Python爬虫(二)——发送请求
1. requests库介绍
在python中有许多支持发送的库。比如:urlib、requests、selenium、aiohttp……等。但我们当前最常用的还是requests库,这个库是基于urllib写的,语法非常简单,操作起来十分方便。下面我们就直接进入主题,简单介绍一下如何使用requests库。
2. requests安装及使用
2.1 安装
使用简单易操作的pip的安装方式就可以了:
pip install requests
2.2 发送请求
下面先列举一个最简单的get请求:
import requests
response = requests.get(url='http://zx529.xyz') # 最基本的GET请求
print(response.text) #打印返回的html文档
通过上面这段代码我们就可以初步获得想要请求的网站的网页源代码了。但是大多数情况都会存在着一些反爬手段,这时候我们就需要对requests中的参数进行一些添加,比如Headers、cookies、refer……等。对于大部分网站,通过添加所需要的请求参数就能够对网站发送请求,并得到期望的响应。对于常见的请求,使用requests都可以得到解决,比如:
requests.get('https://github.com/timeline.json') #GET请求
requests.post('http://httpbin.org/post') #POST请求
requests.put('http://httpbin.org/put') #PUT请求
requests.delete('http://httpbin.org/delete') #DELETE请求
requests.head('http://httpbin.org/get') #HEAD请求
requests.options('http://httpbin.org/get') #OPTIONS请求
而请求类型我们也可以在控制面板中进行查看,按下 f12 或者鼠标右击检查,随便打开一个数据包就可以查看该数据包的请求方式,如果没有数据包的话刷新一下页面就可以了。
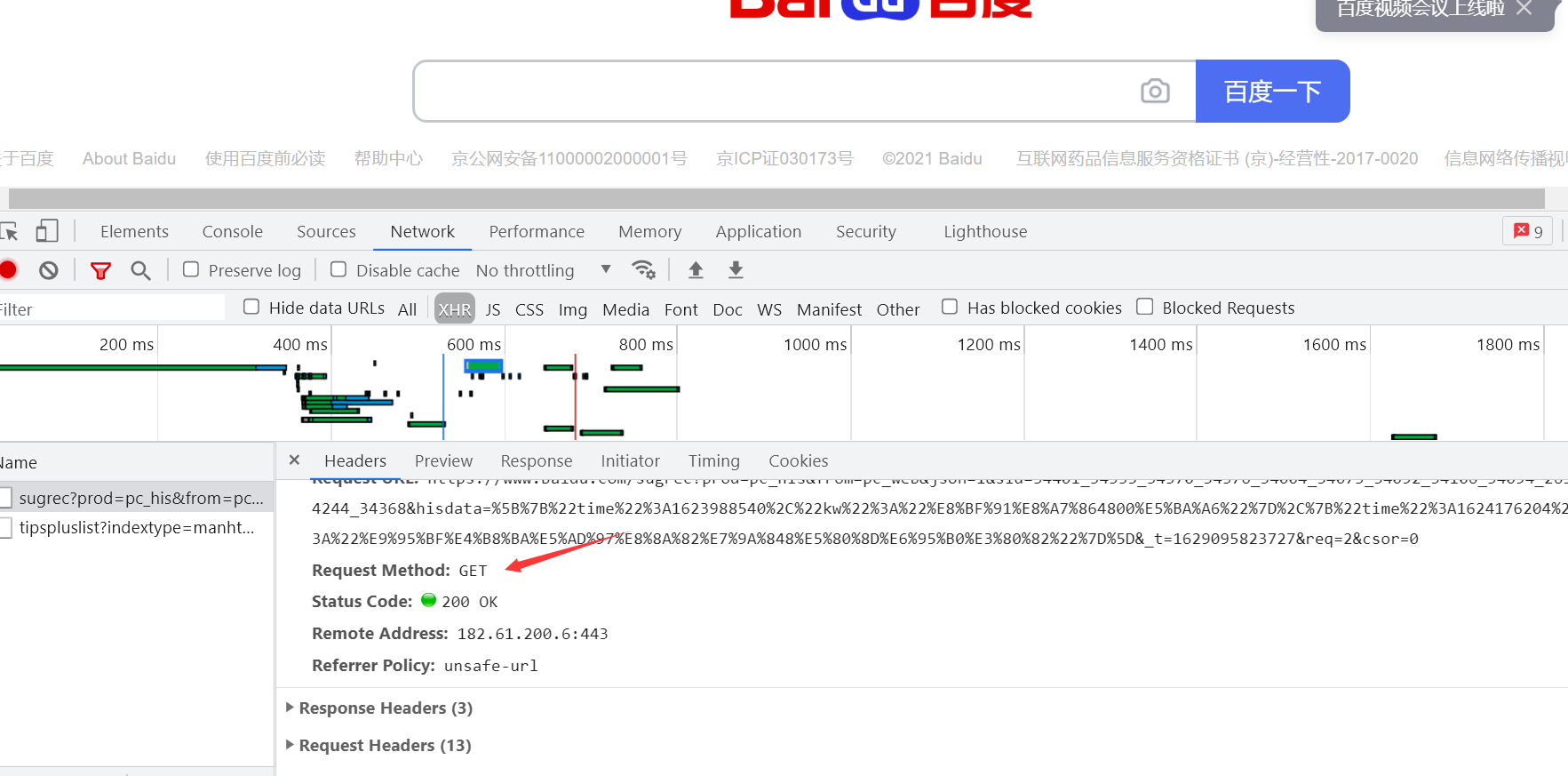
这就是最简单的发送get请求,也就是当要请求的网站没有任何的反扒手段时,只需要在get方法内添加url地址就可以了。但是许多网站存在着一些简单的反爬,就需要添加一些相应的参数。下面列举一些请求的参数:
method :请求方法get posturl:请求网址
params: (可选的)查询参数
headers:(可选的)字典请求头
cookies:(可选的)字典.cookiejar对象,用户身份信息proxies: (可选的) ip代理
data:(可选的)字典.列表.元组.bytespost请求时会用到json:(可选的)字典提交参数
verify:(可选的)是否验证证书,ca证书
timeout:(可选的)设置响应时间,一旦超过,程序会报错
a7low_redirects:(可选的)是否允许重定向,布尔类型数据
以上的参数按照出现的频率排序,当我们对网站进行请求时如果不能够正确出现预期的响应时就可以添加这些参数,最常用的是Headers、refer、cookies。一般情况下如果不用添加cookies就可以的话尽量不要添加cookies,因为cookies可能包含着我们的个人数据。
