fcn+caffe+制作自己的数据集
参考博客:
http://blog.csdn.net/jacke121/article/details/78160398
以视网膜血管分割的数据集为例:
训练样本:

训练标签:

标签图的制作依据voc数据集中的样例,将被检测的目标改为voc中的一类。

将用ps软件制作的黑底白色标签转化为,目标为(128,0,0)的单通道彩色图片,存储格式为.png。也就是将待分割的目标当做飞机。
转化png的matlab的代码如下:
imgname='15.jpg';
I=imread(imgname);
I_gray=rgb2gray(I);
I_bw=uint8(im2bw(I_gray))*128;
I1=uint8(zeros(size(I,1),size(I,2),3));
I1(:,:,1)=I_bw;
[x,map]=rgb2ind(I1,256);
imgSaveName=imgname(1:length(imgname)-4);
imwrite(x,map,strcat(imgSaveName,'.png'));

制作好训练集后,修改一些文件中的路径。
我的工程路径:
I:\caffe171101\caffe-master\fcn-master\retina200-fcn32s
I:\caffe171101\caffe-master\fcn-master\data\retina200_200
voc_layers.py修改:
可以删掉底下的class SBDDSegDataLayer(caffe.Layer) 训练的时候用不到。

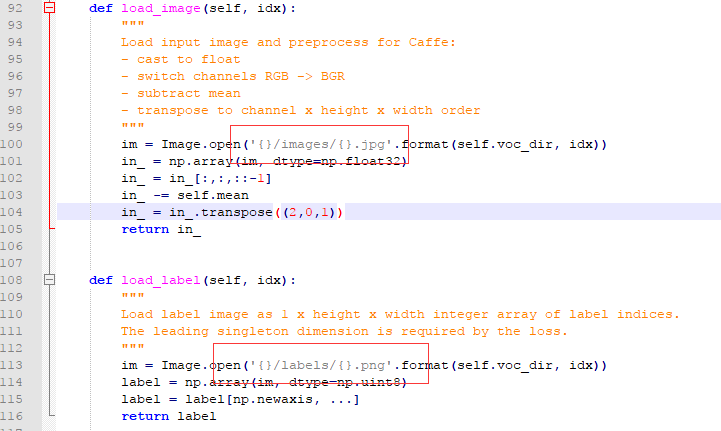
修改这三个地方的路径即可。
train.prototxt修改:

这个mean,就是计算训练样本RGB三通道的平均值。
将后面的num_output:21 全部改为num_output:2 只有背景和待分割的目标两类。
val.prototxt的修改同理。
deploy_voc_32s.prototxt 不变
solver.prototxt 不需要改动
因为是第一次训练,采用fcn32s-heavy-pascal.caffemodel作为预训练模型。
solve.py
import caffe
import surgery, score import numpy as np
import os
import sys try:
import setproctitle
setproctitle.setproctitle(os.path.basename(os.getcwd()))
except:
pass weights = 'fcn32s-heavy-pascal.caffemodel'
deploy_proto = 'deploy_voc_32s.prototxt' # init
caffe.set_device(int(0))
caffe.set_mode_gpu() solver = caffe.SGDSolver('solver.prototxt')
#solver.net.copy_from(weights)
vgg_net=caffe.Net(deploy_proto,weights,caffe.TRAIN)
surgery.transplant(solver.net,vgg_net)
del vgg_net # surgeries
interp_layers = [k for k in solver.net.params.keys() if 'up' in k]
surgery.interp(solver.net, interp_layers) # scoring
val = np.loadtxt('../data/retina200_200/val.txt', dtype=str) for _ in range(50):
solver.step(2000)
score.seg_tests(solver, False, val, layer='score')
必须采用transplant的方式训练。因为这个模型的网络中的图片尺寸和自己的数据集中的图片尺寸不一样。
训练完成之后,进行预测时,这个deploy.prototxt文件需要改动一下。
将其中num_output:21的地方全部改为num_output:21
实验结果:

