Python爬虫(二)——发送请求
1. requests库介绍
在python中有许多支持发送的库。比如:urlib、requests、selenium、aiohttp……等。但我们当前最常用的还是requests库,这个库是基于urllib写的,语法非常简单,操作起来十分方便。下面我们就直接进入主题,简单介绍一下如何使用requests库。
2. requests安装及使用
2.1 安装
使用简单易操作的pip的安装方式就可以了:
pip install requests
2.2 发送请求
下面先列举一个最简单的get请求:
import requests
response = requests.get(url='http://zx529.xyz') # 最基本的GET请求
print(response.text) #打印返回的html文档
通过上面这段代码我们就可以初步获得想要请求的网站的网页源代码了。但是大多数情况都会存在着一些反爬手段,这时候我们就需要对requests中的参数进行一些添加,比如Headers、cookies、refer……等。对于大部分网站,通过添加所需要的请求参数就能够对网站发送请求,并得到期望的响应。对于常见的请求,使用requests都可以得到解决,比如:
requests.get('https://github.com/timeline.json') #GET请求
requests.post('http://httpbin.org/post') #POST请求
requests.put('http://httpbin.org/put') #PUT请求
requests.delete('http://httpbin.org/delete') #DELETE请求
requests.head('http://httpbin.org/get') #HEAD请求
requests.options('http://httpbin.org/get') #OPTIONS请求
而请求类型我们也可以在控制面板中进行查看,按下 f12 或者鼠标右击检查,随便打开一个数据包就可以查看该数据包的请求方式,如果没有数据包的话刷新一下页面就可以了。
