Java Volatile关键字 以及long,double在多线程中的应用
概念:
volatile关键字,官方解释:volatile可以保证可见性、顺序性、一致性。
可见性:volatile修饰的对象在加载时会告知JVM,对象在CPU的缓存上对多个线程是同时可见的。
顺序性:这里有JVM的内存屏障的概念,简单理解为:可以保证线程操作对象时是顺序执行的,详细了解可以自行查阅。
一致性:可以保证多个线程读取数据时,读取到的数据是最新的。(注意读取的是最新的数据,但不保证写回时不会覆盖其他线程修改的结果)
每一个线程运行时都有一个线程栈,线程栈保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存
变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,
在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。
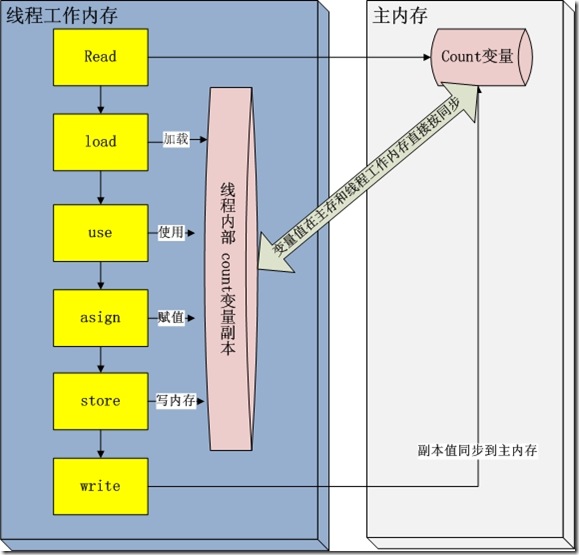
但是这一些操作并不是原子性,也就是 在read load之后,如果主内存count变量发生修改之后,线程工作内存中的值由于已经加载,不会产生对应的变化,所以计算出来的结果会和预期不一样
对于volatile修饰的变量,jvm虚拟机只是保证从主内存加载到线程工作内存的值是最新的
例如假如线程1,线程2 在进行read,load 操作中,发现主内存中count的值都是5,那么都会加载这个最新的值
在线程1堆count进行修改之后,会write到主内存中,主内存中的count变量就会变为6
线程2由于已经进行read,load操作,在进行运算之后,也会更新主内存count的变量值为6
导致两个线程及时用volatile关键字修改之后,还是会存在并发的情况。
Volatile和Static区别
static指的是类的静态成员,实例间共享
volatile跟Java的内存模型有关,线程执行时会将变量从主内存加载到线程工作内存,建立一个副本,在某个时刻写回。valatile指的每次都读取主内存的值,有更新则立即写回主内存。
理解了这两点,逐句再来解释你的困惑:
“既然static保证了唯一性”:static保证唯一性,指的是static修饰的静态成员变量是唯一的,多个实例共享这唯一一个成员。
“那么他对多个线程来说都是可见的啊”:这里,static其实跟线程没太大关系,应该说对多个对象实例是可见的。你说对多个线程可见,虽然没什么毛病,因为静态变量全局可见嘛,但是把这个理解转到线程的上线文中是困惑的起因。
“volatile保证了线程之间的可见性”:因为线程看到volatile变量会去读取主内存最新的值,而不是自个一直在那跟内部的变量副本玩,所以保证了valatile变量在各个线程间的可见性。
“那么修改的时候只要是原子操作,那么就会保证它的唯一性了吧”:此时你说的“唯一性”,指的是各个线程都能读取到唯一的最新的主内存变量,消除了线程工作内存加载变量副本可能带来的线程之间的“不唯一性”。这里“唯一性”的含义跟第一句说的“唯一性”是不一样的。
“这两个在我理解上我觉得差不多。”:其实解决问题的“场景”是完全不一样的。
造成理解困惑最大的原因在于,这两个场景略有类似,以致混淆了:
场景1:各个类的实例共享唯一一个类静态变量
场景2:各个线程共同读取唯一的最新的主内存变量的值
JVM内存模型:
lock:将一个变量标识为被一个线程独占状态
unclock:将一个变量从独占状态释放出来,释放后的变量才可以被其他线程锁定
read:将一个变量的值从主内存传输到工作内存中,以便随后的load操作
load:把read操作从主内存中得到的变量值放入工作内存的变量的副本中
use:把工作内存中的一个变量的值传给执行引擎,每当虚拟机遇到一个使用到变量的指令时都会使用该指令
assign:把一个从执行引擎接收到的值赋给工作内存中的变量,每当虚拟机遇到一个给变量赋值的指令时,都要使用该操作
store:把工作内存中的一个变量的值传递给主内存,以便随后的write操作
write:把store操作从工作内存中得到的变量的值写到主内存中的变量
内存屏障
内存屏障(Memory Barrier)也称为内存栅栏或栅栏指令,是一种CPU屏障指令,它使CPU或编译器对屏障指令之前和之后发出的内存操作执行一个排序约束。 这通常意味着在屏障之前发布的操作被保证在屏障之后发布的操作之前执行。
内存屏障共分为四种类型:
LoadLoad屏障:
抽象场景:Load1; LoadLoad; Load2
Load1 和 Load2 代表两条读取指令。在Load2要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:
