Hadoop中序列化与Writable接口
学习笔记,整理自《Hadoop权威指南 第3版》
一、序列化
序列化:序列化是将 内存 中的结构化数据 转化为 能在网络上传输 或 磁盘中进行永久保存的二进制流的过程;反序列化:序列化的逆过程;
应用:进程间通信、网络传输、持久化;
Hadoop中是使用的自己的序列化格式Writable,以及结合用Avro弥补一些Writable的不足;
二:Writable接口 相关:
主要是3个接口:
Writable接口
WritableComparable接口
RawComparator接口
Writable接口中主要是两个方法:write 和 readFields
//Writable接口原形
public interface Writabel{
void write(DataOutput out)throws IOException;
void readFields(DataInput in) throws IOException;
}
WritableComparable接口:继承自Writable接口 和 Comparable<T>接口;即有序列功能,也有比较排序功能;
public interface WritableComparable<T> extends Writable,Comparable<T>{
}
Hadoop自定义比较排序接口:RawComparator接口,该接口允许实现比较数据流中的记录,而不用把数据流反序列化为对象,从而避免了新建对象的额外开销;
可参考:Hadoop-2.4.1学习之RawComparator及其实现
public interface RawComparator<T> extends Comparator<T>{
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}
工具类WritableComparator:a. 充当RawComparator的实例工厂;b. 提供了对原始compare()方法的一个默认实现;
RawComparator<IntWritable> comparator = WritableComparator.get(IntWritable.class);
//获取的comparator 即可比较两个IntWritable对象,也可直接比较两个序列化数据:
//比较两上IntWritable对象
IntWritable w1 = new IntWritable(163);
IntWritable w2 = new IntWritable(67):
comparator.compare(w1, w2);
//比较其序列化
byte[] b1 = serialize(w1);
byte[] b2 = serialize(w2);
comparator.compare(b1, 0, b1.length, b2, 0, b2.length);
三、Writable继承图
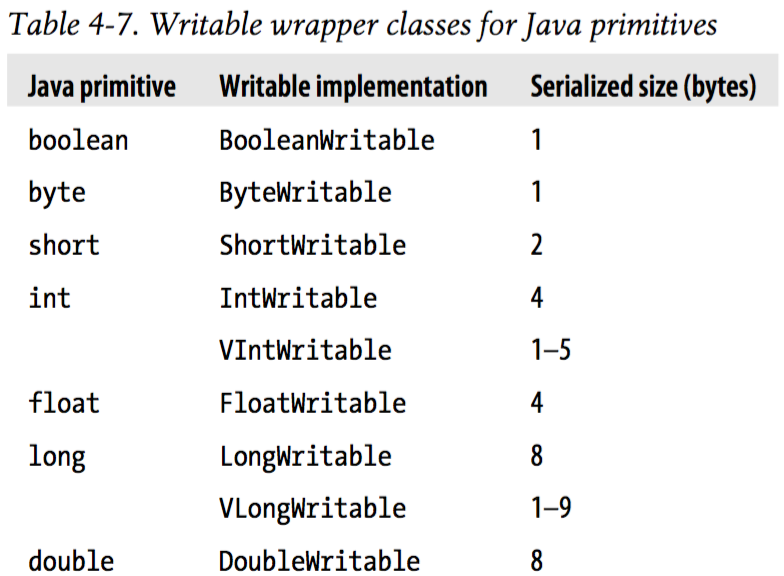
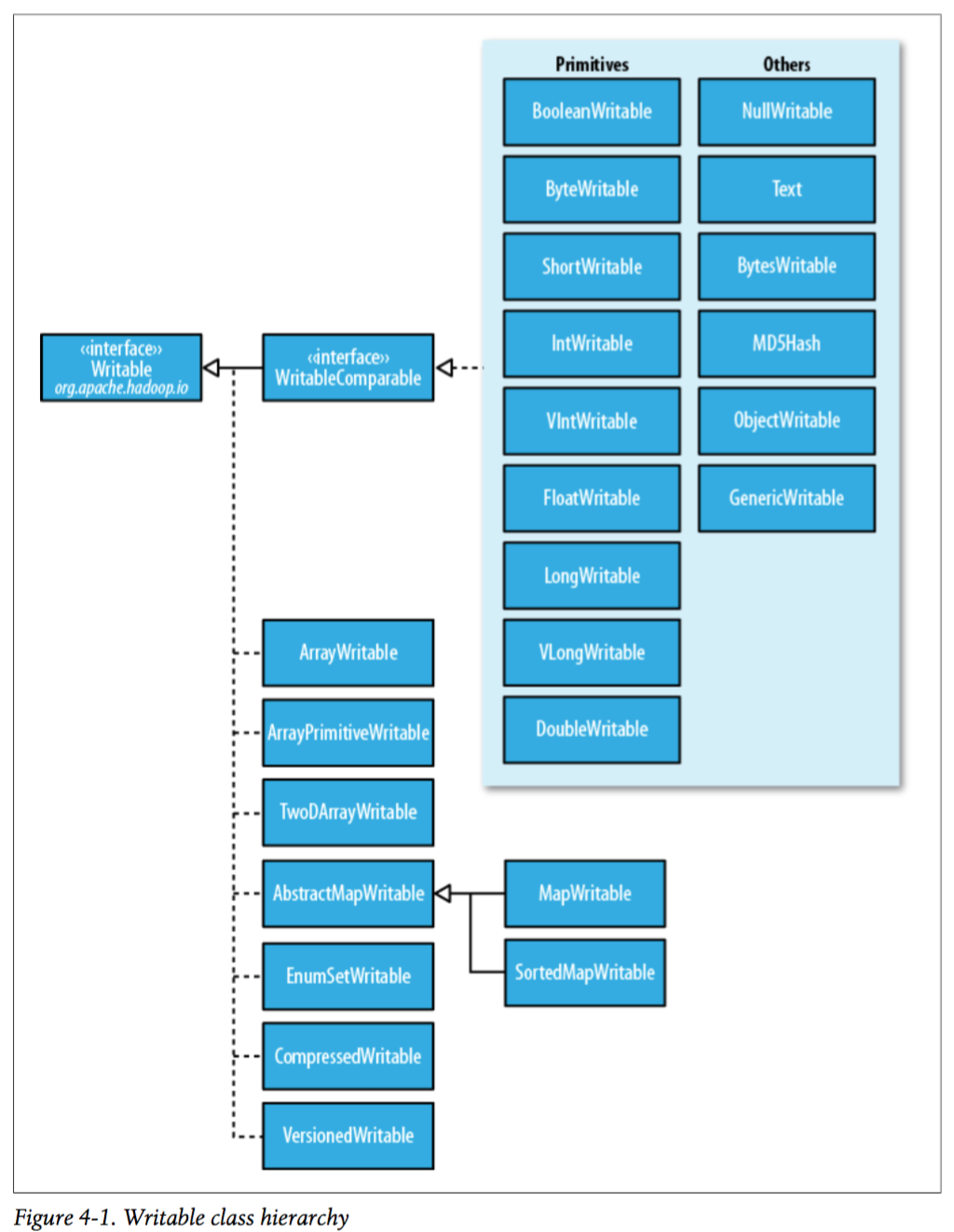
以上可以看出,包含了除了char类型外 Java基本类型的封装;其中Text对应Java中的String;
四、自定义一个Writable
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable; public class TextPair implements WritableComparable<TextPair> {
private Text first;