fcn+caffe+制作自己的数据集的更多相关文章
- fcn+caffe+siftflow实验记录
环境搭建: vs2013,编译caffe工程,cuda8.0,cudnn5.1,python2.7. 还需要安装python的一些包.Numpy+mkl scipy matplotlib sci ...
- 自动化工具制作PASCAL VOC 数据集
自动化工具制作PASCAL VOC 数据集 1. VOC的格式 VOC主要有三个重要的文件夹:Annotations.ImageSets和JPEGImages JPEGImages 文件夹 该文件 ...
- matlab遍历文件制作自己的数据集 .mat文件
原文作者:aircraft 原文地址:https://www.cnblogs.com/DOMLX/p/9115788.html 看到深度学习里面的教学动不动就是拿MNIST数据集,或者是IMGPACK ...
- 仿照CIFAR-10数据集格式,制作自己的数据集
本系列文章由 @yhl_leo 出品,转载请注明出处. 文章链接: http://blog.csdn.net/yhl_leo/article/details/50801226 前一篇博客:C/C++ ...
- SSD-tensorflow-2 制作自己的数据集
VOC2007数据集格式: VOC2007详细介绍在这里,提供给大家有兴趣作了解.而制作自己的数据集只需用到前三个文件夹,所以请事先建好这三个文件夹放入同一文件夹内,同时ImageSets文件夹内包含 ...
- Windows10+YOLOv3实现检测自己的数据集(1)——制作自己的数据集
本文将从以下三个方面介绍如何制作自己的数据集 数据标注 数据扩增 将数据转化为COCO的json格式 参考资料 一.数据标注 在深度学习的目标检测任务中,首先要使用训练集进行模型训练.训练的数据集好坏 ...
- fcn+caffe+voc2012实验记录
参考博客: http://blog.csdn.net/haoji007/article/details/77148374 http://blog.csdn.net/jacke121/article/d ...
- caffe训练自己的数据集
默认caffe已经编译好了,并且编译好了pycaffe 1 数据准备 首先准备训练和测试数据集,这里准备两类数据,分别放在文件夹0和文件夹1中(之所以使用0和1命名数据类别,是因为方便标注数据类别,直 ...
- Mask-RCNN:教你如何制作自己的数据集进行像素级的目标检测
概述 Mask-RCNN,是一个处于像素级别的目标检测手段.目标检测的发展主要历程大概是:RCNN,Fast-RCNN,Fster-RCNN,Darknet,YOLO,YOLOv2,YOLO3(参考目 ...
随机推荐
- CodeForces 570D - Tree Requests - [DFS序+二分]
题目链接:https://codeforces.com/problemset/problem/570/D 题解: 这种题,基本上容易想到DFS序. 然后,我们如果再把所有节点分层存下来,那么显然可以根 ...
- sale.order
# 初始化一个变量用来记录产品类型line_type = ''# 循环明细行for product in self.options: # 拿到该明细行的产品类型 product_type = prod ...
- odoo配置文件内容详解
odoo常用openerp-server.conf配置参数详解 参数 说明 用法 addons_path addons模块的查找路径,多个路径用逗号分隔 addons_path = E:\GreenO ...
- 探究Java中的锁
一.锁的作用和比较 1.Lock接口及其类图 Lock接口:是Java提供的用来控制多个线程访问共享资源的方式. ReentrantLock:Lock的实现类,提供了可重入的加锁语义 ReadWrit ...
- JavaScript 模拟 Dictionary
function Dictionary() { var items = {}; //判断是否包含Key值 this.has = function(key) { return key in items; ...
- 要学的javaee技术
mybatis.hibernate.spirng MVC.freemarker.zookeeper.dubbo.quartz的技术框架:NoSQL技术ehcache.memcached.redis等: ...
- cherry-pick时的add by us / both modified / delete by us /delete by themk
简单来说: us=into , them=from 比如你将test分支的某个提交cherry-pick到master分支上,那么us就是master分支,them 就是test分支 参考: http ...
- generatorConfiguration详解
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE generatorConfiguration ...
- git----------如何创建develop分支和工作流,以及如何将develop上的代码合并到master分支上
1.点击sourceTree 右上角的git工作流,或弹出一个弹出框,无需修改任何东西直接点击确认就可以创建develop. . 2.这里有两个分支了,当前高亮的就是你当前处在的分支.此时develo ...
- Centos开机自启动脚本的制作
原文地址:http://www.2cto.com/os/201306/220559.html 我的一个Centos开机自启动脚本的制作 一.切换到/etc/init.d/ 二.制作sh脚本 v ...