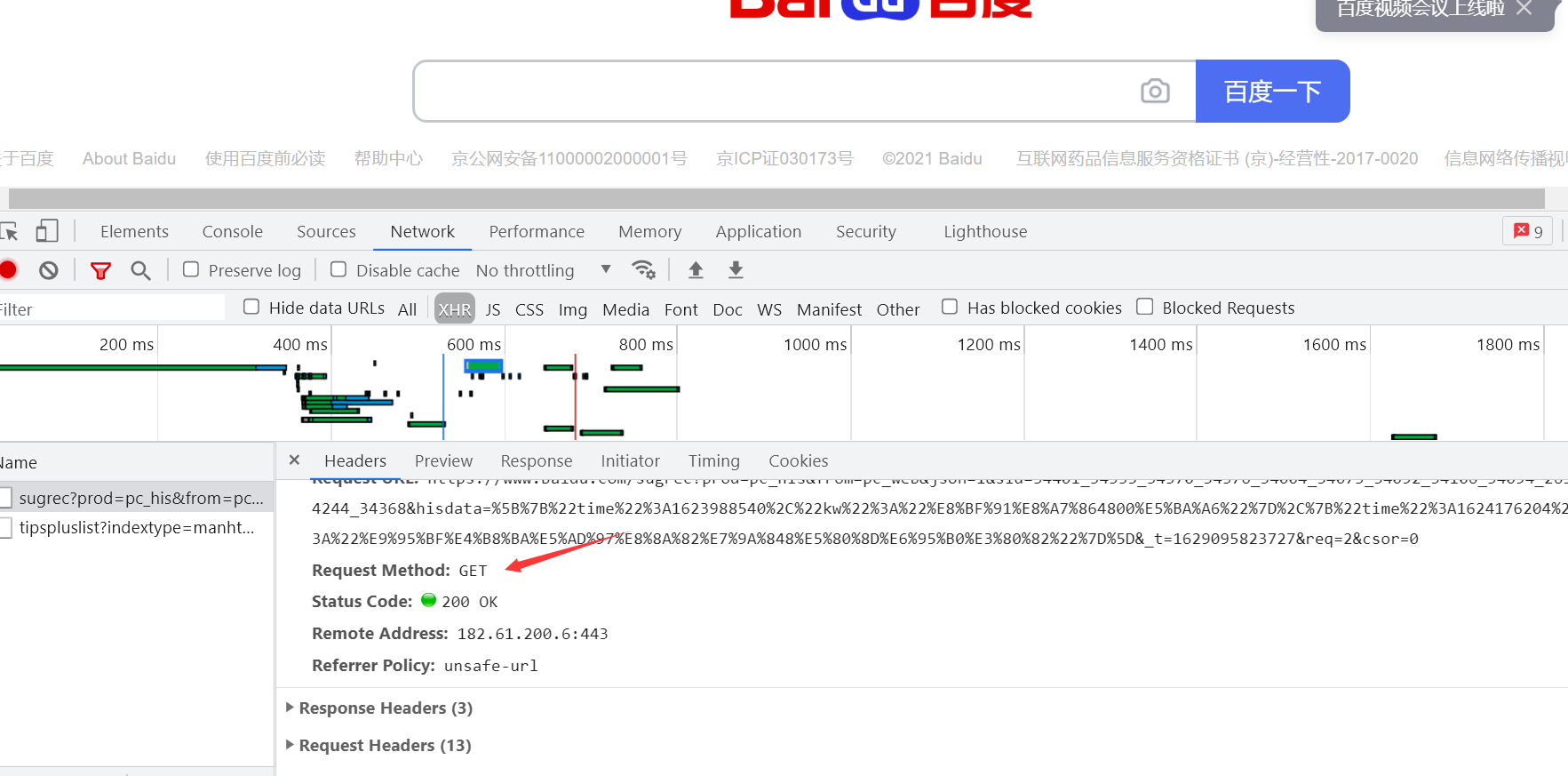
这就是最简单的发送get请求,也就是当要请求的网站没有任何的反扒手段时,只需要在get方法内添加url地址就可以了。但是许多网站存在着一些简单的反爬,就需要添加一些相应的参数。下面列举一些请求的参数:
method :请求方法get posturl:请求网址
params: (可选的)查询参数
headers:(可选的)字典请求头
cookies:(可选的)字典.cookiejar对象,用户身份信息proxies: (可选的) ip代理
data:(可选的)字典.列表.元组.bytespost请求时会用到json:(可选的)字典提交参数
verify:(可选的)是否验证证书,ca证书
timeout:(可选的)设置响应时间,一旦超过,程序会报错
a7low_redirects:(可选的)是否允许重定向,布尔类型数据
以上的参数按照出现的频率排序,当我们对网站进行请求时如果不能够正确出现预期的响应时就可以添加这些参数,最常用的是Headers、refer、cookies。一般情况下如果不用添加cookies就可以的话尽量不要添加cookies,因为cookies可能包含着我们的个人数据。
2.3 个人经验
我总结一下我个人进行爬虫的一些准备。
- 先查看所要获取的数据是否在网页源代码中,如果在网页源代码中,那只要获得网页源代码,那我们直接获取网页源代码就可以了;如果不在网页源代码中,我们就要打开控制面板,对数据包进行抓取,从数据包中获取数据。根据我个人经验,如果网页是一个静态网页,而且想要获得的数据很少发生变化,那么所要获得的数据很大可能就在网页源代码中,比如一些常见的图片网站等;如果想要请求的数据会经常更新,那么数据很有可能是以数据包的形式发送过来的,比如我们一些新闻网、天气网站等。当然这只是大部分情况,具体的情况还要具体分析。再下一步就是确定它的请求方式,以便于我们请求的发送。
- 发送请求之后,具体数据以控制台打印的为准,因为控制台打印的才是我们能够直接进行操作的。而网页有一些结构在经过前端的各种渲染之后就与我们所获得的网页源代码有一定的出入,因此在进行数据筛选之前都以我们控制台获取到的数据为准。
