Sudoku(第二次作业)
[这里是github](https://github.com/031502243/Sudoku/tree/master/Desktop/shudu)
工具清单:
- 编程语言:C++
- 编程IDE:XCode
- 效能分析工具:XCode
- 源代码管理平台:Github
#PSP2.1
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ————— | ————— |
| · Estimate | · 估计这个任务需要多少时间 | 16h | ————— |
| Development | 开发 | ————— | ————— |
| · Analysis | · 需求分析 (包括学习新技术) | 3h | 2h |
| · Design Spec | · 生成设计文档 | 10min | 10min |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10min | 0min |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10min | 0min |
| · Design | · 具体设计 | 1h | 1h |
| · Coding | · 具体编码 | 5h | 4h |
| · Code Review | · 代码复审 | 3h | 2h |
| · Test | · 测试(自我测试,修改代码,提交修改) | 1h | 2h |
| Reporting | 报告 | ————— | ————— |
| · Test Report | · 测试报告 | 3h | 4h |
| · Size Measurement | · 计算工作量 | 10min | 20min |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10min | 0min |
| 合计 | 16h50min | 15h30min |
关于这个表格我想要说一下..关于生成设计文档、设计复审、代码规范..目前貌似好像是用不到,希望学长老师可以在这里指点一下。
解题思路
一开始看到这个作业的题目,首先想到的当然是数独的实现。第一秒在我脑海中想到的是,八十一个格子,每个格子随机填一个数,然后判断行是否冲突,列是否冲突,所属的9*9格子中的数字是否冲突,如果不冲突就填上这个数字,如果冲突了就重新随机一个数字填。
但是这个方法有几个问题:
- 1.实现有问题。填最后一个格子(第九行第九列)的时候,本应只有一个数字可以填,但是如果这个数字发生冲突,就会出现死循环,永远得不到答案。
- 2.性能太差,单看第一行,每次填数字的时候都是随机的数字,不能判断之前填过的数字,假设前八个格子填过了12345678,填最后一个格子的时候,一直随机不到9,就会浪费太多的时间。第一行就会出现这样的问题,可想而知填完整个数独会浪费多少时间。
于是我开始百思不得其解,上网百度了别人实现数独的方法,发现了一个很神奇的方法--回溯法。
那么回溯法是什么呢?正如之前举过的例子,填最后一个格子(第九行第九列)的时候,如果没有数字可以填,就返回上一步(第九行第八列),重新填上一个格子,如果还是无法实现最终结果,那就再退一步,重新填第九行第七列的格子,以此类推。这样就总是能得出最终解。
那么可以实现了以后,暴力随机数字的方法当然是不可取了,看到网上很多人都是先把第一列填好,再填第二列、第三列,每填一个数字都判断一下行冲突,列冲突,格冲突。那么有没有方法能少一次判断呢?于是想到了可以先把每一行的1填了,再填每一行的2...以此类推。这样肯定没有行冲突,只需要判断列冲突和格冲突就可以了。那么数字填进去的规则是什么呢?如果每次都指定一行的同一个位置,那么数独的个数就大大减少,不如每次填数字都填入一行中的随机的位置,这样就可以解决刚刚的问题了。取随机数的方法,使用的是srand() rand()。[这里是使用方法。](http://blog.csdn.net/zqy2000zqy/article/details/1174978)
