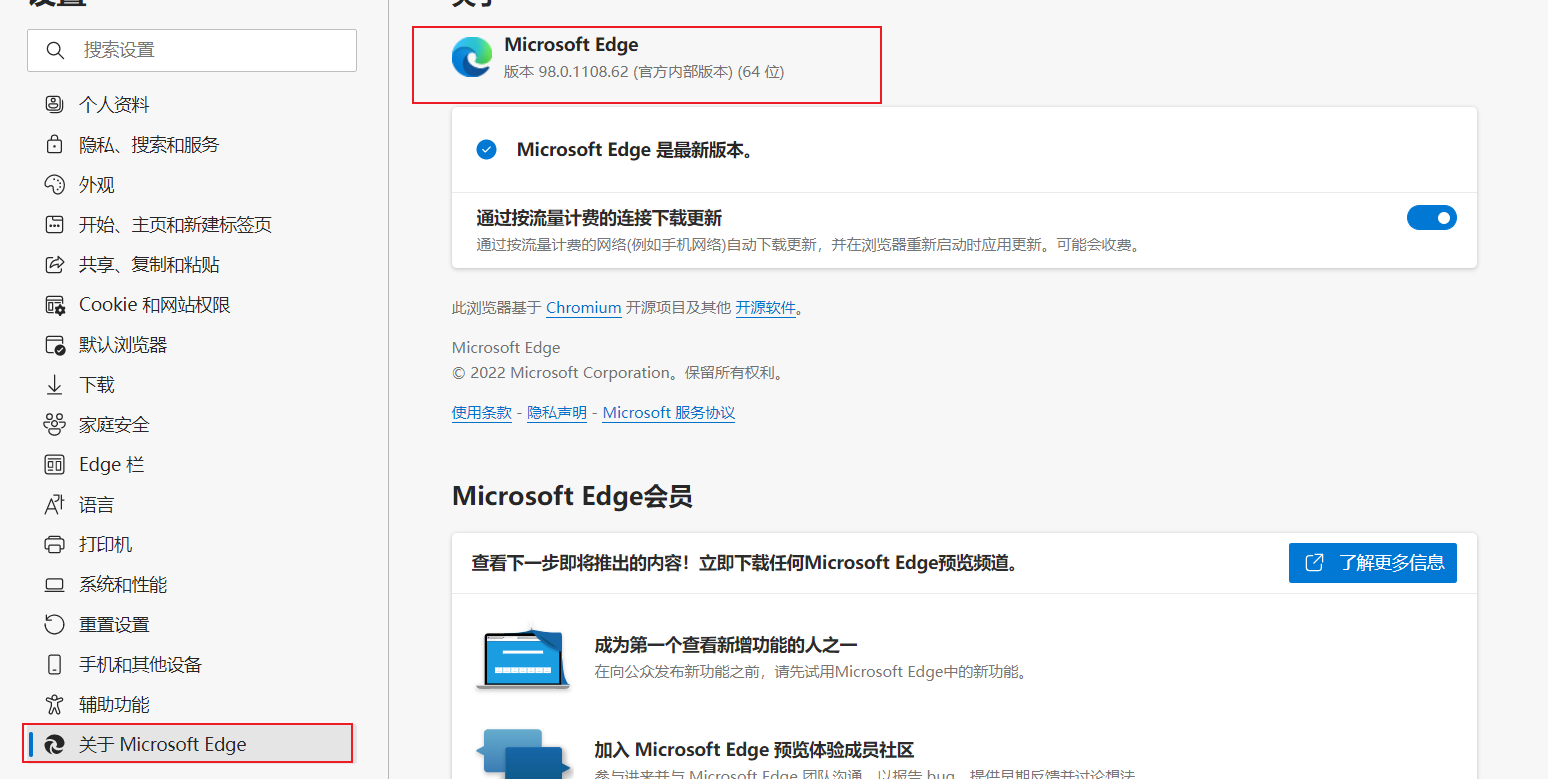
webdriver不同浏览器下载地址,这里使用edge驱动
chrome驱动:http://chromedriver.storage.googleapis.com/index.html
Firefox驱动:https://github.com/mozilla/geckodriver/releases/
edge驱动:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
找到对应版本,点击x64即可下载
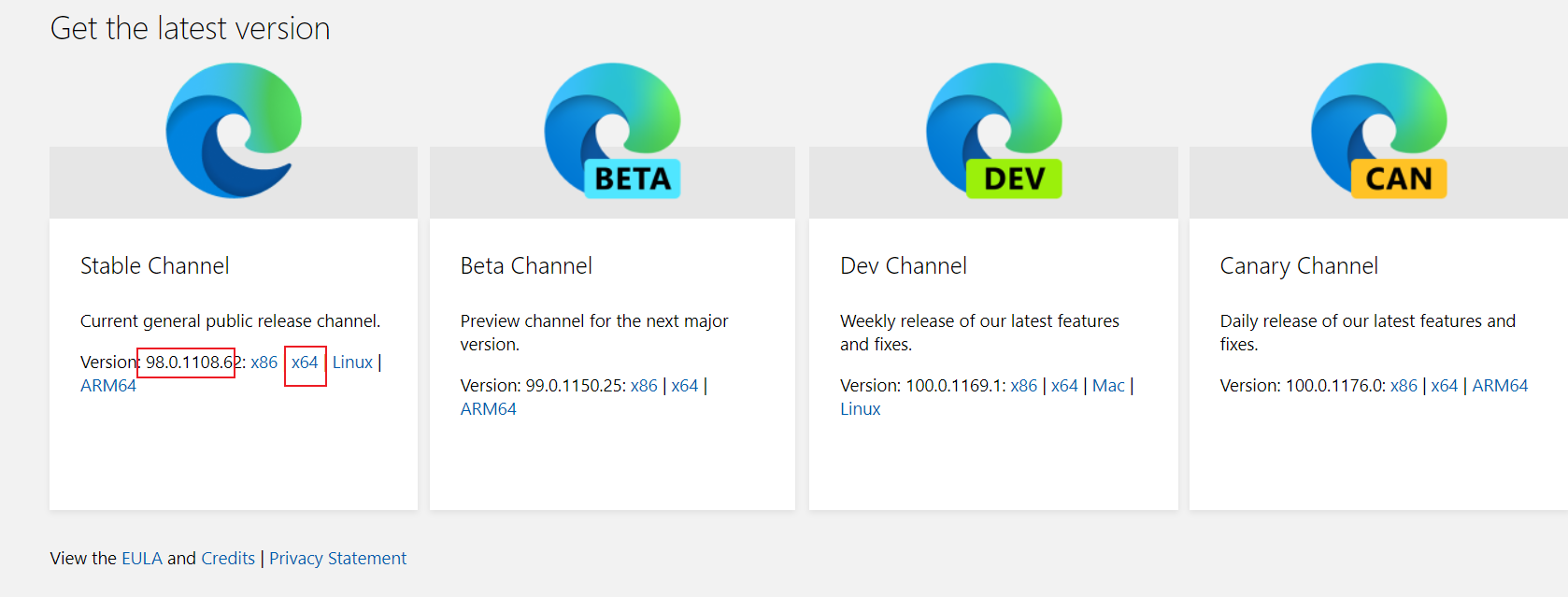
2.3 配置环境
将其下载得到的msedgedriver.exe文件放在edge浏览器的目录下
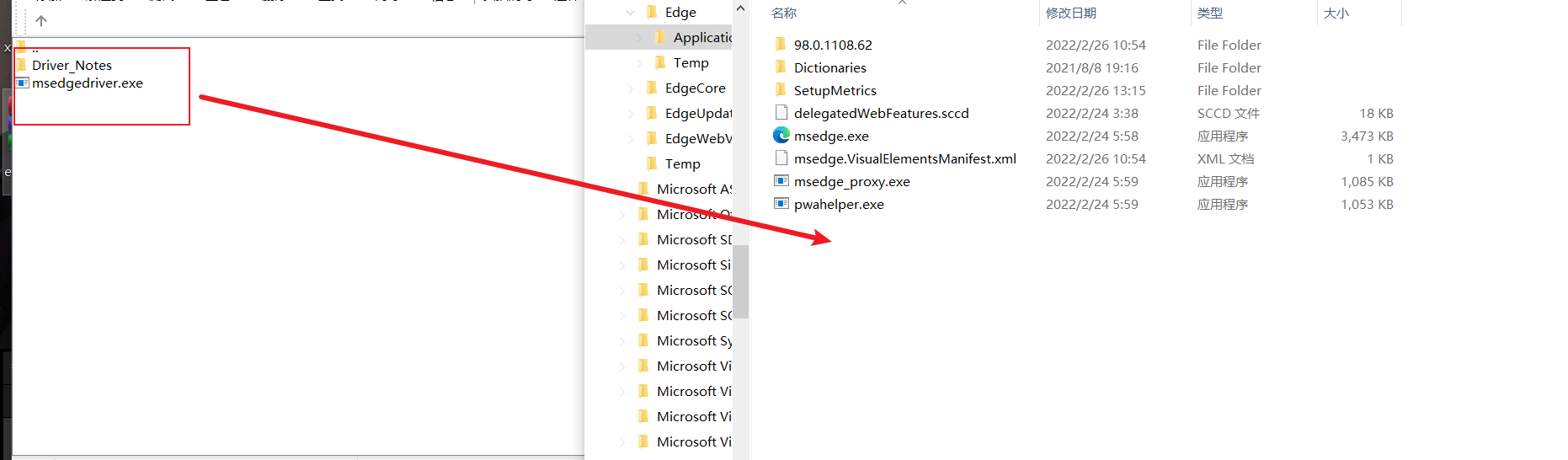
将msedgedriver.exe文件所在目录的路径加到环境变量中
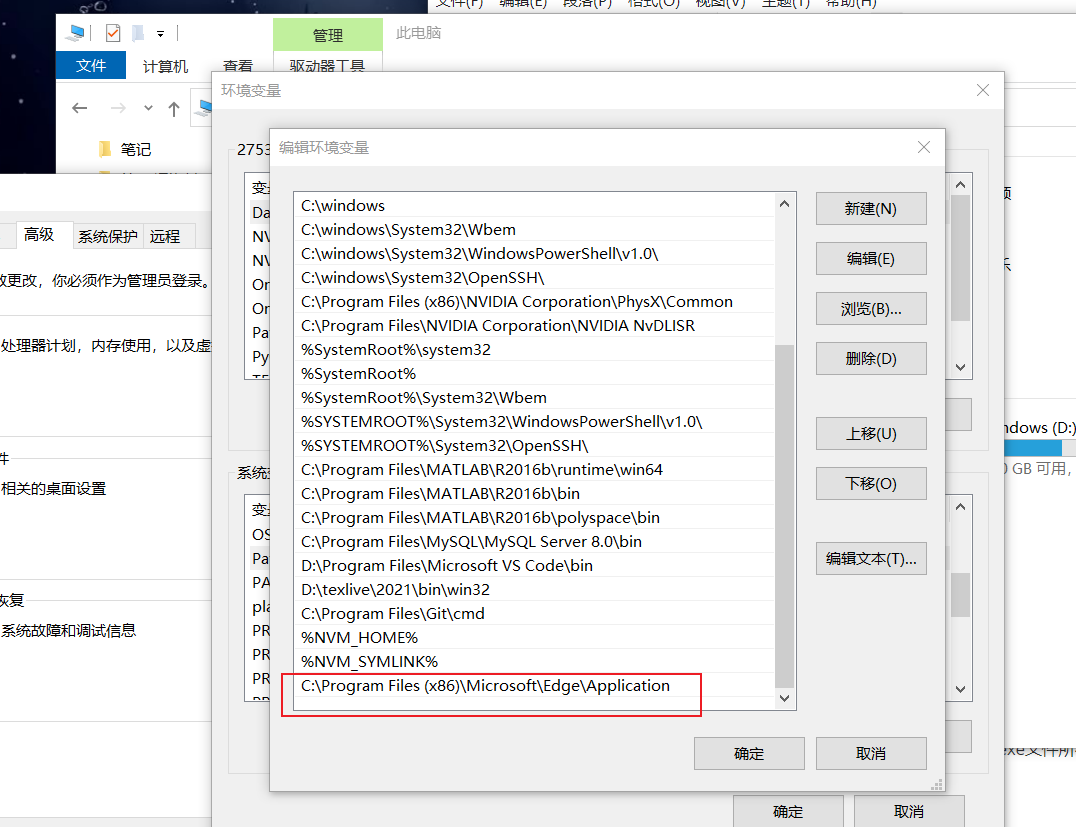
2.4 简单应用
运用python打开浏览器,在百度中搜索python
import time
from selenium import webdriver
#创建驱动对象
#注册环境变量的
# driver=webdriver.Edge()
#没有注册的executable_path中放驱动所在的路径
driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
driver.get('http://www.baidu.com')
time.sleep(5)
#在百度搜索框中搜索python
driver.find_element_by_id('kw').send_keys('python')
driver.find_element_by_id('su').click()
time.sleep(6)
driver.quit()
三. driver对象
上面的例子大概有了webdriver的基本使用,下面创建一个driver对象
from selenium import webdriver
#创建驱动对象
#注册环境变量的
# driver=webdriver.Edge()
#没有注册的executable_path中放驱动所在的路径
driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
3.1 driver对象的常用属性和方法
在使用selenium过程中,实例化driver对象后,driver对象有一些常用的属性和方法
- driver.page_source 当前标签页浏览器渲染之后的网页源代码(不涉及到抓包源码,只需要拷贝就好了)
- driver.current_url 当前标签页的url(响应的)
- driver.close() 关闭当前标签页,如果只有一个标签页则关闭整个浏览器
- driver.quit() 关闭浏览器
- driver.forward() 页面前进
- driver.back() 页面后退