private Text second; public TextPair() {
set(new Text(), new Text());
} public void set(Text first, Text second) {
this.first = first;
this.second = second;
} public Text getFirst() {
return this.first;
} public Text getSecond() {
return this.second;
} @Override
public void write(DataOutput out) throws IOException {
first.write(out);
second.write(out);
} @Override
public void readFields(DataInput in) throws IOException {
first.readFields(in);
second.readFields(in);
} @Override
public int hashCode() {
return first.hashCode() * 163 + second.hashCode();
} @Override
public boolean equals(Object o) {
if (this == o)
return true; if (o instanceof TextPair) {
TextPair tp = (TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
} @Override
public int compareTo(TextPair tp) {
int cmp = first.compareTo(tp.first);
if (cmp != 0) {
return cmp;
}
return second.compareTo(tp.second);
} @Override
public String toString() {
return first + "\t" + second;
} }
以上可以看出,主要是要实现5个方法,都是重写方法,其中序列化的write()、readFields()2个方法,排序的compareTo(),以及hashCode()和equals()2两个基本方法。
五、序列化框架Avro
可参考:Avro总结(RPC/序列化)
http://www.open-open.com/lib/view/open1369363962228.html
六、SequenceFile MapFile
SequenceFile
SequenceFile是一个由二进制序列化过的key/value的字节流组成的文本存储文件;在map/reduce过程中,map处理文件的临时输出就是使用SequenceFile处理过的。
用途:
1、纯文本不合适记录二进制类型的数据,这种情况下,Hadoop的SequenceFile类非常合适,为二进制键/值对提供一个持久数据结构。并可对key value压缩处理。
2、SequenceFile可作为小文件的容器,HDFS和MR更适合处理大文件。
定位文件位置的两种方法:
1、seek(long poisitiuion):poisition必须是记录的边界,否则调用next()方法时会报错
2、sync(long poisition):Poisition可以不是记录的边界,如果不是边界,会定位到下一个同步点,如果Poisition之后没有同步点了,会跳转到文件的结尾位置
三种压缩态:
Uncompressed – 未进行压缩的状