设计实现
- 没有用到类。
- 整个数独用数组实现,所以需要一个初始化数组的函数,并且将数组sudoku[0][0]初始化为题目要求。
- 需要一个判断填数的时候是否会出现冲突的judge()函数。布尔类型函数,如果填数成功,则返回true,若填数失败,即数字冲突,则返回false。
- 回溯函数reset(),如果填数失败,则应该回溯。
- 填数字的函数set()。布尔类型,放置在while循环中。
- 将结果打印出来的函数printSudoku()。
以下是相关函数的流程图(第一次做这个不知道做的对不对)。

代码说明
- 头文件
#include<iostream>
#include<ctime>
#include<fstream>
#define N (4+3)%9+1
- 初始化数组函数--initSudoku()
void initSudoku(){
for(int i = 0 ; i < 9 ; i++){
for (int j = 0 ; j < 9 ; j++){
sudoku[i][j] = 0;
}
}
sudoku[0][0] = N ;//将sudoku[0][0]设置为题目要求
}
- 判断冲突函数--judge()
bool Judge(int x, int y, int val)
{
if(sudoku[y][x] != 0)//非空
return false;
int x0, y0;
// for(x0 = 0;x0<9;x0++)
// {
// if (sudo[y][x0] == val)//行冲突
// return false;
// }
for (y0 = 0; y0<9; y0++)
{
if (sudoku[y0][x] == val)//列冲突
return false;
}
for(y0 = y / 3 * 3 ; y0<y / 3 * 3 + 3 ; y0++)
{
for(x0 = x / 3 * 3 ; x0 < x / 3 * 3 + 3 ; x0++)
{
if(sudoku[y0][x0] == val)//格冲突
return false;
}
}
sudoku[y][x] = val;
return true;
}
- 回溯函数--reset()
void reset(int x, int y)
{
sudoku[y][x] = 0;
}
- 填数函数--set()
bool set(int y, int val)
{
int xOrd[9] ;
int i, k, tmp;
for(i=0;i<9;i++)
{
xOrd[i] = i;
}
for(i = 0;i<9;i++) //生成当前行的扫描序列,实现随机填入位置
{
k = rand() % 9;
tmp = xOrd[k];
xOrd[k] = xOrd[i];
xOrd[i] = tmp;
}
for (int i = 0 ; i < 9 ; i++)
{
int x = xOrd[i];
if (val == N && x == 0 && y == 0)//判断是不是第一行第一列的位置
{
if(set(y + 1,val))//下一行继续填当前数
return true;
}
if (Judge(x, y, val))
{
if (y == 8)//最后一行
{
if (val == 9 || set(0, val + 1))
return true;
}
else
{
if(set(y + 1,val))//下一行继续填当前数
return true;
}
reset(x, y);//回溯
}
}