- driver.save_screenshot(img_name) 页面截图
3.2 定位标签元素
在selenium中可以通过多种方式来定位标签,返回标签元素对象
find_element_by_id (返回一个元素)
find_element(s)_by_class_name (根据类名获取元素列表)
find_element(s)_by_name (根据标签的name属性值返回包含标签对象元素的列表)
find_element(s)_by_xpath (返回一个包含元素的列表)
find_element(s)_by_link_text (根据链接文本获取元素列表)
find_element(s)_by_partial_link_text (根据链接包含的文本获取元素列表)
find_element(s)_by_tag_name (根据标签名获取元素列表)
find_element(s)_by_css_selector (根据css选择器来获取元素列表)
注意:
- find_element和find_elements的区别:
- 多了个s就返回列表,没有s就返回匹配到的第一个标签对象
- find_element匹配不到就抛出异常,find_elements匹配不到就返回空列表
- by_link_text和by_partial_link_text的区别:全部文本和包含某个文本
3.3 提取文本内容
find_element仅仅能够获取元素,不能够直接获取其中的数据,如果需要获取数据需要使用以下方法
- 对元素执行点击操作
element.click()- 对定位到的标签对象进行点击操作
- 向输入框输入数据
element.send_keys(data)- 对定位到的标签对象输入数据
- 获取文本
element.text- 通过定位获取的标签对象的 text 属性,获取文本内容
- 获取属性值
element.get_attribute("属性名")- 通过定位获取的标签对象的 get_attribute 函数,传入属性名,来获取属性的值
小栗子:
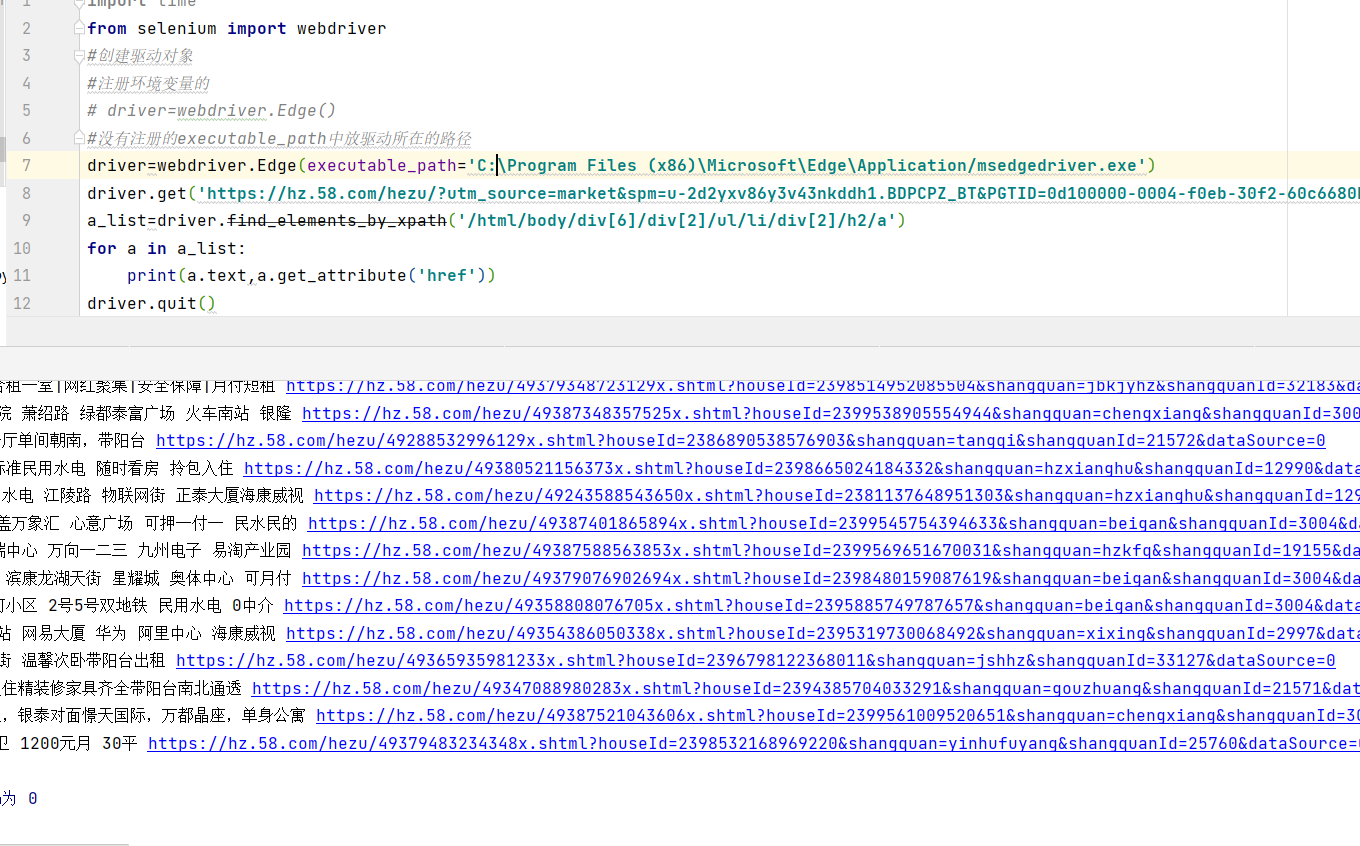
以58同城-->合租为例,抓取当前页面的所有房屋名称和链接
import time
from selenium import webdriver
#创建驱动对象
#注册环境变量的
# driver=webdriver.Edge()
#没有注册的executable_path中放驱动所在的路径
driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
driver.get('https://hz.58.com/hezu/?utm_source=market&spm=u-2d2yxv86y3v43nkddh1.BDPCPZ_BT&PGTID=0d100000-0004-f0eb-30f2-60c6680bc9c2&ClickID=2')
a_list=driver.find_elements_by_xpath('/html/body/div[6]/div[2]/ul/li/div[2]/h2/a')