Record compressed - 对每一条记录的value值进行了压缩(文件头中包含上使用哪种压缩算法的信息)
Block compressed – 当数据量达到一定大小后,将停止写入一个block压缩;整体压缩的方法是把所有的keylength,key,vlength,value 分别合在一起进行整体压缩,块的压缩效率要比记录的压缩效率高;
写入SequenceFile:
package com.lcy.hadoop.io; import java.net.URI; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text; public class SequenceFileWriteDemo { private static final String [] DATA={
"One,two,buckle my shoe",
"Three,four,shut the door",
"Five,six,pick up sticks",
"Seven,eight,lay them straight",
"Nine,ten,a big fat hen"
}; public static void main(String[] args) throws Exception{
// TODO Auto-generated method stub
String uri=args[0];
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(URI.create(uri),conf);
Path path=new Path(uri); IntWritable key=new IntWritable();
Text value=new Text();
SequenceFile.Writer writer=null;
try{
writer=SequenceFile.createWriter(fs,conf,path,key.getClass(),value.getClass());
for(int i=0;i<100;i++){
key.set(100-i);
value.set(DATA[i%DATA.length]);
System.out.printf("[%s]\t%s\t%s\n",writer.getLength(),key,value);
writer.append(key, value);
}
}finally{
IOUtils.closeStream(writer);
}
}
}
读取SequenceFile:
//从头到尾读取顺序文件就是创建SequenceFile.Reader实例后反复调用next()方法迭代读取记录
//如果next()方法返回的是非null对象,则可以从该数据流中读取键值对 package com.lcy.hadoop.io; import java.net.URI; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.ReflectionUtils; public class SequenceFileReadDemo { public static void main(String[] args) throws Exception{
// TODO Auto-generated method stub
String uri=args[0];
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(URI.create(uri),conf);
Path path=new Path(uri);