2.3 个人经验
我总结一下我个人进行爬虫的一些准备。
- 先查看所要获取的数据是否在网页源代码中,如果在网页源代码中,那只要获得网页源代码,那我们直接获取网页源代码就可以了;如果不在网页源代码中,我们就要打开控制面板,对数据包进行抓取,从数据包中获取数据。根据我个人经验,如果网页是一个静态网页,而且想要获得的数据很少发生变化,那么所要获得的数据很大可能就在网页源代码中,比如一些常见的图片网站等;如果想要请求的数据会经常更新,那么数据很有可能是以数据包的形式发送过来的,比如我们一些新闻网、天气网站等。当然这只是大部分情况,具体的情况还要具体分析。再下一步就是确定它的请求方式,以便于我们请求的发送。
- 发送请求之后,具体数据以控制台打印的为准,因为控制台打印的才是我们能够直接进行操作的。而网页有一些结构在经过前端的各种渲染之后就与我们所获得的网页源代码有一定的出入,因此在进行数据筛选之前都以我们控制台获取到的数据为准。
- 请求参数方面如果不能获取到就尝试添加一些参数。先添加headers,refer,如果实在不行再添加cookies。对于get请求,url中的请求参数我们还可以以字典的形式放到params对应的参数中。而对于post请求,对应的请求数据则会以字典的形式放到data参数中。
下面我们对飞卢小说网站的内容进行获取,网页地址:
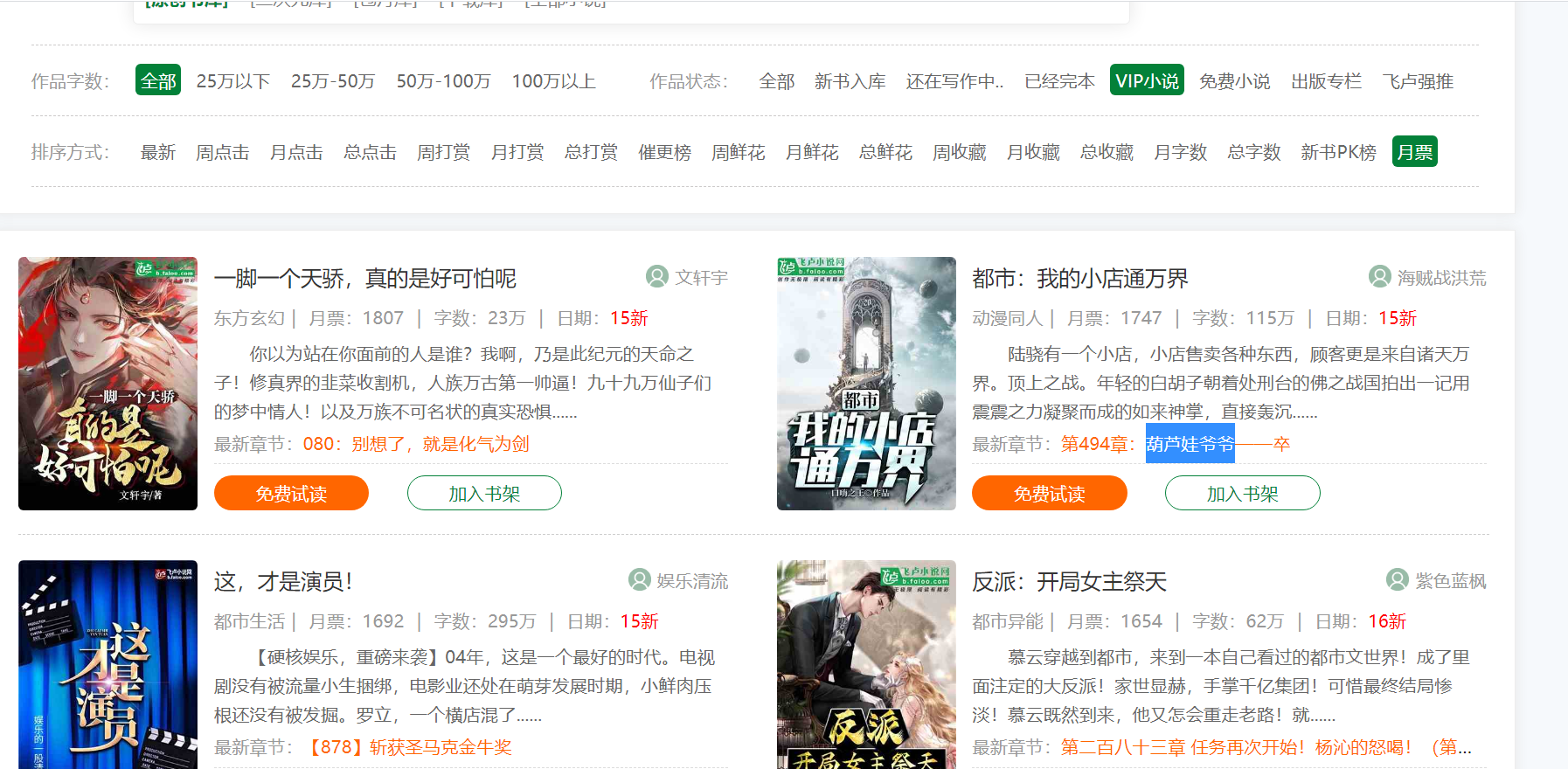
import requests
url='https://b.faloo.com/y_0_0_0_0_3_15_1.html'
response=requests.get(url).text