for a in a_list:
print(a.text,a.get_attribute('href'))
driver.quit()
运行结果:
四. selenium标签页的切换
4.1 网页标签页切换
当selenium控制浏览器打开多个标签页时,如何控制浏览器在不同的标签页中进行切换呢?需要
我们做以下两步:
获取所有标签页的窗口句柄
利用窗口句柄字切换到句柄指向的标签页
这里的窗口句柄是指:指向标签页对象的标识
具体方法
# 1. 获取当前所有的标签页的句柄构成的列表
current_windows = driver.window_handles # 2. 根据标签页句柄列表索引下标进行切换
driver.switch_to.window(current_windows[0])
例子:
打开两个页面,并切换到第二个
import time
from selenium import webdriver
driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
driver.get('http://www.baidu.com')
time.sleep(3)
driver.find_element_by_id('kw').send_keys('python')
driver.find_element_by_id('su').click()
#通过执行js,开启一个标签
js='window.open("https://www.sogou.com")'
# 执行js代码
driver.execute_script(js)
#获取所有窗口
windows=driver.window_handles
time.sleep(3)
#根据窗口索引切换
driver.switch_to.window(windows[0])
time.sleep(3)
driver.switch_to.window(windows[1])
time.sleep(3)
driver.quit()
二级58爬取
import time
from selenium import webdriver
#创建驱动对象
#注册环境变量的
# driver=webdriver.Edge()
#没有注册的executable_path中放驱动所在的路径
driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
driver.get('http://www.58.com')
time.sleep(1)
# 点击合租链接
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[1]/div/div[1]/div[1]/span[3]/a').click()
time.sleep(1)
#切换窗口
driver.switch_to.window(driver.window_handles[-1])
time.sleep(1)
#通过xpath找到对象列表