return false;
}
- 将结果打印出来的函数printSudoku()。
void printSudoku()
{
for (int y = 0;y<9;y++)
{
for(int x = 0;x<9;x++)
{
// cout<< sudoku[y][x] << " ";
fout<< sudoku[y][x] << " ";
}
// cout<< endl;
fout<< endl;
}
// cout << endl;
fout << endl;
}
- main()
int main(int argc, char* argv[])
{
srand((unsigned)time(NULL));
fout.open("sudoku.txt");
int n ;
while (!(cin >> n)) {
cin.clear();
// reset input
while (cin.get() != '\n')
continue;
// get rid of bad input
cout << "Please enter a number: ";
}
while(n--){
initSudoku(); //每次循环都要初始化数独数组
while (!set(0, 1));
printSudoku();
// cout << endl;
}
fout.close();
// cout<< "1";
return 0;
}
程序运行
运行过程中
n = 2的运行结果

#性能分析
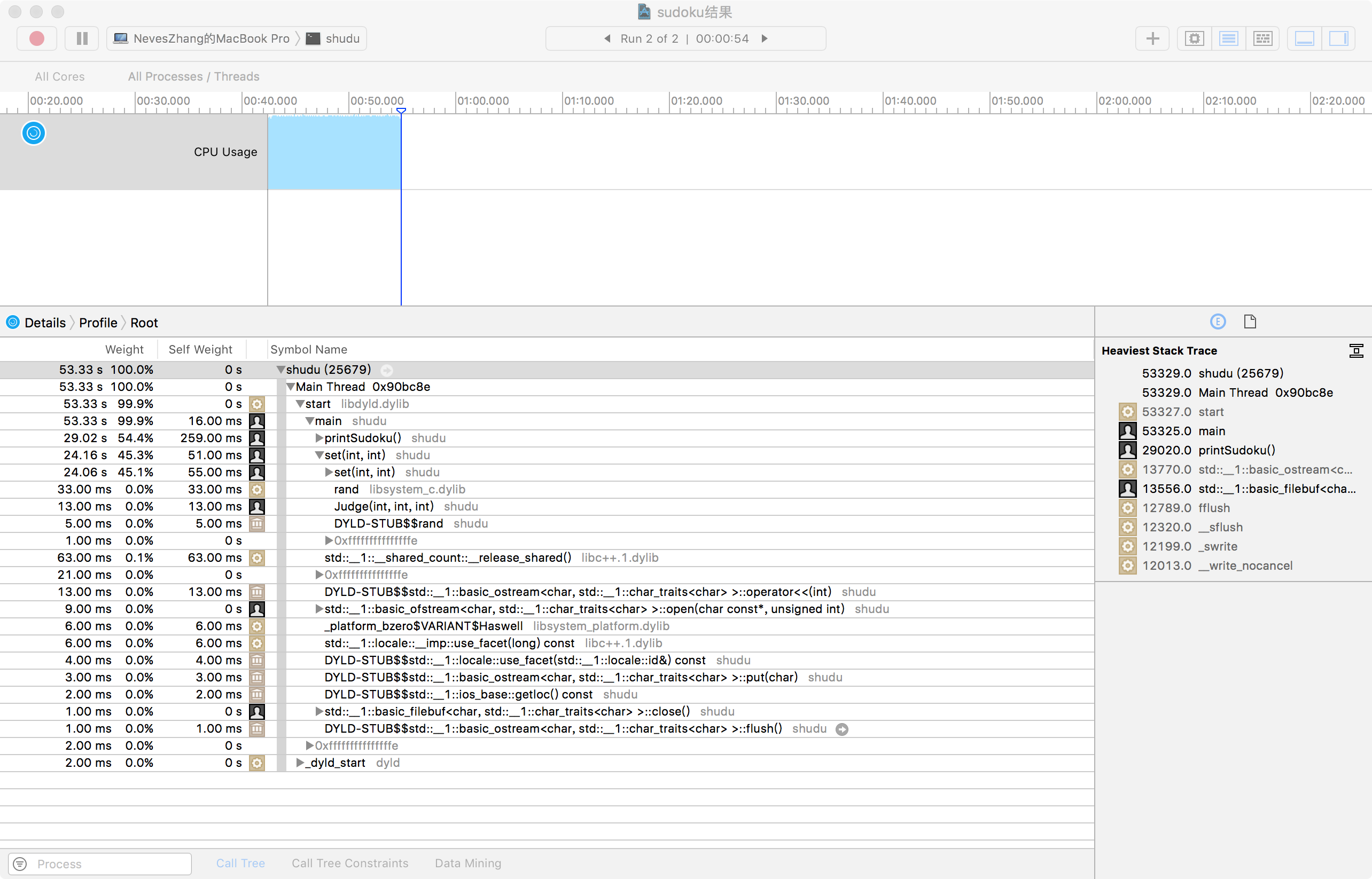
运行了1000000个数据最后用时53.33s。令我没想到的是,花时间最多的一个函数是打印函数,占总时间的54.4%,花了29秒钟。思考了许久,认为如果可以一行一行,每一行从左往右的填数字,就可以直接输出,会节省很多时间,但是这就有违我一开始的设计思路,会多一次行冲突判断的。希望老师与学长可以指出来如何能改进我的输出函数。剩下的大部分时间都是set函数,占总时间的45.3%,和我预期一样,这个函数耗时很长,因为里面有包含循环的judge函数。rand函数耗时是set函数中最多的,这一点我比较意外。
改进思路在解题思路的部分已经说明了,解题思路就是已经改进了本来的想法,减少了一重循环-判断行冲突。对于减少set函数时长目前还没有很好的想法,希望之后在浏览同学的博客的时候能有所启发。也希望老师与学长多提一些建议。最终拿来测试的程序没有输出在控制台,也减少了一些时间。
关于github的使用
github mac 使用
git push报错error: failed to push some refs to 'git@github.com:
PS:老师能不能想个办法,测试环境不要在windows下...因为班上还是有一部分同学用的不是windows环境..所以就得一直麻烦其他同学生成exe文件,自己电脑上也不能尝试..不知道有木有成功oo
Sudoku(第二次作业)的更多相关文章
- 第二次作业——个人项目实战(sudoku)
第二次作业--个人项目实战(sudoku) 一.作业要求地址 第二次作业--个人项目实战 二.Github项目地址 softengineering1--sudoku 三.PSP表格估计耗时 PSP2. ...
- 耿丹CS16-2班第二次作业汇总
-- Deadline: 2016-09-28 12:00 -- 作业内容:http://www.cnblogs.com/huangjunlian/p/5891726.html -- 第二次作业总结: ...
- JAVA第二次作业展示与学习心得
JAVA第二次作业展示与学习心得 在这一次作业中,我学习了复选框,密码框两种新的组件,并通过一个邮箱登录界面将两种组件运用了起来.具体的使用方法和其他得组件并没有什么大的不同. 另外我通过查阅资料使用 ...
