centos7安装kafka_2.11-1.0.0 新手入门
系统环境
1、操作系统:64位CentOS Linux release 7.2.1511 (Core)
2、jdk版本:1.8.0_121
3、zookeeper版本:zookeeper-3.4.9.tar.gz
4、三台服务器:192.168.1.91; 192.168.1.92; 192.168.1.93;
说明:确保zookeeper集群已经在上面三台服务器上部署成功。可参考之前的文章:centos7安装zookeeper3.4.9集群。
下载kafka
访问网址:http://kafka.apache.org/
左侧导航栏最下面有个Download按钮,点进去
进入网址:http://kafka.apache.org/downloads
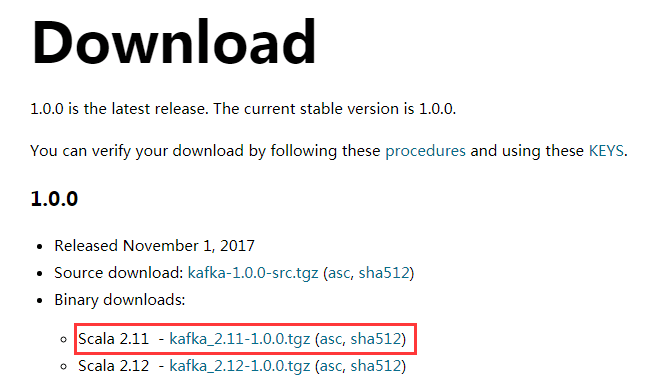
我写这篇笔记的时候,官方建议下载 kafka_2.11-1.0.0.tgz,我们选择编译好的tar包,即上图中红色框框标记的。
拷贝到centos系统
首先还得说明一下,因为我们要做集群,所以每台服务器的配置基本一样,只需要在一台服务器上安装好kafka,然后利用scp命令,拷贝到其它两台服务器,最后修改下参数就行了。所以我只将tar包拷贝到192.168.1.91这台服务器,在这台机器安装好后,拷贝到另外两台机器。
创建软件目录/soft,因为配置zookeeper时,已经创建了/soft目录,所以我们在这里不需要创建了
将在windows系统下载好的tar包利用WinSCP工具拷贝到centos系统(192.168.1.91)的/soft目录
解压kafka
[root@localhost data]# cd /soft
解压
[root@localhost soft]# tar -zxvf kafka_2.11-1.0.0.tgz
移动
[root@localhost soft]# mv kafka_2.11-1.0.0 /usr/local/kafka
配置kafka
[root@localhost local]# cd /usr/local/kafka/config/
[root@localhost config]# vi server.properties
Kafka的配置信息就是在server.properties里面配置的
找到下面两行代码并分别注释
#broker.id=0
#zookeeper.connect=localhost:2181
在文件底部添加如下三个配置:
broker.id=1
zookeeper.connect=192.168.1.91:2181,192.168.1.92:2181,192.168.1.93:2181
listeners = PLAINTEXT://192.168.1.91:9092
说明:如果是单机版的话,默认即可,我们什么都不需要改动。现在我们是要配置集群,所以需要配置一些参数
1、broker.id:每台机器不能一样
2、zookeeper.connect:因为我有3台zookeeper服务器,所以在这里zookeeper.connect设置为3台,必须全部加进去
3、listeners:在配置集群的时候,必须设置,不然以后的操作会报找不到leader的错误
WARN [Producer clientId=console-producer] Error while fetching metadata with correlation id 40 : {test=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
4、看好这一点,另外两台服务器,zookeeper.connect的配置跟这里的一样,但是broker.id和listeners不能一样
拷贝kafka到另外两台服务器
[root@localhost config]# scp -r /usr/local/kafka root@192.168.1.92:/usr/local/
[root@localhost config]# scp -r /usr/local/kafka root@192.168.1.93:/usr/local/
中间会要求输入目标机器的密码,按提示操作就行了,然后修改这两台服务器的broker.id和listeners,如下:
192.168.1.92
[root@localhost data]# cd /usr/local/kafka/config/
[root@localhost config]# vi server.properties
然后按Ctrl+D键,一直定位到文件最底部,修改broker.id和listeners:
broker.id=2
zookeeper.connect=192.168.1.91:2181,192.168.1.92:2181,192.168.1.93:2181
listeners = PLAINTEXT://192.168.1.92:9092
192.168.1.93
[root@localhost data]# cd /usr/local/kafka/config/
[root@localhost config]# vi server.properties
然后按Ctrl+D键,一直定位到文件最底部,修改broker.id和listeners:
broker.id=3
zookeeper.connect=192.168.1.91:2181,192.168.1.92:2181,192.168.1.93:2181
listeners = PLAINTEXT://192.168.1.93:9092
开启相关端口
三台机器都要开启,kafka通信默认是通过9092端口,也就是我们上面配的listeners
[root@localhost config]# firewall-cmd --zone=public --add-port=9092/tcp --permanent
[root@localhost config]# firewall-cmd --reload
启动zookeeper
三台都要启动
[root@localhost config]# /usr/local/zookeeper/bin/zkServer.sh start
启动kafka,
三台都要启动
[root@localhost config]# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
jps命令检查是否启动成功
[root@localhost config]# jps
4352 Kafka
4416 Jps
4088 QuorumPeerMain
表示启动成功
创建topic
[root@localhost ~]# cd /usr/local/kafka/
[root@localhost kafka]# bin/kafka-topics.sh --create --zookeeper 192.168.1.91:2181 --replication-factor 1 --partitions 1 --topic test
如果成功的话,会输出:Created topic "test".
