Hadoop JVM调整解决 MapReduce 作业超时问题
MR汇总报错
在mr程序跑job时,reduce到一个点就卡住直到超时时间反馈超时再重试,一般都失败,如下图:
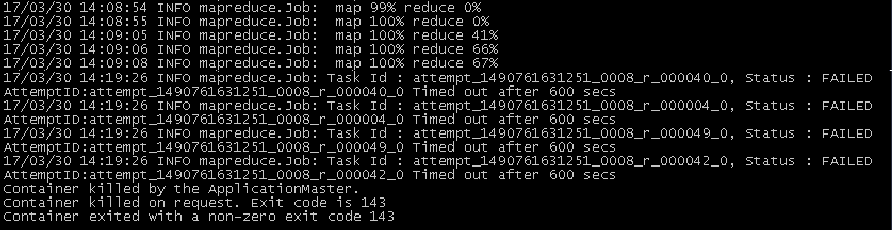
超时时间是在配置文件的默认配置:
这里的提示是Container killed by the ApplicationMaster,并没有具体参数提示。查找一些资料后发现,需要调整opts的值mapreduce.reduce.java.opts,默认4G,调试为6G测试,即值为"-Djava.net.preferIPv4Stack=true -Xmx6442450944" ,报错如下:
Container [pid=7830,containerID=container_1397098636321_27548_01_000297] is running beyond physical memory limits. Current usage: 2.1 GB of 2 GB physical memory used; 2.7 GB of 4.2 GB virtual memory used. Killing container.
这里的错误就比较明显了,物理内存不够,虚拟内存还可以(默认情况下:虚拟内存是物理内存的2.1倍)。这里是在reduce阶段有问题,所以需要调整reduce运行时的物理内存,mapreduce.reduce.memory.mb这个参数默认值为4G,调整为6144 (即6G)后,执行mr作业,正常结束。
总结了如下相关jvm设置:
参数 默认值 描述
yarn.scheduler.minimum-allocation-mb 1024 每个container请求的最低jvm配置,单位m。如果请求的内存小于该值,那么会重新设置为该值。
yarn.scheduler.maximum-allocation-mb 8192 每个container请求的最高jvm配置,单位m。如果大于该值,会被重新设置。
yarn.nodemanager.resource.memory-mb 8192 每个nodemanager节点准备最高内存配置,单位m
mapreduce.{map,reduce}.memory.mb 1024 设置运行map/reduce container的内存大小,单位m
mapreduce.{map,reduce}.java.opts -Xmx 设置执行map/reduce任务的JVM参数,值小于上一行设置的值,是在container中建立的jvm堆内存
mapreduce.map.memory.mb = (1~2倍) * yarn.scheduler.minimum-allocation-mb
mapreduce.reduce.memory.mb = (1~4倍) * yarn.scheduler.minimum-allocation-mb
总结:最终运行参数给定的jvm堆大小必须小于参数指定的map和reduce的memory大小,最好为70%以下。
Hadoop JVM调整解决 MapReduce 作业超时问题的更多相关文章
- 使用MRUnit,Mockito和PowerMock进行Hadoop MapReduce作业的单元测试
0.preliminary 环境搭建 Setup development environment Download the latest version of MRUnit jar from Apac ...
- hadoop基础----hadoop理论(四)-----hadoop分布式并行计算模型MapReduce具体解释
我们在前一章已经学习了HDFS: hadoop基础----hadoop理论(三)-----hadoop分布式文件系统HDFS详细解释 我们已经知道Hadoop=HDFS(文件系统,数据存储技术相关)+ ...
- hadoop 学习笔记:mapreduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop学习笔记:MapReduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- [大牛翻译系列]Hadoop(17)MapReduce 文件处理:小文件
5.1 小文件 大数据这个概念似乎意味着处理GB级乃至更大的文件.实际上大数据可以是大量的小文件.比如说,日志文件通常增长到MB级时就会存档.这一节中将介绍在HDFS中有效地处理小文件的技术. 技术2 ...
- 【Big Data - Hadoop - MapReduce】hadoop 学习笔记:MapReduce框架详解
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop(六)MapReduce的入门与运行原理
一 MapReduce入门 1.1 MapReduce定义 Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架: Mapreduce核心功能是将用 ...
- 高阶MapReduce_1_链接多个MapReduce作业
链接MapReduce作业 1. 顺序链接MapReduce作业 顺序链接MapReduce作业就是将多个MapReduce作业作为生成的一个自己主动化运行序列,将上一个MapReduce作 ...
- hadoop(四)MapReduce
如果将 Hadoop 比做一头大象,那么 MapReduce 就是那头大象的电脑.MapReduce 是 Hadoop 核心编程模型.在 Hadoop 中,数据处理核心就是 MapReduce 程序设 ...
随机推荐
- (026)[工具软件]剪切板管理:Ditto
剪切板管理软件:Ditto官网:http://ditto-cp.sourceforge.net/
- A*算法、导航网格、路径点寻路对比(A-Star VS NavMesh VS WayPoint)
在Unity3d中,我们一般常用的寻路算法: 1.A*算法插件 与贪婪算法不一样,贪婪算法适合动态规划,寻找局部最优解,不保证最优解.A*是静态网格中求解最短路最有效的方法.也是耗时的算法,不 ...
- ionic之自定义图片
一个好的app,必须都有很好的ui设计师来设计界面,增强客户的体验,表现自己本身公司的特色,但是,在ionic中有些是无法用img标签直接引入图片,只能通过设定的css之后引入css. 页面: < ...
- AJPFX关于表结构的相关语句
//表结构的相关语句==================================== 建表语句: create table 表名( ...
- pageHelper分页插件失效问题
在bootstrap中引用pageHelper进行页面分页<dependency><groupId>com.github.pagehelper</groupId>& ...
- UVM挑战及概述
UVM的调度也具有其独特的挑战,尤其是在调试的领域.其中的一些挑战如下: 1. Phase的管理:objections and synchronization 2. 线程调试 3. Tracing i ...
- /usr/bin/install -c -m 644 sample-config/httpd.conf /etc/httpd/conf.d/nagios.conf
[root@localhost nagios]# make install-webconf/usr/bin/install -c -m 644 sample-config/httpd.conf /et ...
- Linux系统下查找文件的方法
Linux系统下查找文件的方法 作者:Vashon 时间:20150419 方法一.在当前目录里查找所有名为以 java 开头的文件: find ./ -name "java*" ...
- 不需要用任何辅助工具打包Qt应用程序
不需要用任何辅助工具打包Qt应用程序.方法如下: 生成release文件后,双击里面的exe文件,会弹出一个对话框,里面提示缺少哪一个DLL文件, 然后根据该文件名到你安装QT软件的目录下的/b ...
- http以及http协议简单理解
HTTP协议是超文本传输协议的缩写,是用于从万维网(WWW)服务器传输超文本到本地浏览器的传送协议:HTTP是一个基于TCP/IP通信协议来传递数据(HTML文件, 图片文件, 查询结果等)HTTP作 ...