抽象场景:Store1; StoreStore; Store2
Store1 和 Store2代表两条写入指令。在Store2写入执行前,保证Store1的写入操作对其它处理器可见
LoadStore屏障:
抽象场景:Load1; LoadStore; Store2
在Store2被写入前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:
抽象场景:Store1; StoreLoad; Load2
在Load2读取操作执行前,保证Store1的写入对所有处理器可见。StoreLoad屏障的开销是四种屏障中最大的。
在一个变量被volatile修饰后,JVM会为我们做两件事:
1.在每个volatile写操作前插入StoreStore屏障,在写操作后插入StoreLoad屏障。
2.在每个volatile读操作前插入LoadLoad屏障,在读操作后插入LoadStore屏障。
具体代码:
在当前的Java内存模型下,线程可以把变量保存在本地内存(比如机器的寄存器)中,而不是直接在主存中进行读写。
这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成数据的不一致。
要解决这个问题,只需要像在本程序中的这样,把该变量声明为volatile(不稳定的)即可,这就指示JVM,这个变量是不稳定的,每次使用它都到主存中进行读取。一般说来,多任务环境下各任务间共享的标志都应该加volatile修饰。
Volatile修饰的成员变量在每次被线程访问时,都强迫从共享内存中重读该成员变量的值。而且,当成员变量发生变化时,强迫线程将变化值回写到共享内存。
这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。
Code:
public class Counter {
public static int count = 0;
public static void inc() {
//这里延迟1毫秒,使得结果明显
try {
Thread.sleep(1);
} catch (InterruptedException e) {
}
count++;
}
public static void main(String[] args) {
//同时启动1000个线程,去进行i++计算,看看实际结果
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
Counter.inc();
}
}).start();
}
//这里每次运行的值都有可能不同,可能为1000
System.out.println("运行结果:Counter.count=" + Counter.count);
}
}
Output:
运行结果:Counter.count=980
添加Volatile
public class Counter {
public volatile static int count = 0;
public static void inc() {
//这里延迟1毫秒,使得结果明显
try {
Thread.sleep(1);
} catch (InterruptedException e) {
}
count++;
}
public static void main(String[] args) {
//同时启动1000个线程,去进行i++计算,看看实际结果
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
Counter.inc();
}
}).start();
}
//这里每次运行的值都有可能不同,可能为1000
System.out.println("运行结果:Counter.count=" + Counter.count);
}
}
Result:
运行结果:Counter.count=801
运行结果还是没有我们期望的1000
long,double在多线程中的情况:
java的内存模型只保证了基本变量的读取操作和写入操作都必须是原子操作的,但是对于64位存储的long和double类型来说,JVM读操作和写操作是分开的,分解为2个32位的操作,
这样当多个线程读取一个非volatile得long变量时,可能出现读取这个变量一个值的高32位和另一个值的低32位,从而导致数据的错乱。要在线程间共享long与double字段必须在synchronized中操作或是声明为volatile。
这里使用volatile,保证了long,double的可见性,那么原子性呢?
