python列表中中文编码的问题
在python2列表中,有时候,想打印一个列表,会出现如下显示:

这个是由于:
print一个对象,是输出其“为了给人(最终用户)阅读”而设计的输出形式,那么字符串中的转义字符需要转出来,而且 也不要带标识字符串边界的引号。
因此,单独打印列表中的某一项,譬如:list[0],他可以很好的转义出中文字符。而一个list对象,本身就是个数据结构,如果要把它显示给最终用户看,它不会对里面的数据进行润色。
解决办法参考:https://www.zhihu.com/question/20413029
由此进一步思考:
1、我们在定义字符串的时候,u"中文"的u是什么意思?
string = u"中文"
string.decode('utf8')
可以看到会出异常:
---------------------------------------------------------------------------
UnicodeEncodeError Traceback (most recent call last)
<ipython-input-41-b3abdaf47d60> in <module>()
1 string = u"中文"
----> 2 string.decode('utf8') C:\ProgramData\Anaconda2\lib\encodings\utf_8.pyc in decode(input, errors)
14
15 def decode(input, errors='strict'):
---> 16 return codecs.utf_8_decode(input, errors, True)
17
18 class IncrementalEncoder(codecs.IncrementalEncoder): UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
这说明,string的编码方式并不是utf-8。
我之前一直以为是指的是utf-8的编码方式,其实不然。
2、# -*- coding: utf-8 -*- 和 sys.setdefaultencoding("utf-8")的区别是什么?
# -*- coding: utf-8 -*- :作用于源代码,如果没有定义,源码不能包含中文字符。https://www.python.org/dev/peps/pep-0263/
sys.setdefaultencoding("utf-8") :设置默认的string编码方式
3、decode\encode指定编码解码方式
# -*- coding: utf-8 -*-
import sys
#Python2.5 初始化后删除了 sys.setdefaultencoding 方法,我们需要重新载入
reload(sys)
sys.setdefaultencoding('utf-8') string = "中文"
print repr(string.decode('utf-8'))
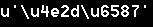
4、unicode编码
字符串通常包含str、unicode两种类型,通常str指字符串编码方式。在Python程序内部,通常使用的字符串为unicode编码,这样的字符串字符是一种内存编码格式,如果将这些数据存储到文件或是记录日志的时候,就需要将unicode编码的字符串转换为特定字符集的存储编码格式,比如:UTF-8、GBK等。
unicode编码:编码表的编号从0一直算到了100多万(三个字节)。每一个区间都对应着一种语言的编码。目前几乎收纳了全世界大部分的字符。所有的字符都有唯一的编号,事实上是一种字符集。但是,unicode把大家都归纳进来,却没有为编码的二进制传输和二进制解码做出规定。于是,就出现了如下解决方案:uft-8,utf-16,utf-32这些编码方案,主要还是为了解决一个信息传输效率的问题,因为如果直接根据字符集进行传输的话,三个字节的表示就会比较低效了。
str 转 unicode
string = "asdf"
string.decode("utf-8")
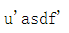
所以,u就是unicode
unicode转 str
string = u"asdf"
string.encode("utf-8")

5、unicode-escape
在将unicode存储到文本的过程中,还有一种存储方式,不需要将unicode转换为实际的文本存储字符集,而是将unicode的内存编码值进行存储,读取文件的时候再反向转换回来,是采用:unicode-escape的转换方式。
unicode到unicode-escape
string = "中文" # 或 u"中文",不影响,因为最终都是unicode的内存编码
string.encode("unicode-escape")
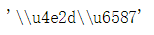
unicode-escape到unicode
string = "中文"
string.decode("unicode-escape")
>> u'\xe4\xb8\xad\xe6\x96\x87
6、string-escape
对于utf-8编码的字符串,在存储的时候,通常是直接存储,而实际上也还有一种存储utf-8编码值的方法,即:string-escape。
str(utf8)到string-escape
string = "中文"
string.encode("string-escape")
>> '\\xe4\\xb8\\xad\\xe6\\x96\\x87'
string-escape到str(utf8)
string = "中文"
string.decode("string-escape")
>>'\xe4\xb8\xad\xe6\x96\x87'
//-------------由上,进一步分析:
a = "中文"
print repr(a.decode("utf-8"))
a = "中文"
print repr(a.decode("unicode-escape"))
print repr(u"中文")
print repr(a)

可以看到,从str转unicode和从unicode-escape转unicode的差距。再比如:
string = '\u4e2d\u6587'
print repr(string.decode("unicode-escape"))
print repr(string.decode("utf8"))