a_list=driver.find_elements_by_xpath('/html/body/div[6]/div[2]/ul/li/div[2]/h2/a')
for a in a_list:
print(a.text,a.get_attribute('href'))
driver.quit()
4.2 iframe标签切换
frame是html中常用的一种技术,即一个页面中嵌套了另一个网页,selenium默认是访问不了
iframe中的内容的,对应的解决思路是
通过xpath找到iframe对象 frame_element(xpath也是看不到内容的)
通过driver.switch_to.frame(frame_element)就可以进入到iframe的页面了
通过id找到“账户密码登录”的连接,点击它进入“账户密码登录页面”
通过id找到账号和密码的输入框以及登录的按钮
例子:登录QQ空间
import time
from selenium import webdriver
#创建驱动对象
#注册环境变量的
# driver=webdriver.Edge()
#没有注册的executable_path中放驱动所在的路径
driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
driver.get('http://i.qq.com')
time.sleep(1)
l_iframe=driver.find_element_by_xpath('//*[@id="login_frame"]')
print(l_iframe)
#进入ifram标签页
driver.switch_to.frame(l_iframe)
driver.find_element_by_id('switcher_plogin').click()
time.sleep(1)
#输入账号
driver.find_element_by_id('u').send_keys('你的QQ账号')
time.sleep(1)
#输入密码
driver.find_element_by_id('p').send_keys('*你的密码')
time.sleep(1)
driver.find_element_by_id('login_button').click()
time.sleep(10)
#滑块标签,手动拖后再来一次
driver.find_element_by_id('login_button').click()
driver.quit()
五. 获取cookies
5.1 cookie概述
Cookie,有时也用其复数形式Cookies,指某些网站为了辨别用户身份、进行session跟踪而储存在用
户本地终端上的数据(通常经过加密)。定义于RFC2109和2965都已废弃,最新取代的规范是RFC6265。
Cookie是由服务器端生成,发送给User-Agent(一般是浏览器),浏览器会将Cookie的key/value保
存到某个目录下的文本文件内,下次请求同一网站时就发送该Cookie给服务器(前提是浏览器设置为启