其实volatile也保证变量的读取和写入操作都是原子操作,注意这里提到的原子性只是针对变量的读取和写入,并不包括对变量的复杂操作,比如i++就无法使用volatile来确保这个操作是原子操作。
缓存一致性协议MESI
MESI的核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
在MESI协议中,每个缓存可能有有4个状态,它们分别是:
M(Modified):这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中。
E(Exclusive):这行数据有效,数据和内存中的数据一致,数据只存在于本Cache中。
S(Shared):这行数据有效,数据和内存中的数据一致,数据存在于很多Cache中。
I(Invalid):这行数据无效。
值得注意的是,传统的MESI协议中有两个行为的执行成本比较大。
一个是将某个Cache Line标记为Invalid状态,另一个是当某Cache Line当前状态为Invalid时写入新的数据。所以CPU通过Store Buffer和Invalidate Queue组件来降低这类操作的延时。
如图:
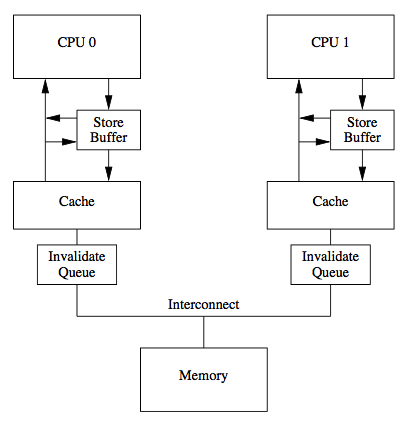
当一个CPU进行写入时,首先会给其它CPU发送Invalid消息,然后把当前写入的数据写入到Store Buffer中。然后异步在某个时刻真正的写入到Cache中。
当前CPU核如果要读Cache中的数据,需要先扫描Store Buffer之后再读取Cache。
但是此时其它CPU核是看不到当前核的Store Buffer中的数据的,要等到Store Buffer中的数据被刷到了Cache之后才会触发失效操作。
而当一个CPU核收到Invalid消息时,会把消息写入自身的Invalidate Queue中,随后异步将其设为Invalid状态。
和Store Buffer不同的是,当前CPU核心使用Cache时并不扫描Invalidate Queue部分,所以可能会有极短时间的脏读问题。
所以,为了解决缓存的一致性问题,比较典型的方案是MESI缓存一致性协议。
MESI协议,可以保证缓存的一致性,但是无法保证实时性。
volatile与MESI关系
已经有了缓存一致性协议,为什么还需要volatile?
这个问题的答案可以从多个方面来回答:
1、并不是所有的硬件架构都提供了相同的一致性保证,Java作为一门跨平台语言,JVM需要提供一个统一的语义。
2、操作系统中的缓存和JVM中线程的本地内存并不是一回事,通常我们可以认为:MESI可以解决缓存层面的可见性问题。使用volatile关键字,可以解决JVM层面的可见性问题。
3、缓存可见性问题的延伸:由于传统的MESI协议的执行成本比较大。所以CPU通过Store Buffer和Invalidate Queue组件来解决,但是由于这两个组件的引入,也导致缓存和主存之间的通信并不是实时的。也就是说,缓存一致性模型只能保证缓存变更可以保证其他缓存也跟着改变,但是不能保证立刻、马上执行。
- 其实,在计算机内存模型中,也是使用内存屏障来解决缓存的可见性问题的(再次强调:缓存可见性和并发编程中的可见性可以互相类比,但是他们并不是一回事儿)。写内存屏障(Store Memory Barrier)可以促使处理器将当前store buffer(存储缓存)的值写回主存。读内存屏障(Load Memory Barrier)可以促使处理器处理invalidate queue(失效队列)。进而避免由于Store Buffer和Invalidate Queue的非实时性带来的问题。
所以,内存屏障也是保证可见性的重要手段,操作系统通过内存屏障保证缓存间的可见性,JVM通过给volatile变量加入内存屏障保证线程之间的可见性。
总结:
其实最迷惑的地方就是为什么不是原子性,现在理解可见性,即,线程自己的工作内存,读取的是主内存的副本,因为加了volatile,所以在这个副本变量发生变化的时候必须立刻写入到主内存,后续线程读取主内存变量,就是最新的,这就是可见性,但是,在一些其他已经加载该变量副本的线程中,这个变量副本不会发生变化,并没有改变,所以volatilve并不是原子性的。
参考:
Java 中 static 和 volatile 关键字的区别?
Java Volatile关键字 以及long,double在多线程中的应用的更多相关文章
- 13、Java并发性和多线程-Java Volatile关键字
以下内容转自http://tutorials.jenkov.com/java-concurrency/volatile.html(使用谷歌翻译): Java volatile关键字用于将Java变量标 ...
- [Java并发编程(三)] Java volatile 关键字介绍
[Java并发编程(三)] Java volatile 关键字介绍 摘要 Java volatile 关键字是用来标记 Java 变量,并表示变量 "存储于主内存中" .更准确的说 ...