更为清楚的看到,从unicode-escape转unicode,两者没有文本转化的过程,是一个内存转化的过程。而通过str转unicode,会有文本转化,譬如对转义字符的操作。
对于列表中中文编码的解释:
arr = [u"中文"]
print arr
print repr(arr)
pp = str(arr).decode("unicode-escape")#
print pp
print repr(pp)
tt = str(arr).decode("utf-8")
print tt
print repr(tt)
>>[u'\u4e2d\u6587']
>>[u'\u4e2d\u6587']
>>[u'中文']
>>u"[u'\u4e2d\u6587']"
>>[u'\u4e2d\u6587']
>>u"[u'\\u4e2d\\u6587']"
由此可见,想要打印list中的中文,思路是:
通过字符串化处理,将list转化为str(utf-8)文本编码的方式,同时要保留list里面的unicode,避免通过字符处理导致的转义操作,破坏掉中文的unicode,因此选择了unicode-escape
python列表中中文编码的问题的更多相关文章
- 如何在python列表中查找某个元素的索引
如何在python列表中查找某个元素的索引 2019-03-15 百度上回复别人的问题,几种方式的回答: 1) print('*'*15,'想找出里面有重复数据的索引值','*'*15) listA ...
- python 列表中[ ]中冒号‘:’的作用
中括号[ ]:用于定义列表或引用列表.数组.字符串及元组中元素位置 list1 = [, ] list2 = [, , , , , , ] print ] print :] 冒号: 用于定义分片. ...
- python列表中的pop函数
再python的列表中,有许多的内置方法,而在这里我主要向大家介绍一下pop函数. pop函数主要是用于删除列表中的数据.而其删除值时会返回删除的值.如果没有参数传入时, 则会默认认为删除列表的最后一 ...
- Python列表中的字典按照该字典下的键值进行排序
列表中的字典按照该字典下的键值进行排序 这算是排序中比较复杂的一种情况吧,多重嵌套,按照某种规则进行排序.如下面这个json(注:这里这是该列表中的一个项): [ { "stat" ...
- python列表中,多次追加元素
在列表中追加元素,可以使用append(),列表相加也可以用extend()函数,多次追加元素可以用“+”实现 l=[1,2,3,4,5] x=6 y=7 z=8 l=l+[x]+[y]+[z] pr ...
- 在python列表中删除所有空元素
今天在测试数据的时候偶然发现一个问题,如下: test = ['a','','b','','c','',''] for i in test: if i == '': test.remove(i) pr ...
- python 列表中字符串排序故事一则
a = ["bca","cab","abc"] 有时候需要对列表排序 如果是对列表中整个元素 直接用sort()排序 如果想按元素的某一段排 ...
- python列表中的深浅copy
列表中的赋值和平常的赋值是不一样的,看下面的代码: In [1]: a = 1 In [2]: b = a In [3]: a Out[3]: 1 In [4]: b Out[4]: 1 In [5] ...
- Python列表中去重的多种方法
怎么快速的对列表进行去重呢,去重之后原来的顺序会不会改变呢? 去重之后顺序会改变 set去重 列表去重改变原列表的顺序了 l1 = [1,4,4,2,3,4,5,6,1] l2 = list(set( ...
随机推荐
- 【leetcode 简单】 第八十六题 有效的完全平方数
给定一个正整数 num,编写一个函数,如果 num 是一个完全平方数,则返回 True,否则返回 False. 注意:不要使用任何内置的库函数,如 sqrt. 示例 1: 输入: 16 输出: Tr ...
- HDU 1073 Online Judge (字符串处理)
题目链接 Problem Description Ignatius is building an Online Judge, now he has worked out all the problem ...
- 【译】第四篇 Replication:事务复制-订阅服务器
本篇文章是SQL Server Replication系列的第四篇,详细内容请参考原文. 订阅服务器就是复制发布项目的所有变更将传送到的服务器.每一个发布需要至少一个订阅,但是一个发布可以有多个订阅. ...
- vue组件之间传值方式解析
vue组件之间传值方式解析一.父组件传到子组件 1.父组件parent代码如下: <template> <div class="parent"> <h ...
- 【2017-10-1】雅礼集训day1
今天的题是ysy的,ysy好呆萌啊. A: 就是把一个点的两个坐标看成差分一样的东西,以此作为区间端点,然后如果点有边->区间没有交. B: cf原题啊.....均摊分析,简单的那种. 线段树随 ...
- JUnit基本介绍
一.什么是单元测试 单元测试(Unit Testing)是指在计算机编程中,针对程序模块来进行正确性检验的测试工作.单元测试的特点如下: ※ 程序单元是应用最小的可测试部件,通常采用基于类或者类的方 ...
- 【C语言学习笔记】字符串拼接的3种方法 .
昨天晚上和@buptpatriot讨论函数返回指针(malloc生成的)的问题,提到字符串拼接,做个总结. #include<stdio.h> #include<stdlib.h&g ...
- unity3d 材质概述 ---- shader
学习笔记: 材质概述: 物体呈现在我们前面除了形体外,还包括“固有颜色”和“质地”(质感与光学性质).固有颜色让物体的表面看起来是什么颜色,而质感决定了该物质是使用什么材质的.在三维建模软 ...
- TF-tf.nn.dropout介绍
官方的接口是这样的 tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None, name=None) 根据给出的keep_prob参数,将输入te ...
- php rabbitmq的扩展
1.下载:https://github.com/alanxz/rabbitmq-c/archive/v0.9.0.tar.gz mkdir build && cd build # 这一 ...