SequenceFile.Reader reader=null;
try{
reader=new SequenceFile.Reader(fs, path, conf);
Writable key=(Writable)ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value=(Writable)ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position=reader.getPosition();
while(reader.next(key,value)){
String syncSeen=reader.syncSeen()?"*":" ";
System.out.printf("[%s%s]\t%s\t%s\n",position,syncSeen,key,value);
position=reader.getPosition();
}
}finally{
IOUtils.closeStream(reader);
}
}
}
在命令行下,可有-text 参数来查看gzip压缩文件 和 序列文件,否则直接查看可能是乱码;
SequenceFile内部格式:
组成:
SequenceFile由一个header 和 随后的 多条记录组成;
header包含:前三字节是SequenceFile文件代码SEQ;版本号;key value类型;压缩细节;
同步标识sync:用于读取文件时能够从任意位置开始识别记录边界。同步标识位于记录和记录之间,因为额外存储开销(1%),没必要在每个记录后都有标识
1、 record压缩:
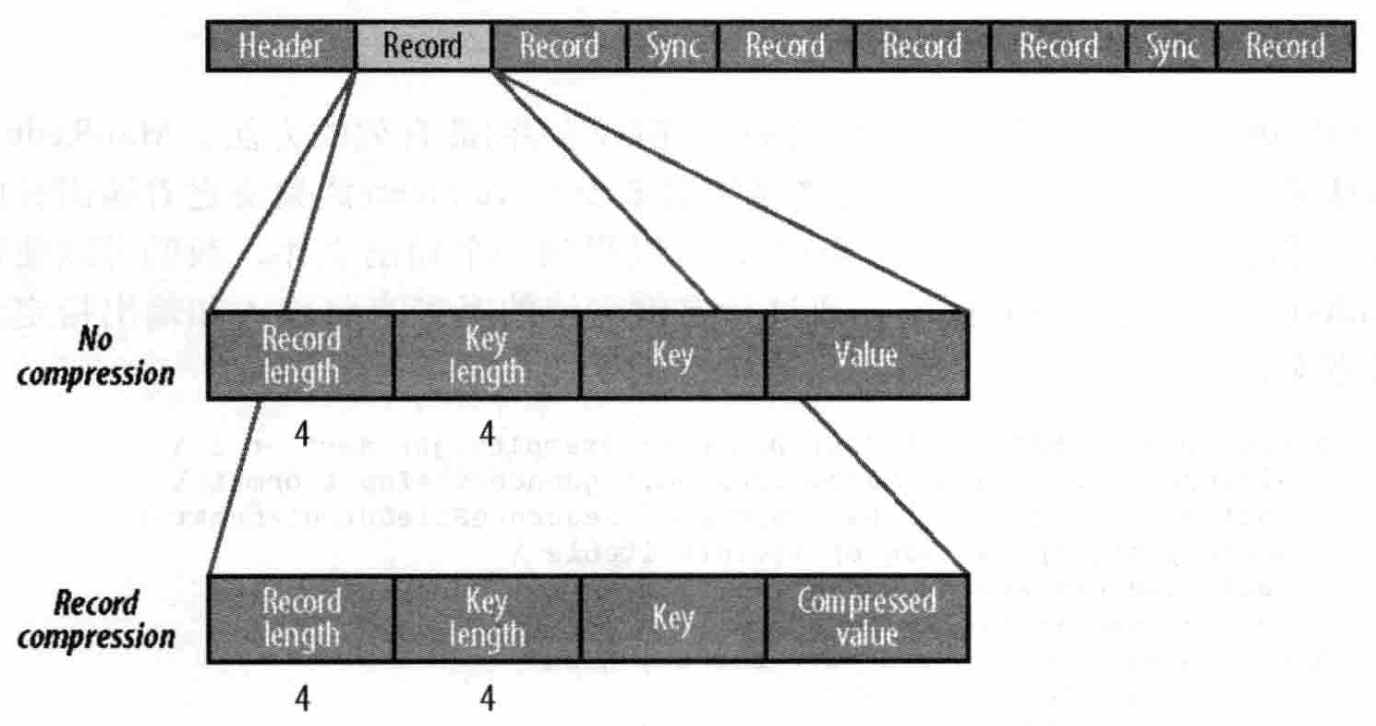
record压缩 和 无压缩基本相同,只不过是值value用文件头中定义的codec压缩过,而其它key、length都不变;
2、block压缩:

block压缩是指一次性压缩多条记录,压缩率较高;
压缩时是向一个压缩块中添加记录,直到压缩后的block大于定义的值(默认为1MB)每个新块的开始都会有一个同步标识;
压缩后的格式:首先是一个指示数据块中字节数的字段;紧接着是4个字段(键长,键;值长,值 )
MapFile
MapFile是已排序过的SequenceFile,它含有索引,可快速随机读取(二分查找);
创建一个map类型的文件,实际会合成一个文件夹,文件夹中包含两部分:


MapFile的读类型SequenceFile,别外包含两个随机读取key的方法:
public Writable get(WritableComparable key, Writable val) throws IOException
public Writable getClosest(WritableComparable key, Writable val) throws IOException//返回最近的key,不会因为找不到返回null;
Hadoop中序列化与Writable接口的更多相关文章
- Hadoop序列化与Writable接口(二)
Hadoop序列化与Writable接口(二) 上一篇文章Hadoop序列化与Writable接口(一)介绍了Hadoop序列化,Hadoop Writable接口以及如何定制自己的Writable类 ...
- Hadoop序列化与Writable接口(一)
Hadoop序列化与Writable接口(一) 序列化 序列化(serialization)是指将结构化的对象转化为字节流,以便在网络上传输或者写入到硬盘进行永久存储:相对的反序列化(deserial ...