- Java Volatile关键字(转)
出处: Java Volatile关键字 Java的volatile关键字用于标记一个变量“应当存储在主存”.更确切地说,每次读取volatile变量,都应该从主存读取,而不是从CPU缓存读取.每次 ...
- Java volatile 关键字底层实现原理解析
本文转载自Java volatile 关键字底层实现原理解析 导语 在Java多线程并发编程中,volatile关键词扮演着重要角色,它是轻量级的synchronized,在多处理器开发中保证了共享变 ...
- Java volatile关键字详解
Java volatile关键字详解 volatile是java中的一个关键字,用于修饰变量.被此关键修饰的变量可以禁止对此变量操作的指令进行重排,还有保持内存的可见性. 简言之它的作用就是: 禁止指 ...
- 从根源上解析 Java volatile 关键字的实现
1.解析概览 内存模型的相关概念 并发编程中的三个概念 Java内存模型 深入剖析Volatile关键字 使用volatile关键字的场景 2.内存模型的相关概念 缓存一致性问题.通常称这种被多个线程 ...
- 【Java并发编程】6、volatile关键字解析&内存模型&并发编程中三概念
volatile这个关键字可能很多朋友都听说过,或许也都用过.在Java 5之前,它是一个备受争议的关键字,因为在程序中使用它往往会导致出人意料的结果.在Java 5之后,volatile关键字才得以 ...
- Java volatile关键字解惑
volatile特性 内存可见性:通俗来说就是,线程A对一个volatile变量的修改,对于其它线程来说是可见的,即线程每次获取volatile变量的值都是最新的. volatile的使用场景 通过关 ...
- java volatile 关键字(转)
volatile这个关键字可能很多朋友都听说过,或许也都用过.在Java 5之前,它是一个备受争议的关键字,因为在程序中使用它往往会导致出人意料的结果.在Java 5之后,volatile关键字才得以 ...
随机推荐
- Web 测试总结
一.输入框 1.字符型输入框: (1)字符型输入框:英文全角.英文半角.数字.空或者空格.特殊字符“~!@#¥%……&*?[]{}”特别要注意单引号和&符号.禁止直接输入特殊字符时,使 ...
- Javaweb实现对mongodb的增删改查(附带源代码)
运行截图: 删除后的信息 项目源代码:https://www.cnblogs.com/post/readauth?url=/zyt-bg/p/9807396.html
- React 学习之路 (一)
先说一说对React的体验,总结 首先react相对angular来说入手简单暴力,在学习的这段时间里发现: 我们每天做的事就是在虚拟DOM上创建元素然后在渲染到真实的DOM中 渲染到真实DOM上的R ...
- css的小知识4
---恢复内容开始--- 一.单位 1.px就是一个基本单位 像素 2.em也是一个单位 用父级元素的字体大小乘以em前面的数字.如果父级没有就继承上一个父级直到body,如果bod ...
- JQuery实现表格自动增加行,对新行添加事件
实现功能: 通常在编辑表格时表格的行数是不确定的,如果一次增加太多行可能导致页面内容太多,反应变慢:通过此程序实现表格动态增加行,一直保持最下面有多个空白行. 效果: 一:原始页面 二:表1增加新行并 ...
- day21:包和异常处理
1,复习 # 序列化模块 # json # dumps # loads # dump 和文件有关 # load load不能load多次 # pickle # 方法和json的一样 # dump和lo ...
- grep匹配字符串
基本正则表达式 元数据 意义和范例 ^word 搜寻以word开头的行. 例如:搜寻以#开头的脚本注释行 grep –n ‘^#’ regular.txt word$ 搜寻以word结束的行 例如,搜 ...
- 16.0-uC/OS-III同步
同步 uC/OS-III中用于同步的两种机制:信号量和事件标志组 . 1.信号量 信号量最初用于控制共享资源的访问.信号量可用于ISR与任务间.任务与任务间的同步. “ N”表示信号量可以被累计.初始 ...
- java框架之Quartz-任务调度&整合Spring
准备 介绍 定时任务,无论是互联网公司还是传统的软件行业都是必不可少的.Quartz,它是好多优秀的定时任务开源框架的基础,使用它,我们可以使用最简单基础的配置来轻松的使用定时任务. Quartz 是 ...
- (转载)intellj idea 如何设置类头注释和方法注释
原文地址:http://www.cnblogs.com/wvqusrtg/p/5459327.html intellj idea的强大之处就不多说了,相信每个用过它的人都会体会到, ...