influxDB系列(一)
这个是github上面一个人总结的influxDB的操作手册,还不错:https://xtutu.gitbooks.io/influxdb-handbook/content/zeng.html
1. influxDB是什么呢?
InfluxDB 是一个开源分布式时序、事件和指标数据库。
使用 Go 语言编写,无需外部依赖。其设计目标是实现分布式和水平伸缩扩展。
2. 怎么使用influxDB呢?
类比的方法学习! ---》 nfluxDB提供类SQL语法, 所以熟悉sql 语法的话,就可以类比学习。
向“表”中插入数据(influx 中不叫做表,叫做 measurement --度量值/测量值)
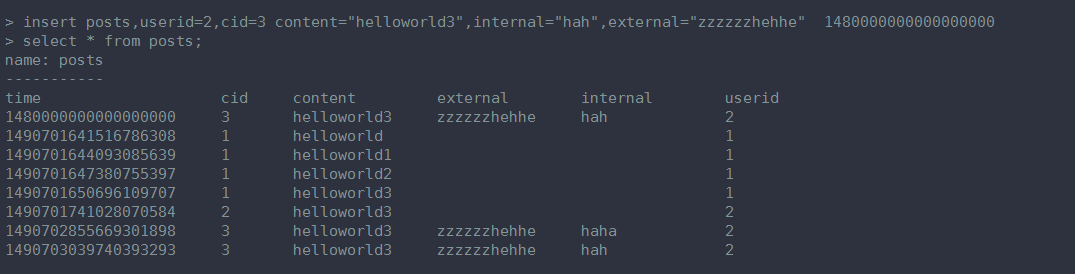
insert posts,userid=2,cid=3 content="helloworld3",internal="hah",external="zzzzzzhehhe" 1480000000000000000
这条插入数据的语句的意思:语法
insert posts 这里 posts 相当于表名称。
,userid=2,cid=3 这部分相当于 索引 (show tag keys from posts 的时候,可以看到 这个posts 表的索引有两个 cid 和userid)
content="helloworld3",internal="hah",external="zzzzzzzhehe" 1480000000000000000 前面用一个 空格隔开,表示开始向这个表的插入记录了,可以有任意个数的“字段”
像我们这条语句中就是有3个字段, 最后黄色的部分是时间戳(可以不写,会自动插入的, 如果有写的话,就会插入我们自己定义的时间戳)。