用cookie)。Cookie名称和值可以由服务器端开发自己定义,对于JSP而言也可以直接写入jsessionid,
这样服务器可以知道该用户是否合法用户以及是否需要重新登录等。
用途
服务器可以利用Cookies包含信息的任意性来筛选并经常性维护这些信息,以判断在HTTP传输中的
状态。Cookies最典型的应用是判定注册用户是否已经登录网站,用户可能会得到提示,是否在下一次
进入此网站时保留用户信息以便简化登录手续,这些都是Cookies的功用。另一个重要应用场合是“购物
车”之类处理。用户可能会在一段时间内在同一家网站的不同页面中选择不同的商品,这些信息都会写入
Cookies,以便在最后付款时提取信息。
5.2 获取cookie
driver.get_cookies() 返回列表,其中包含的是完整的cookie信息!不光有name、value,还
有domain等cookie其他维度的信息。所以如果想要把获取的cookie信息和requests模块配合使用
的话,需要转换为name、value作为键值对的cookie字典
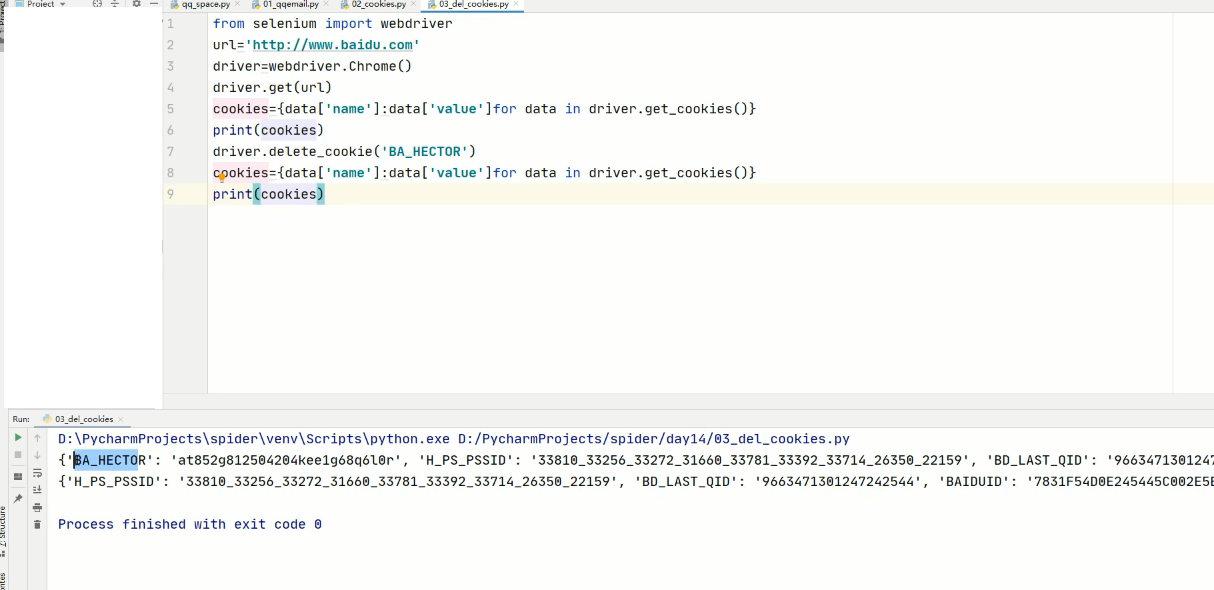
# 获取当前标签页的全部cookie信息
print(driver.get_cookies())
# 把cookie转化为字典
cookies_dict = {cookie[‘name’]: cookie[‘value’]} for cookie in
driver.get_cookies()}
5.3 删除cookie
#删除一条cookie
driver.delete_cookie("CookieName")
# 删除所有的cookie
driver.delete_all_cookies()
六. 页面等待
6.1 强制等待
- 其实就是time.sleep()
- 缺点时不智能,设置的时间太短,元素还没有加载出来;设置的时间太长,则会浪费时间
6.2 隐式等待
- 隐式等待针对的是元素定位,隐式等待设置了一个时间,在一段时间内判断元素是否定位成功,如
果完成了,就进行下一步 - 在设置的时间内没有定位成功,则会报超时加载
- 示例代码
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(10) # 隐式等待,最长等10秒
driver.get('https://www.baidu.com')
driver.find_element_by_xpath()
6.3 显示等待
每经过多少秒就查看一次等待条件是否达成,如果达成就停止等待,继续执行后续代码
如果没有达成就继续等待直到超过规定的时间后,报超时异常
import time
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.common.by import By
#创建驱动对象
#注册环境变量的
# driver=webdriver.Edge()
#没有注册的executable_path中放驱动所在的路径
driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