print(response)
通过控制台打印的内容,此时我们可以复制一段网页中的内容,然后到控制台中按下 Ctrl+F 进行查找,比如我复制了一本小说的名字,在控制台可以获取到,那么就说明我们获取到了期望的内容。
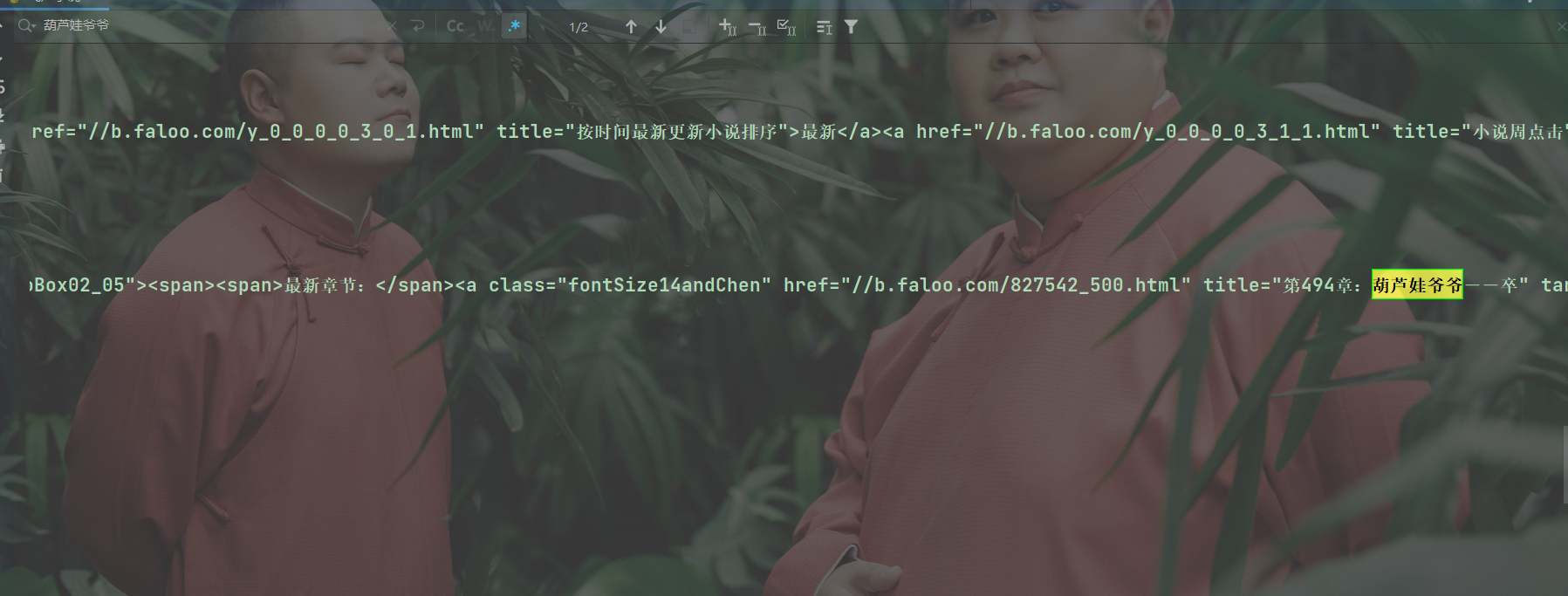
可以获取到相关的内容,说明数据已经被我们获取到了,下一次会给大家整理数据筛选相关的知识。关于requests库的相关知识大家可以参考相关文档:
中文文档: http://docs.python-requests.org/zh CN/latest/index.html
github地址: https://github.com/requests/requests
Python爬虫(二)——发送请求的更多相关文章
- Python爬虫--- 1.1请求库的安装与使用
来说先说爬虫的原理:爬虫本质上是模拟人浏览信息的过程,只不过他通过计算机来达到快速抓取筛选信息的目的所以我们想要写一个爬虫,最基本的就是要将我们需要抓取信息的网页原原本本的抓取下来.这个时候就要用到请 ...
- Python 爬虫二 requests模块
requests模块 Requests模块 get方法请求 整体演示一下: import requests response = requests.get("https://www.baid ...
- Python爬虫二
常见的反爬手段和解决思路 1)明确反反爬的主要思路 反反爬的主要思路就是尽可能的去模拟浏览器,浏览器在如何操作,代码中就如何去实现;浏览器先请求了地址url1,保留了cookie在本地,之后请求地址u ...
