Hadoop JVM调整解决 MapReduce 作业超时问题
MR汇总报错
在mr程序跑job时,reduce到一个点就卡住直到超时时间反馈超时再重试,一般都失败,如下图:
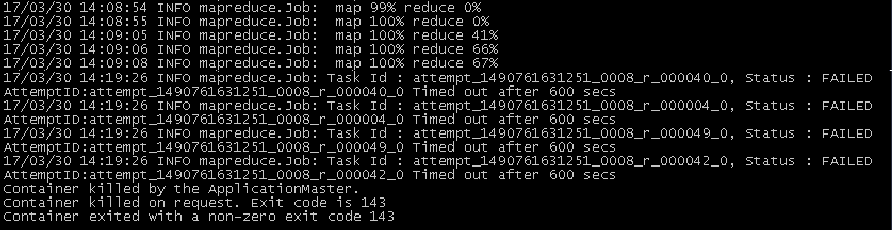
超时时间是在配置文件的默认配置:
这里的提示是Container killed by the ApplicationMaster,并没有具体参数提示。查找一些资料后发现,需要调整opts的值mapreduce.reduce.java.opts,默认4G,调试为6G测试,即值为"-Djava.net.preferIPv4Stack=true -Xmx6442450944" ,报错如下:
Container [pid=7830,containerID=container_1397098636321_27548_01_000297] is running beyond physical memory limits. Current usage: 2.1 GB of 2 GB physical memory used; 2.7 GB of 4.2 GB virtual memory used. Killing container.
这里的错误就比较明显了,物理内存不够,虚拟内存还可以(默认情况下:虚拟内存是物理内存的2.1倍)。这里是在reduce阶段有问题,所以需要调整reduce运行时的物理内存,mapreduce.reduce.memory.mb这个参数默认值为4G,调整为6144 (即6G)后,执行mr作业,正常结束。
总结了如下相关jvm设置:
参数 默认值 描述
yarn.scheduler.minimum-allocation-mb 1024 每个container请求的最低jvm配置,单位m。如果请求的内存小于该值,那么会重新设置为该值。
yarn.scheduler.maximum-allocation-mb 8192 每个container请求的最高jvm配置,单位m。如果大于该值,会被重新设置。
yarn.nodemanager.resource.memory-mb 8192 每个nodemanager节点准备最高内存配置,单位m
mapreduce.{map,reduce}.memory.mb 1024 设置运行map/reduce container的内存大小,单位m
mapreduce.{map,reduce}.java.opts -Xmx 设置执行map/reduce任务的JVM参数,值小于上一行设置的值,是在container中建立的jvm堆内存
mapreduce.map.memory.mb = (1~2倍) * yarn.scheduler.minimum-allocation-mb
mapreduce.reduce.memory.mb = (1~4倍) * yarn.scheduler.minimum-allocation-mb
总结:最终运行参数给定的jvm堆大小必须小于参数指定的map和reduce的memory大小,最好为70%以下。
Hadoop JVM调整解决 MapReduce 作业超时问题的更多相关文章
- 使用MRUnit,Mockito和PowerMock进行Hadoop MapReduce作业的单元测试
0.preliminary 环境搭建 Setup development environment Download the latest version of MRUnit jar from Apac ...
- hadoop基础----hadoop理论(四)-----hadoop分布式并行计算模型MapReduce具体解释
我们在前一章已经学习了HDFS: hadoop基础----hadoop理论(三)-----hadoop分布式文件系统HDFS详细解释 我们已经知道Hadoop=HDFS(文件系统,数据存储技术相关)+ ...
- hadoop 学习笔记:mapreduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop学习笔记:MapReduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- [大牛翻译系列]Hadoop(17)MapReduce 文件处理:小文件
5.1 小文件 大数据这个概念似乎意味着处理GB级乃至更大的文件.实际上大数据可以是大量的小文件.比如说,日志文件通常增长到MB级时就会存档.这一节中将介绍在HDFS中有效地处理小文件的技术. 技术2 ...
- 【Big Data - Hadoop - MapReduce】hadoop 学习笔记:MapReduce框架详解
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop(六)MapReduce的入门与运行原理
一 MapReduce入门 1.1 MapReduce定义 Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架: Mapreduce核心功能是将用 ...
- 高阶MapReduce_1_链接多个MapReduce作业
链接MapReduce作业 1. 顺序链接MapReduce作业 顺序链接MapReduce作业就是将多个MapReduce作业作为生成的一个自己主动化运行序列,将上一个MapReduce作 ...
- hadoop(四)MapReduce
如果将 Hadoop 比做一头大象,那么 MapReduce 就是那头大象的电脑.MapReduce 是 Hadoop 核心编程模型.在 Hadoop 中,数据处理核心就是 MapReduce 程序设 ...
随机推荐
- 136 Single Number 数组中除一个数外其他数都出现两次,找出只出现一次的数
给定一个整数数组,除了某个元素外其余元素均出现两次.请找出这个只出现一次的元素.备注:你的算法应该是一个线性时间复杂度. 你可以不用额外空间来实现它吗? 详见:https://leetcode.com ...
- poj1815Friendship(最小割求割边)
链接 题意为去掉多少个顶点使图不连通,求顶点连通度问题.拆点,构造图,对于<u,v>可以变成<u2,v1> <v2,u1>容量为无穷,<u1,u2>容量 ...
- Ionic之数据绑定ng-model
ionic 完美的融合下一代移动框架,ionic 基于Angular语法,支持 Angularjs 的特性.但是我在开发的时候,遇到了坑.因为之后用的就是angularjs,so 理所当然的以为代码应 ...
- 作用域链、this细说
一.作用域链 作用域:浏览器给js的一个生存环境(栈内存) 作用域链:js中的关键字var和function 都可以提前声明和定义,提前声明和定义的放在我们的内存地址(堆内存)中.然后js从上到下逐行 ...
- Arduino Ethernet W5100扩展板的指示灯含义
Arduino Ethernet W5100扩展板是继承WIZnet W5100网络芯片的扩展板.将扩展板连接到Arduino后,可使Arduino具有网络功能.此扩展板上有多个指示灯,由于轻易查不到 ...
- (转)IC设计完整流程及工具
IC的设计过程可分为两个部分,分别为:前端设计(也称逻辑设计)和后端设计(也称物理设计),这两个部分并没有统一严格的界限,凡涉及到与工艺有关的设计可称为后端设计. 前端设计的主要流程: 1.规格制定 ...
- 如何查看安装的java是32位的,还是64位的
命令 java -d32 -version 或者 java -d64 -version
- Java练习题01
问题: 利用二维非矩阵数组输出下面的数字 0 1 2 2 3 4 3 4 5 6 代码: public class Page98{ public static void main(String ...
- ES5函数新增的方法(call、apply、bind)
1.call()的使用<script type="text/javascript"> var obj1 = { name:'bob', fn:function(){ c ...
- UVALive 2238 Fixed Partition Memory Management 固定分区内存管理(KM算法,变形)
题意:目前有一部分可用内存,分为m个大小固定的区域.现有n个程序要执行,每个程序在不同大小的内存中运行所需的时间不同,要使运行完所有程序所耗时最少,问每个程序在哪块区域中从什么时间运行到什么时间,以及 ...