查看topic
虽然在192.168.1.91上创建的topic,但是另外两台机器上也能看到
到192.168.1.93客户端
[root@localhost ~]# cd /usr/local/kafka/
[root@localhost kafka]# bin/kafka-topics.sh --list --zookeeper 192.168.1.92:2181
这里的IP可以是192.168.1.91、192.168.1.92、192.168.1.93中的任何一个,在三台服务器中的任何一台都可以看到
我这里是在93机器上查看92的
创建发布
在192.168.1.91上创建
[root@localhost kafka]# bin/kafka-console-producer.sh --broker-list 192.168.1.91:9092 --topic test
你会看到:

创建消费
在192.168.1.92上消费
[root@localhost kafka]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.92:9092 --topic test --from-beginning
你会看到:
好,至此大功告成
参考网址
参考地址:http://www.cnblogs.com/luotianshuai/p/5206662.html
学习地址:http://orchome.com/kafka/index
官网:http://kafka.apache.org/
centos7安装kafka_2.11-1.0.0 新手入门的更多相关文章
- centos7安装kafka_2.11
1.下载 官网地址:http://kafka.apache.org/downloads.html 下载:wget https://www.apache.org/dyn/closer.cgi?path= ...
- Centos7安装Kubernetes k8s v1.16.0 国内环境
一. 为什么是k8s v1.16.0? 最新版的v1.16.2试过了,一直无法安装完成,安装到kubeadm init那一步执行后,报了很多错,如:node xxx not found等.centos ...
- Centos7安装rabbitmq server 3.6.0
###假设所有操作在opt目录下进行 cd /opt mkdir apps cd apps ### 下载 RabbitMQ Server wget http://www.rabbitmq.com/re ...
- Centos7安装Mono(以4.6.0)为例
本文记录mono安装的必须步骤,由于只是一个记录因此操作系统及mono版本都以当前环境为准. 1:环境依赖 操作系统为CentOS7.0,先安装mono依赖的各种组件: yum -y install ...
- 腾讯云下的CentOS7 安装最新版Python3.7.0
第一步下载Python3.7.0 刚开始我是在windows上下载之后 传到FTP服务器上的 后来发现使用以下命令可以更快捷地下载到服务器 * wget https://www.python.org ...
- 《转》CentOS7 安装MongoDB 3.0server (3.0的优势)
1.下载&安装 MongoDB 3.0 正式版本号公布!这标志着 MongoDB 数据库进入了一个全新的发展阶段,提供强大.灵活并且易于管理的数据库管理系统.MongoDB宣称.3.0新版本号 ...
- Centos7安装percona-xtrabackup2.4和8.0版本
Percona XtraBackup是一个基于MySQL的服务器的开源热备份实用程序 ,它不会在备份期间锁定您的数据库.无论是24x7高负载服务器还是低事务量环境,Percona XtraBackup ...
- CentOS7安装搭建.Net Core 2.0环境-详细步骤
一.构建.Net core 2的应用程web发布 因为是用来测试centos上的core 环境,先直接用vs17自带的core实例. 二.部署CentOS7的core环境 1.连接并启动之前安装的虚拟 ...
- CentOS7 安装Postgresql 11+ 源码编译安装Postgis-2.5.2
####安装Postgresql-11yum install zlib-devel gcc makegroupadd postgresuseradd -g postgres postgrespassw ...
随机推荐
- Flask小demo---代码统计系统
功能要求: 管理员登录 # 第一天 班级管理 # 第一天 学生管理 # 第一天 学生登录 上传代码(zip文件和.py文件) 查看个人提交记录列表 highchar统计 学生列表上方使用柱状图展示现班 ...
- 一、springcloud服务注册、发现、调用(consul/eureka)
1.Spring Cloud简介 Spring Cloud是一个基于Spring Boot实现的云应用开发工具,它为基于JVM的云应用开发中的配置管理.服务发现.断路器.智能路由.微代理.控制总线.全 ...
- Python开发环境(2):启动Eclipse时检测到PYTHONPATH发生改变
OS:Windows 10家庭中文版,Eclipse:Oxygen.1a Release (4.7.1a),PyDev:6.3.2 4月25日,在Eclipse上安装了PyDev(前面博文有记录),并 ...
- 一种获取xml文件某个节点内容的shell方法
配置文件 config.xml <xml> <server> <name>srv-01</name> </server> <serve ...
- ExtJs的Reader
ExtJs的Reader Reader : 主要用于将proxy数据代理读取的数据按照不同的规则进行解析,讲解析好的数据保存到Modle中 结构图 Ext.data.reader.Reader 读取器 ...
- 添加自签发的 SSL 证书为受信任的根证书
原文:http://cnzhx.net/blog/self-signed-certificate-as-trusted-root-ca-in-windows/ 添加自签发的 SSL 证书为受信任的根证 ...
- matlab随笔(二)
circshift 两种形式 :第一种Y = circshift(A,K)就不用说了,将A中的元素向右移动K个位置. 需要注意的是第二种形式:Y = circshift(A,K,dim),这种形式不好 ...
- vue 递归组件
如果你的项目里面的数据结构是一个树状的数据结构 然后递归组件是一个很好的一个解决你这个数据结构的一个方式 就是组件内部调用自身 tree.vue里面直接tree-node <tree-node& ...
- vue.js学习 自定义过滤器使用(2)
gitHub地址: https://github.com/lily1010/vue_learn/tree/master/lesson05 一 自定义过滤器(注册在Vue全局) 注意事项: (1)全局方 ...
- KAFKA随机产生JMX 端口指定的问题
https://blog.csdn.net/weixin_40209426/article/details/82217987