driver.get('http://baidu.com')
WebDriverWait(driver,20,0.5).until(
ec.presence_of_element_located((By.LINK_TEXT,'hao123'))
)
print(driver.find_element_by_link_text('hao123').get_attribute('href'))
driver.quit()
七. selenium反反爬
7.1 使用代理ip
使用代理ip的方法
#实例化配置对象
options = webdriver.ChromeOptions()
#配置对象添加使用代理ip的命令
options.add_argument('--proxy-server=http://202.20.16.82:9527')
实例化带有配置对象的driver对象
#driver = webdriver.Edge(chrome_options=options)
7.2 替换user-agent
#实例化配置对象
options = webdriver.ChromeOptions()
#配置对象添加替换UA的命令
options.add_argument('--user-agent=Mozilla/5.0 HAHA')
#实例化带有配置对象的driver对象
driver = webdriver.Edge(chrome_options=options)
7.3 斗鱼网爬取
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
class DouYuSpider(object):
def __init__(self):
self.url='https://www.douyu.com/directory/all'
# self.opt=webdriver.EdgeOptions().add_argument('--headless')
self.driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
def parse_data(self):
time.sleep(10)
#取直播间的列表
room_list=self.driver.find_elements_by_xpath('//*[@id="listAll"]/section[2]/div[2]/ul/li/div')
print(len(room_list))
data_list=[]#存放所有数据的列表
#遍历room_list抓取每个直播间的数据
for r in room_list:
temp={}
temp['title']=r.find_element_by_xpath('./a/div[2]/div[1]/h3').text
temp['type']=r.find_element_by_xpath('./a/div[2]/div[1]/span').text
temp['owner']=r.find_element_by_xpath('./a/div[2]/div[2]/h2/div').text