- 20169212《Linux内核原理与分析》第二周作业
<Linux内核原理与分析>第二周作业 这一周学习了MOOCLinux内核分析的第一讲,计算机是如何工作的?由于本科对相关知识的不熟悉,所以感觉有的知识理解起来了有一定的难度,不过多查查资 ...
- 软件工程(QLGY2015)第二次作业点评(随机挑选20组点评)
相关博文目录: 第一次作业点评 第二次作业点评 第三次作业点评 说明:随机挑选20组点评,大家可以看看blog名字,github项目名字,看看那种是更好的,可以学习,每个小组都会反应出一些问题,希望能 ...
- 程序设计第二次作业<1>
面向对象程序设计第二次作业<1> Github 链接:https://github.com/Wasdns/object-oriented 题目: <1>第一次尝试 我立马认识到 ...
- homework-02,第二次作业——寻找矩阵最大子序列和
经过漫漫漫~~~~~~~~~~~~~~长的编译和调试,第二次作业终于告一段落了 先放出源码,思路后面慢慢道来 #include<stdio.h> #include<stdlib.h& ...
- 20169210《Linux内核原理与分析》第二周作业
<Linux内核原理与分析>第二周作业 本周作业分为两部分:第一部分为观看学习视频并完成实验楼实验一:第二部分为看<Linux内核设计与实现>1.2.18章并安装配置内核. 第 ...
- SQL 第二章 作业
/*第二章 作业*/ create table S ( sno char(2) NOT NULL UNIQUE, sname char(3), city char(2) ); alter table ...
- 软件工程(GZSD2015)第二次作业小结
第二次作业,从4月7号开始,陆续开始提交作业.根据同学们提交的作业报告,相比第一次作业,已经有了巨大改变,大家开始有了完整的实践,对那些抽象的名词也开始有了直观的感受,这很好.然后有一些普遍存在的问题 ...
随机推荐
- AutoCAD 凸度(bulge)的概念及使用WPF函数画图
前言 凸度(bulge)是AutoCAD 中一个非常重要的概念,凸度控制着两点之间弧度大小,弧度的方向.各种复杂的图像有可能就是成百上千的弧线组成的.从AutoCAD中导出的数据也有该值,一般的形式 ...
- tomcat8 JVM 优化
在Linux环境下设置Tomcat JVM,在/opt/tomcat/bin/catalina.sh文件中找到"# ----- Execute The Requested Command&q ...
- 分布式锁之redisson
redisson是redis官网推荐的java语言实现分布式锁的项目.当然,redisson远不止分布式锁,还包括其他一些分布式结构.详情请移步:https://github.com/mrniko/r ...
- apache log4j打印日志源码出口
Throwable.class: public void printStackTrace(PrintStream s) { synchronized (s) { s.println(this); St ...
- windows下mongodb基础玩法系列二CURD附加一
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
- Apollo 2 如何支持 @Value 注解自动更新
前言 Apollo 在 v0.10.0 版本后,支持自动更新.v0.10.0之前的版本在配置变化后不会重新注入,需要重启才会更新. 也就是说,如果一个属性加入了 @Value 注解,并且这个配置在配置 ...
- APiCloud学习
端API调用 核心模块在 window.api 对象下,默认提供该模块,不需要单独引用. 扩展模块在相应的模块对象下(例如:文件系统模块在fs对象下),需要require引入(var fs = api ...
- .NET实现发送邮件
注意:需要找到“POP3/SMTP服务”并开启,然后生成授权码,生成的授权码就是下面登入的密码. /// <summary> /// 发送邮件 /// </summary> / ...
- 读 《CSharp Coding Guidelines》有感
目录 基本原则 类设计指南 属性成员设计指南 其他设计指南 可维护性指南 命名指南 性能指南 框架指南 文档指南 布局指南 相关链接 C# 编程指南 前不久在 Github 上看见了一位大牛创建一个仓 ...
- vue项目sql图片动态路径引用问题
最近遇到一个vue动态图片路径的引用问题?明明路径是正确的但是却渲染不出图片!先看我慢慢说来!! 1.当我们把图片的路径放置在data(){return:{}}中的数组中的时候,然后通过v-for循环 ...