rabbitmq安装与高可用集群配置
rabbitmq版本:3.6.12
rabbitmq安装
1.安装openssl
wget http://www.openssl.org/source/openssl-1.0.0a.tar.gz && tar zxvf openssl-1.0.0a.tar.gz && cd openssl-1.0.0a && ./config -fPIC --prefix=/usr/local/openssl && make && make install
编译安装openssl报错:POD document had syntax errors at /usr/bin/pod2man line 69. make: *** [install_docs]
解决方法:rm -f /usr/bin/pod2man
2.安装erlang
wget http://erlang.org/download/otp_src_18.3.tar.gz && tar xvf otp_src_18.3.tar.gz && cd otp_src_18.3 && ./configure --prefix=/usr/local/erlang --with-ssl=/usr/local/openssl -enable-threads -enable-smmp-support -enable-kernel-poll --enable-hipe --without-javac && make && make install
编译安装报错:configure: error: No curses library functions found
configure: error: /bin/sh '/home/jiayi/otp_src_18.2.1/erts/configure' failed for erts
解决方法:yum -y install ncurses-devel
3.安装rabbitmq
下载地址:http://www.rabbitmq.com/releases/rabbitmq-server/v3.6.12/rabbitmq-server-generic-unix-3.6.12.tar.xz
tar xvf rabbitmq-server-generic-unix-3.6.12.tar.xz && mv rabbitmq_server-3.6.12/ ../rabbitmq-3.6.12
添加到环境变量:cat /etc/profile.d/path.sh
#!/bin/bash
export PATH=$PATH:/usr/local/erlang/bin:/usr/local/rabbitmq-3.6.12/sbin
启动rabbitmq:rabbitmq-server -detached
开启管理页面插件:rabbitmq-plugins enable rabbitmq_management
配置集群
rabbitmq的两种集群模式:普通模式、镜像模式。
普通模式:默认的集群模式
RabbitMQ集群中节点包括内存节点、磁盘节点。内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘上。如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。那么内存节点的性能只能体现在资源管理上,比如增加或删除队列(queue),虚拟主机(vrtual hosts),交换机(exchange)等,发送和接受message速度同磁盘节点一样。一个集群至少要有一个磁盘节点。一个rabbitmq集群中可以共享user,vhost,exchange等,所有的数据和状态都是必须在所有节点上复制的,对于queue根据集群模式不同,应该有不同的表现。在集群模式下只要有任何一个节点能够工作,RabbitMQ集群对外就能提供服务。
默认的集群模式,queue创建之后,如果没有其它policy,则queue就会按照普通模式集群。对于Queue来说,消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构,但队列的元数据仅保存有一份,即创建该队列的rabbitmq节点(A节点),当A节点宕机,你可以去其B节点查看,./rabbitmqctl list_queues发现该队列已经丢失,但声明的exchange还存在。
当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer,所以consumer应平均连接每一个节点,从中取消息。该模式存在一个问题就是当A节点故障后,B节点无法取到A节点中还未消费的消息实体。如果做了队列持久化或消息持久化,那么得等A节点恢复,然后才可被消费,并且在A节点恢复之前其它节点不能再创建A节点已经创建过的持久队列;如果没有持久化的话,消息就会失丢。这种模式更适合非持久化队列,只有该队列是非持久的,客户端才能重新连接到集群里的其他节点,并重新创建队列。假如该队列是持久化的,那么唯一办法是将故障节点恢复起来。
为什么RabbitMQ不将队列复制到集群里每个节点呢?这与它的集群的设计本意相冲突,集群的设计目的就是增加更多节点时,能线性的增加性能(CPU、内存)和容量(内存、磁盘)。当然RabbitMQ新版本集群也支持队列复制(有个选项可以配置)。比如在有五个节点的集群里,可以指定某个队列的内容在2个节点上进行存储,从而在性能与高可用性之间取得一个平衡(应该就是指镜像模式)。
镜像模式:把需要的队列做成镜像队列,存在于多个节点,属于RabbitMQ的HA方案。
该模式解决了上述问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在consumer取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用,一个队列想做成镜像队列,需要先设置policy,然后客户端创建队列的时候,rabbitmq集群根据“队列名称”自动设置是普通集群模式或镜像队列。
配置步骤
1.修改/etc/hosts,加入集群节点描述:
172.31.11.235 testmq
172.31.10.248 test01
2.将testmq的.erlang.cookie内容复制到test01上
保持 testmq的.erlang.cookie与test01的一致
3.将test01加入到集群中(注意开放防火墙,端口:5672,15672,25672)
test01 # rabbitmqctl stop_app
test01 # rabbitmqctl join_cluster rabbit@testmq
test01 # rabbitmqctl start_app
查看集群状态:
-bash-4.2$ rabbitmqctl cluster_status
Cluster status of node rabbit@testmq
[{nodes,[{disc,[rabbit@test01,rabbit@testmq]}]},
{running_nodes,[rabbit@test01,rabbit@testmq]},
{cluster_name,<<"rabbit@testmq">>},
{partitions,[]},
{alarms,[{rabbit@test01,[]},{rabbit@testmq,[]}]}]
4.配置镜像队列策略
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
5.配置负载均衡器
网上推荐使用haproxy,我这边使用的aws服务,直接使用现成的elb去实现。

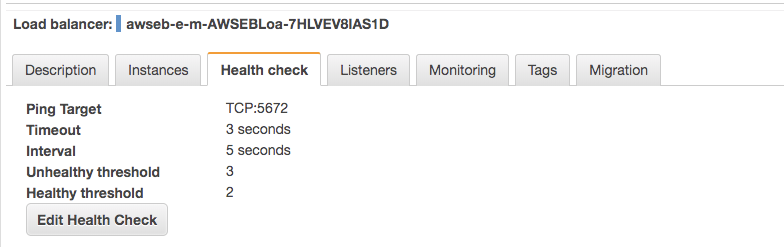
集群高可用测试:登录rabbitmq管理界面, 分别从两台服务器push消息,然后关闭,观察另一台服务器是否正常同步消息。
参考链接:https://my.oschina.net/u/1186749/blog/813156
http://www.ywnds.com/?p=4741
rabbitmq安装与高可用集群配置的更多相关文章
- 大数据高可用集群环境安装与配置(09)——安装Spark高可用集群
1. 获取spark下载链接 登录官网:http://spark.apache.org/downloads.html 选择要下载的版本 2. 执行命令下载并安装 cd /usr/local/src/ ...