temp['num']=r.find_element_by_xpath('./a/div[2]/div[2]/span').text
#这里有问题,使用下面注释的无法抓取
temp['image']=self.driver.find_element_by_xpath('//*[@id="listAll"]/section[2]/div[2]/ul/li/div/a/div[1]/div[1]/picture/img').get_attribute('src')
# temp['image'] = r.find_element_by_xpath('./a/div[1]/div[1]/picture/img').get_attribute('src')
data_list.append(temp)
return data_list,len(room_list)
def save_data(self,data_list):
for data in data_list:
print(data)
def main(self):
# 页数
number=0
self.driver.get(self.url)
while True:
data_list,num=self.parse_data()
self.save_data(data_list)
if num<120:
break
try:
self.driver.execute_script('scrollTo(0,1000000)')
# el_text=self.driver.find_element_by_xpath('//*[@id="listAll"]/section[2]/div[2]/div/ul/li[9]/span')
#也可以这样写
el_text=self.driver.find_element(by=By.XPATH,value='//*[contains(text(),"下一页")]')
el_text.click()
number+=1
print(f'第{number}页')
except Exception as e:
print(e)
break
self.driver.quit()
if __name__ == '__main__':
spider=DouYuSpider()
spider.main()

八. 无界面模式
使用selenium会调用浏览器进行运行,如果不想让浏览器吊出来,可加入以下配置
实例化配置对象
options = webdriver.EdgeOptions()
配置对象添加开启无界面模式的命令
options.add_argument("--headless")
一般一个就够了
配置对象添加禁用gpu的命令
options.add_argument("--disable-gpu")
实例化带有配置对象的driver对象
driver = webdriver.Edge(options=options)
注意:macos中chrome浏览器59+版本,Linux中57+版本才能使用无界面模式!