- 请求参数方面如果不能获取到就尝试添加一些参数。先添加headers,refer,如果实在不行再添加cookies。对于get请求,url中的请求参数我们还可以以字典的形式放到params对应的参数中。而对于post请求,对应的请求数据则会以字典的形式放到data参数中。
下面我们对飞卢小说网站的内容进行获取,网页地址:
import requests
url='https://b.faloo.com/y_0_0_0_0_3_15_1.html'
response=requests.get(url).text
print(response)
通过控制台打印的内容,此时我们可以复制一段网页中的内容,然后到控制台中按下 Ctrl+F 进行查找,比如我复制了一本小说的名字,在控制台可以获取到,那么就说明我们获取到了期望的内容。
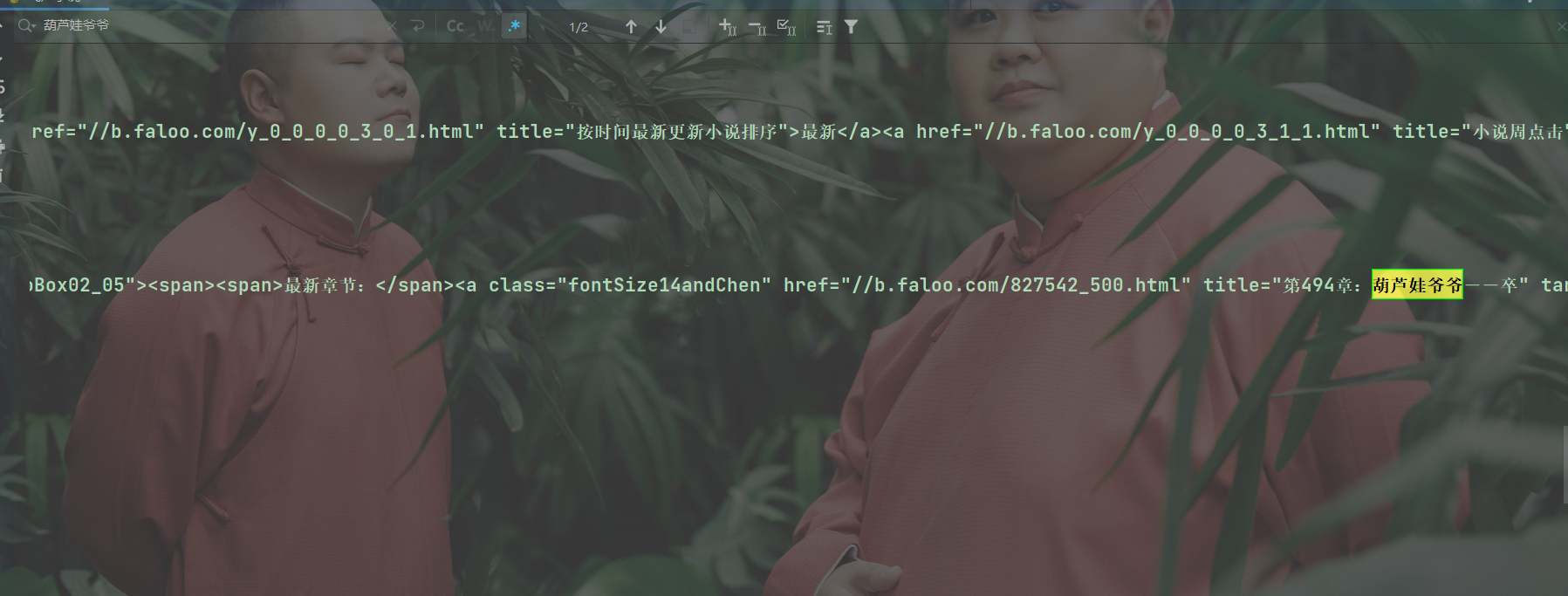
可以获取到相关的内容,说明数据已经被我们获取到了,下一次会给大家整理数据筛选相关的知识。关于requests库的相关知识大家可以参考相关文档:
中文文档: http://docs.python-requests.org/zh CN/latest/index.html
github地址: https://github.com/requests/requests
Python爬虫(二)——发送请求的更多相关文章
- Python爬虫--- 1.1请求库的安装与使用
来说先说爬虫的原理:爬虫本质上是模拟人浏览信息的过程,只不过他通过计算机来达到快速抓取筛选信息的目的所以我们想要写一个爬虫,最基本的就是要将我们需要抓取信息的网页原原本本的抓取下来.这个时候就要用到请 ...
- Python 爬虫二 requests模块
requests模块 Requests模块 get方法请求 整体演示一下: import requests response = requests.get("https://www.baid ...
- Python爬虫二
常见的反爬手段和解决思路 1)明确反反爬的主要思路 反反爬的主要思路就是尽可能的去模拟浏览器,浏览器在如何操作,代码中就如何去实现;浏览器先请求了地址url1,保留了cookie在本地,之后请求地址u ...