- (十)RabbitMQ消息队列-高可用集群部署实战
原文:(十)RabbitMQ消息队列-高可用集群部署实战 前几章讲到RabbitMQ单主机模式的搭建和使用,我们在实际生产环境中出于对性能还有可用性的考虑会采用集群的模式来部署RabbitMQ. Ra ...
- 使用kubeadm安装kubernetes高可用集群
kubeadm安装kubernetes高可用集群搭建 第一步:首先搭建etcd集群 yum install -y etcd 配置文件 /etc/etcd/etcd.confETCD_NAME=inf ...
- MongoDB高可用集群配置方案
原文链接:https://www.jianshu.com/p/e7e70ca7c7e5 高可用性即HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非 ...
- MongoDB高可用集群配置的方案
>>高可用集群的解决方案 高可用性即HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性. ...
- SpringCloud-day04-Eureka高可用集群配置
5.4Eureka高可用集群配置 在高并发的情况下一个注册中心难以满足,因此一般需要集群配置多台. 我们再新建两个module microservice-eureka-server-2002, m ...
- Eureka注册中心高可用集群配置
Eureka高可用集群配置 当注册中心扛不住高并发的时候,这时候 要用集群来扛: 我们再新建两个module microservice-eureka-server-2002 microservic ...
- Hadoop入门学习笔记-第三天(Yarn高可用集群配置及计算案例)
什么是mapreduce 首先让我们来重温一下 hadoop 的四大组件:HDFS:分布式存储系统MapReduce:分布式计算系统YARN: hadoop 的资源调度系统Common: 以上三大组件 ...
- rabbitmq+ keepalived+haproxy高可用集群详细命令
公司要用rabbitmq研究了两周,特把 rabbitmq 高可用的研究成果备下 后续会更新封装的类库 安装erlang wget http://www.gelou.me/yum/erlang-18. ...
随机推荐
- vscode 同步配置
按照插件完成配置之后,将token保存在本地,编辑配置文件:ctrl+3.sync高级选项.编辑本地扩展设置.将token粘贴进去即可,团队所有vscode均应该按照此配置来保持统一:
- python nose 自写插件支持用例带进度
在自动化测试过程中,当用例很多且要跑很久时,就会出现这样一个问题,不知道当前跑到第几个用例了,还有多少用例要跑,怎么办? 因为用的nose框架,那就看看nose有没有这样的库支持,结果看了一圈,只找到 ...
- GO语言-基础语法:循环
golang只有for没有while package main import ( "fmt" "os" "bufio" ) func for ...
- vi替换字符串
:%s/vivian/sky/g(等同于 :g/vivian/s//sky/g) 替换每一行中所有 vivian 为 sky
- p1010幂次方---(分治)
题目描述 任何一个正整数都可以用222的幂次方表示.例如 137=27+23+20137=2^7+2^3+2^0 137=27+23+20 同时约定方次用括号来表示,即aba^bab 可表示为a(b) ...
- pro.antd.design
有关react的ui组建antd.design新推出的pro版本,最近用到了路由方面. common与routes; 首先需要在menu.js里面配置: { name: '精品', icon: 'da ...
- 转:sql篇 select from where group by having order by
原文地址: sql篇 select from where group by having order by select from where group by having order by 的基 ...
- python_打包成exe
1. 安装pyinstaller pip install pyinstaller 或通过国内镜像下载(较快): pip install pyinstaller -i http://pypi.douba ...
- JavaWeb & Tomcat
1 JavaWeb概述 Java在服务器端的应用有Servlet,JSP和第三方框架等. Java的Web框架基本都遵循特定的路数:使用Servlet或者Filter拦截请求,使用MVC的思想设计架构 ...
- MVC中code first方式开发,数据库的生成与更新
在使用EF的实际编程中我们经常遇到这样的问题:发现实体结构需要新增加一个字段,或者减少一个字段,急需把实体结构修改,并让数据库更新这种修改.在用Model First或者Database First的 ...