selenium在爬虫中的使用的更多相关文章
- selenium在爬虫中的应用之动态数据爬取
一.selenium概念 selenium 是一个基于浏览器自动化的模块 selenium爬虫之间的关联: 1.便捷的获取动态加载的数据 2.实现模拟登录 基本使用 pip install selen ...
- 爬虫开发12.selenium在scrapy中的应用
selenium在scrapy中的应用阅读量: 370 1 引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝 ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- selenium在scrapy中的使用、UA池、IP池的构建
selenium在scrapy中的使用流程 重写爬虫文件的构造方法__init__,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次). 重写爬虫文件的closed ...
- selenium+python爬虫环境搭建
前言: 准备使用selenium爬取网站数据,先搭建selenium+python爬虫环境搭建 系统环境: 64位win10系统,同时装python2.7和python3.6两个版本,IDE为pych ...
- selenium在scrapy中的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- selenium在爬虫领域的初涉(自动打开网站爬取信息)
selenium简介 Selenium 是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.这个工具的主要功能包括:测试与浏览器的兼容性--测试你的应 ...
- selenium自动化爬虫测试
import time from selenium import webdriver from lxml import etree from selenium.webdriver import Act ...
- Selenium python爬虫
Selenium + Python3 爬虫 准备工作 Chrome驱动下载地址(可正常访问并下载),根据自己chrome的版本下载 Chrome版本 下载地址 78 https://chromedri ...
随机推荐
- mysql加强(4)~多表查询
mysql加强(4)~多表查询:笛卡尔积.消除笛卡尔积操作(等值.非等值连接),内连接(隐式连接.显示连接).外连接.自连接 一.笛卡尔积 1.什么是笛卡尔积: 数学上,有两个集合A={a,b},B= ...
- PyTorch 介绍 | TRANSFORMS
数据并不总是满足机器学习算法所需的格式.我们使用transform对数据进行一些操作,使得其能适用于训练. 所有的TorchVision数据集都有两个参数,用以接受包含transform逻辑的可调用项 ...
- WinDbg 分析dump
1.生成dump文件. 在代码捕获异常,并将异常写入dump文件. #include "stdafx.h" #include <Windows.h> #include ...
- NOI Online 2021 入门组 T1
Description 题目描述 Alice.Bob 和 Cindy 三个好朋友得到了一个圆形蛋糕,他们打算分享这个蛋糕. 三个人的需求量分别为 \(a, b, c\),现在请你帮他们切蛋糕,规则如下 ...
- [POI2010]TEL-Teleportation
因为题目中要求 \(1 \sim 2\) 的最短路只有 \(5\),于是我们可以考虑直接使用人脑将图分层. 那么我们怎么定义每层的点呢?因为要使 \(1 \sim 2\) 的最短路只有 \(5\),我 ...
- 解决No artifacts
前言:maven管理项目时显示No artifacts 错误: 第一步:找到Artifacts 第二步:点击添加 第三步:点击exploded,然后点击应用即可 注意: 名字1和名字2一定要相同 最后 ...
- MySQL数据类型的最优选择
MySQL数据类型的最优选择 慎重选择数据类型很重要.为啥哩?可以提高性能.原理如下: ● 存储(内存.磁盘).从而节省I/O(检索相同数据情况下) ● 计算.进而 ...
- Static块和类加载顺序
原创:转载需注明原创地址 https://www.cnblogs.com/fanerwei222/p/11451040.html 版本:Java8 直接上代码: public class Stati ...
- JS IndexOf移除符合规则的一项
RemoveItem: function (val) { var index = selectedUsers.indexOf(val); if (index > -1) { selectedUs ...
- 关于Java多线程-interrupt()、interrupted()、isInterrupted()解释
多线程先明白一个术语"中断状态",中断状态为true,线程中断. interrupt():就是通知中止线程的,使"中断状态"为true. isInterrupt ...