- Python使用requests发送请求
Python使用第三方包requests发送请求,实现接口自动化 发送请求分三步: 1.组装请求:包括请求地址.请求头header.cookies.请求数据等 2.发送请求,获取响应:支持get.po ...
- python爬虫(二)_HTTP的请求和响应
HTTP和HTTPS HTTP(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收HTML页面的方法 HTTPS(HyperText Transfer Prot ...
- Python爬虫requests判断请求超时并重新发送请求
下面是简单的一个重复请求过程,更高级更简单的请移步本博客: https://www.cnblogs.com/fanjp666888/p/9796943.html 在爬虫的执行当中,总会遇到请求连接 ...
- Python爬虫(二十一)_Selenium与PhantomJS
本章将介绍使用Selenium和PhantomJS两种工具用来加载动态数据,更多内容请参考:Python学习指南 Selenium Selenium是一个Web的自动化测试工具,最初是为网站自动化测试 ...
- Python 爬虫(二十五) Cookie的处理--cookielib库的使用
Python中cookielib库(python3中为http.cookiejar)为存储和管理cookie提供客户端支持. 该模块主要功能是提供可存储cookie的对象.使用此模块捕获cookie并 ...
- (转)python爬虫:http请求头部(header)详解
本文根据RFC2616(HTTP/1.1规范),参考 http://www.w3.org/Protocols/rfc2068/rfc2068 http://www.w3.org/Protocols/r ...
- Python 爬虫 (二)
cookiejar模块: 管理储存cookie,将传出的http请求添加cookie cookie存储在内存中,CookieJar示例回收后cookie将自动消失 实例:用cookjar访问人人网主页 ...
随机推荐
- 「CF85E」 Guard Towers
「CF85E」 Guard Towers 模拟赛考了这题的加强版 然后我因为初值问题直接炸飞 题目大意: 给你二维平面上的 \(n\) 个整点,你需要将它们平均分成两组,使得每组内任意两点间的曼哈顿距 ...
- 一文搞懂一致性hash的原理和实现
在 go-zero 的分布式缓存系统分享里,Kevin 重点讲到过一致性hash的原理和分布式缓存中的实践.本文来详细讲讲一致性hash的原理和在 go-zero 中的实现. 以存储为例,在整个微服务 ...
- 微信小程序云开发-云存储-上传文件(图片/视频)到云存储 精简代码
说明 图片/视频这类文件是从客户端会话选择文件. 一.wxml文件添加if切换显示 <!--上传文件到云存储--> <button bindtap="chooseImg&q ...
- 最大网络流dinic
初始化flow(最大流量)为INF(极大值),建边(正向弧和反向弧) bfs寻找增广路看看有没有路,顺便进行深度标号.如果没有路直接结束输出flow. 如果有,我们按照深度dfs.dfs时注意在给正向 ...
- Python自动化测试面试题-Selenium篇
目录 Python自动化测试面试题-经验篇 Python自动化测试面试题-用例设计篇 Python自动化测试面试题-Linux篇 Python自动化测试面试题-MySQL篇 Python自动化测试面试 ...
- document.all("div).style.display = "none"与 等于""的区别
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- SQL SERVER 雨量计累计雨量(小时)的统计思路
PLC中定时读取5分钟雨量值,如何将该值统计为小时雨量作为累计?在sql server group by聚合函数,轻松实现该目的. 1.编写思路 数据库中字段依据datetime每五分钟插入一条语句, ...
- java获取日出日落时间
import java.math.BigDecimal; import java.text.ParseException; import java.text.SimpleDateFormat; imp ...
- 记录一次现网MySQL内存增长超限问题定位过程
问题现象现网物理机内存近几日内爆涨使用率超过了90%,可用内存从250G,降低到20G以下,报告警.服务器使用情况来看,并没有什么异常.除了QPS缓慢增长外. MySQL内存分配结构 定位这个问题,先 ...
- Mysql命令语句
常用的管理命令 SHOW DATABASES; //显示当前服务器下所有的数据库 USE 数据库名称; //进入指定的数据 show tables; ...