- hadoop中的序列化与Writable接口
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable-interface.html,转载请注明源地址. 简介 序列化和反序列化就是结构化对象 ...
- hadoop中实现定制Writable类
Hadoop中有一套Writable实现可以满足大部分需求,但是在有些情况下,我们需要根据自己的需要构造一个新的实现,有了定制的Writable,我们就可以完全控制二进制表示和排序顺序. 为了演示如何 ...
- Hadoop中Writable类之四
1.定制Writable类型 Hadoop中有一套Writable实现,例如:IntWritable.Text等,但是,有时候可能并不能满足自己的需求,这个时候,就需要自己定制Writable类型. ...
- Hadoop Serialization hadoop序列化详解(最新版) (1)【java和hadoop序列化比较和writable接口】
初学java的人肯定对java序列化记忆犹新.最开始很多人并不会一下子理解序列化的意义所在.这样子是因为很多人还是对java最底层的特性不是特别理解,当你经验丰富,对java理解更加深刻之后,你就会发 ...
- 为什么hadoop中用到的序列化不是java的serilaziable接口去序列化而是使用Writable序列化框架
继上一个模块之后,此次分析的内容是来到了Hadoop IO相关的模块了,IO系统的模块可谓是一个比较大的模块,在Hadoop Common中的io,主要包括2个大的子模块构成,1个是以Writable ...
- Hadoop基础-序列化与反序列化(实现Writable接口)
Hadoop基础-序列化与反序列化(实现Writable接口) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.序列化简介 1>.什么是序列化 序列化也称串行化,是将结构化 ...
- hadoop中的序列化与Writable类
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable-class.html,转载请注明源地址. hadoop中自带的org.apache.h ...
随机推荐
- 【bzoj4320】【ShangHai2006 Homework】【并查集+离线处理】
ShangHai2006 Homework Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 918 Solved: 460[Submit][Statu ...
- 假几何真逆序数 NB HDU3465
题意: 有n条直线,问他们两两在横坐标开区间(L,R)之间相交的个数 n=50000,暴力肯定就不用想了,如果在纸上画一画可以发现如果两条直线在(L,R)内相交,那么他们与x= L和x=R的交点序数是 ...
- objective-c中#import和@class的区别
在Objective-C中,可以使用#import和@class来引用别的类型, 但是你知道两者有什么区别吗? @class叫做forward-class, 你经常会在头文件的定义中看到通过@cla ...
- [TJOI2019]唱、跳、rap和篮球_生成函数_容斥原理_ntt
[TJOI2019]唱.跳.rap和篮球 这么多人过没人写题解啊 那我就随便说说了嗷 这题第一步挺套路的,就是题目要求不能存在balabala的时候考虑正难则反,要求必须存在的方案数然后用总数减,往往 ...
- 一点点VIM
VIM 当你喜欢它时,你会发现真的不错,不过配置真是麻烦, 不过万事开头难,当你熟练时真的会发现她的美. syntax on set nu colo evening set mouse=a set c ...
- luogu P1476 休息中的小呆
题目描述 当大家在考场中接受考验(折磨?)的时候,小呆正在悠闲(欠扁)地玩一个叫“最初梦想”的游戏.游戏描述的是一个叫pass的有志少年在不同的时空穿越对抗传说中的大魔王chinesesonic的故事 ...
- CodeChef - METEORAK Meteor
Read problems statements in Mandarin Chineseand Russian. A meteor fell on Andrew's house. That's why ...
- Google的JSON风格指南
官网:https://google.github.io/styleguide/jsoncstyleguide.xml 中文版:https://github.com/darcyliu/google-st ...
- FIREDAC字段类型映射
为什么需要字段类型映射? 作为通用型数据引擎的FIREDAC或者UNIDAC,驱动某一种数据库以后,总有一些数据库的一些字段类型,数据引擎不能识别,反应到程序中就是数据引擎不能正确地读取该字段的值 . ...
- 第21章、OnItemSelectedListener事件(从零开始学Android)
在Android App应用中,OnItemSelectedListener事件也会经常用到,我们一起来了解一下. 基本知识点:OnItemSelectedListener事件 一.界面 1.新建pr ...