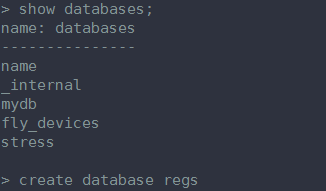
下面我演示一下从头开始新建一个数据库,建表和插入数据。
1、创建数据库
2、建表

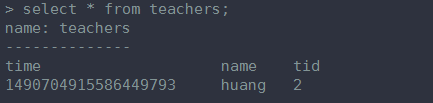
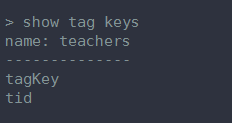
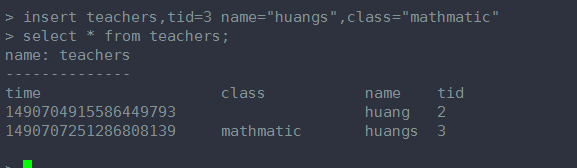
字段数目可以随意
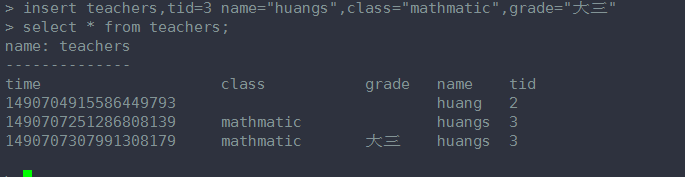
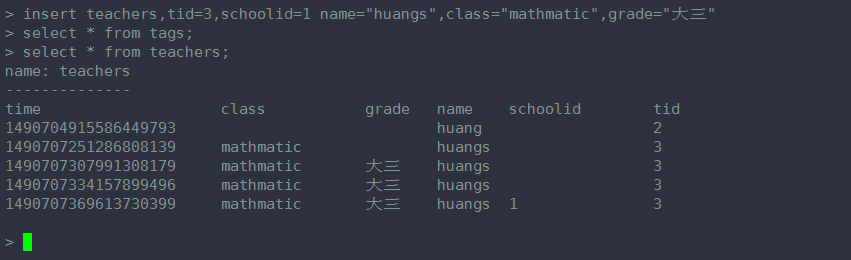
这条语句加了 一个 tag key ------schoolid
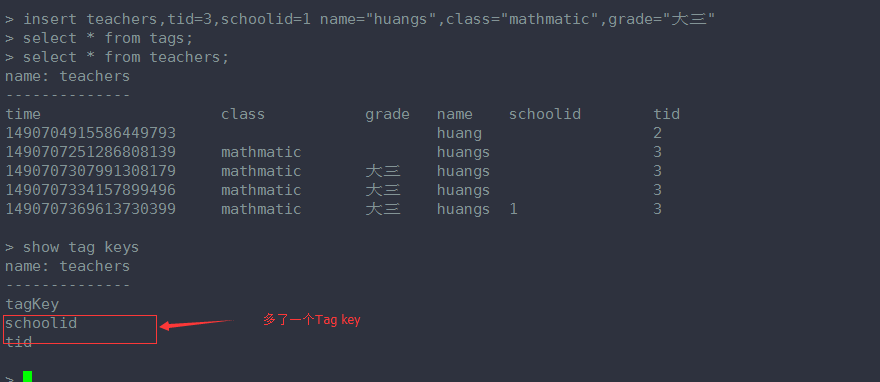
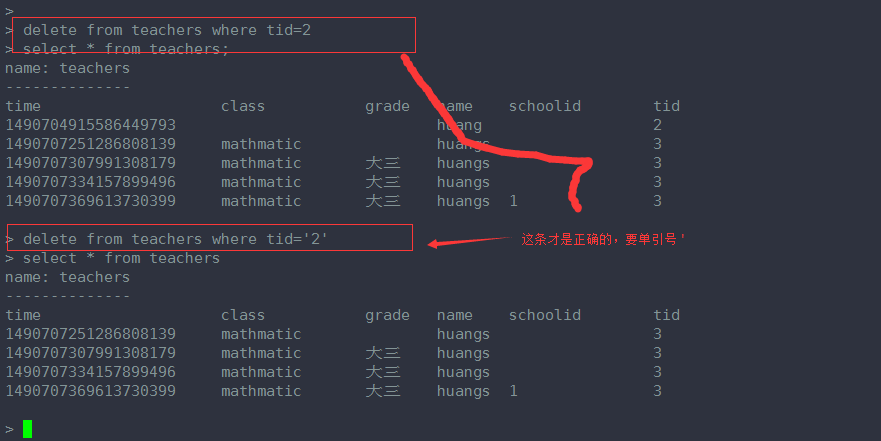
删除
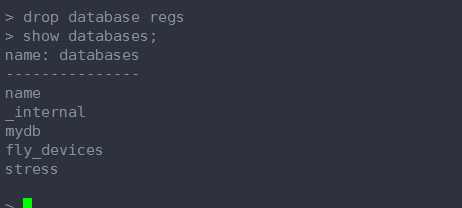
删除整个数据库
influxDB系列(一)的更多相关文章
- InfluxDb系列:几个关键概念(主要是和关系数据库做对比)
https://docs.influxdata.com/influxdb/v0.9/concepts/key_concepts/ #,measurement,就相当于关系数据库中的table,他就是 ...
- InfluxDB系列之一安装及简单运维(未完成,需要继续写)
InfluxDB 是一个开源分布式时序.事件和指标数据库.使用 Go 语言编写,无需外部依赖.其设计目标是实现分布式和水平伸缩扩展. 它有三大特性: 1. Time Series (时间序列):你可以 ...