- Python使用requests发送请求
Python使用第三方包requests发送请求,实现接口自动化 发送请求分三步: 1.组装请求:包括请求地址.请求头header.cookies.请求数据等 2.发送请求,获取响应:支持get.po ...
- python爬虫(二)_HTTP的请求和响应
HTTP和HTTPS HTTP(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收HTML页面的方法 HTTPS(HyperText Transfer Prot ...
- Python爬虫requests判断请求超时并重新发送请求
下面是简单的一个重复请求过程,更高级更简单的请移步本博客: https://www.cnblogs.com/fanjp666888/p/9796943.html 在爬虫的执行当中,总会遇到请求连接 ...
- Python爬虫(二十一)_Selenium与PhantomJS
本章将介绍使用Selenium和PhantomJS两种工具用来加载动态数据,更多内容请参考:Python学习指南 Selenium Selenium是一个Web的自动化测试工具,最初是为网站自动化测试 ...
- Python 爬虫(二十五) Cookie的处理--cookielib库的使用
Python中cookielib库(python3中为http.cookiejar)为存储和管理cookie提供客户端支持. 该模块主要功能是提供可存储cookie的对象.使用此模块捕获cookie并 ...
- (转)python爬虫:http请求头部(header)详解
本文根据RFC2616(HTTP/1.1规范),参考 http://www.w3.org/Protocols/rfc2068/rfc2068 http://www.w3.org/Protocols/r ...
- Python 爬虫 (二)
cookiejar模块: 管理储存cookie,将传出的http请求添加cookie cookie存储在内存中,CookieJar示例回收后cookie将自动消失 实例:用cookjar访问人人网主页 ...
随机推荐
- RSTP_PA协商过程
P/A协商的基本需求: P:①DP端口,②discarding A:①P2P链路 所有交换机的stp mode改为rstp,确保sw2的g0/0/3为AP,sw3的g0/0/3为DP 把sw3的g0/ ...
- QT. 学习之路 二
Qt 的信号槽机制并不仅仅是使用系统提供的那部分,还会允许我们自己设计自己的信号和槽. 举报纸和订阅者的例子:有一个报纸类 Newspaper,有一个订阅者类 Subscriber.Subscribe ...
- Linux磁盘管理与文件系统
文章目录一.硬盘结构二.MBR与磁盘分区表示三.磁盘分区结构四.文件系统类型●1.XFS文件系统●2.SWAP,交换文件系统●3.Linux支持的其他文件系统类型五.命令部分--检测并确认新硬盘●1. ...
- C语言:数的保存 原码 反码 补码
a=6 a=-18 a 的原码就是0000 0000 0000 0110 1000 0000 0001 0010 ...
- 数据库里的回车字符导致取过来的json字符串不规范的问题
转发:https://bbs.csdn.net/topics/380192638 你可以报保存数据库之前,进行 替换 str = str.Replace("\r\n"," ...
- python基础之while语句操作
# i = 0# while (i < 9):# print("i ----> ",i)# i = i + 1# print(i,"i即将大于或者等于9,wh ...
- Appium -- adb monkey操作(一)
1.Monkey简介在Android的官方自动化测试领域有一只非常著名的"猴子"叫Monkey,这只"猴子"一旦启动,就会让被测的Android应用程序像猴子一 ...
- PL SQL Developer 13连接Oracle数据库并导出数据
下载 并安装 PL SQL Developer 13,默认支持中文语言 ============================= 注册码: product code: 4vkjwhfeh3ufnqn ...
- Python基础之tabview
以前写过界面,但是没有记录下来,以至于现在得从头学习一次,论做好笔记的重要性. 现在学习的是怎么写一个tabview出来,也就是用tkinter做一个界面切换的效果.参考链接:https://blog ...
- (Ooencv3)颜色空间转换
(Ooencv3)颜色空间转换 opencv中有多种色彩空间,包括 RGB.HSI.HSL.HSV.HSB.YCrCb.CIE XYZ.CIE Lab8种,使用中经常要遇到色彩空间的转化,以便生成ma ...