- influxDB系列(二)
来源于我在一个influxDB的qq交流群中的提问, 然后有个人 提了一个问题---->触发了我的思考!! :) 哈哈 自己的每一次说出一个回答,都是一次新的思考,也都进行了一些查阅资料,思考, ...
- influxDB系列(二)--查看数据库的大小
google 搜索了好多文档,终于发现了这个靠谱的回答. https://groups.google.com/forum/#!topic/influxdb/I5eady_Ta5Y You can se ...
- influxdb系列:一、influxdb概念
根据influxdb的官方文档介绍,它是一个时间序列数据库,但是仅仅从名字却不知道它跟已有的关系型数据库有什么区别? 当学习一个新的东西的时候,我的习惯往往是想知道它和我已掌握的知识的对比关系,这样子 ...
- InfluxDB学习之InfluxDB的安装和简介
最近用到了 InfluxDB,在此记录下学习过程,同时也希望能够帮助到其他学习的同学. 本文主要介绍InfluxDB的功能特点以及influxDB的安装过程.更多InfluxDB详细教程请看:Infl ...
- Influxdb原理详解
本文属于<InfluxDB系列教程>文章系列,该系列共包括以下 15 部分: InfluxDB学习之InfluxDB的安装和简介 InfluxDB学习之InfluxDB的基本概念 Infl ...
- 时序数据库InfluxDB:简介及安装
在性能测试过程中,对测试结果以及的实时监控与展示也是很重要的一部分.这篇博客,介绍下linux环境下InfluxDB的安装以及功能特点. 官网地址:influxdata 官方文档:influxdb文档 ...
- InfluxDB学习之InfluxDB的基本操作| Linux大学
来源地址:https://www.linuxdaxue.com/influxdb-study-series-manual.html 本文属于<InfluxDB系列教程>文章系列,该系列共包 ...
随机推荐
- react开启一个项目 webpack版本出错
npx create-react-app my-app cd my-app npm start 在命令行里执行以上语句就可(前两天刚刚发现,最新版的react对webpack的版本要了新要求,大概是他 ...
- poptip 外面 放 input 使用 iview vue
外层套的是 <FormItem prop="name" label="姓名:"> <Input v-model="tFill.nam ...
- Vue项目结构梳理
Vue项目结构图: 简单介绍目录结构 build目录是一些webpack的文件,配置参数什么的,一般不用动 config是vue项目的基本配置文件 node_modules是项目中安装的依赖模块 sr ...
- 【洛谷2019 OI春令营】期中考试
T68402 扫雷 题目链接:传送门 题目描述 扫雷,是一款单人的计算机游戏.游戏目标是找出所有没有地雷的方格,完成游戏:要是按了有地雷的方格,游戏失败.现在 Bob 正在玩扫雷游戏,你作为裁判要判断 ...
- There is no Action mapped for namespace [/] and action name [updateUser] associated with context path [].
在使用Struts2的时候,遇到了这个问题. 原因分析: 找不到指定的路径, 那么就是struts.xml的内容问题, 或者是struts.xml的文件位置存在问题. struts2默认是应该放在sr ...
- Cycloid Hydraulic Motor Use: Use Failure And Treatment
The cycloidal hydraulic motor is a small low-speed, high-torque hydraulic motor with a shaft-distrib ...
- [MVC][Shopping]Copy Will's Code
数据模型规划(Models) //DisplayNameAttribute 指定属性的显示名称 [DisplayName("商品类别")] //DisplayColumnAttri ...
- SpringCloud源码地址
SpringCloud实战源代码 https://github.com/springcloud/spring-cloud-code.git
- LoadRunner中,参数化时Unique取值方式的理解
LoadRunner中,参数化时Unique取值方式的理解 2012年10月15日 18:10:36 瑞秋 阅读数:10028 在LoadRunner中进行参数化时,Parameter的取值设置有 ...
- XTU 二分图和网络流 练习题 J. Drainage Ditches
J. Drainage Ditches Time Limit: 1000ms Memory Limit: 32768KB 64-bit integer IO format: %I64d Ja ...