caffe下训练时遇到的一些问题汇总
1、报错:“db_lmdb.hpp:14] Check failed:mdb_status ==0(112 vs.0)磁盘空间不足。”
这问题是由于lmdb在windows下无法使用lmdb的库,所以要改成leveldb。
但是要注意:由于backend默认的是lmdb,所以你每一次用到生成的图片leveldb数据的时候,都要把“--backend=leveldb”带上。如转换图片格式时:
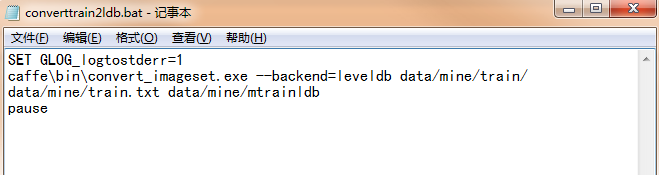
又如计算图像的均值时:
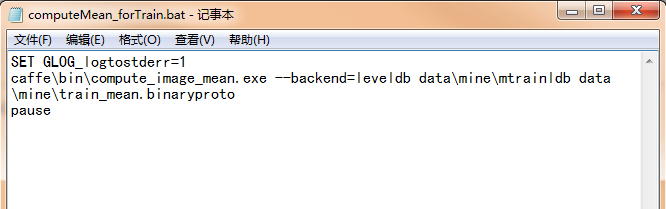
还有在.prototxt中
data_param {
source: "./mysample_val_leveldb"
batch_size:
backend: LEVELDB //这个也要改掉的,原来是LMDB
}
2、caffe下使用“bvlc_reference_caffenet”模型进行训练时,出现了“Check failed:data_”
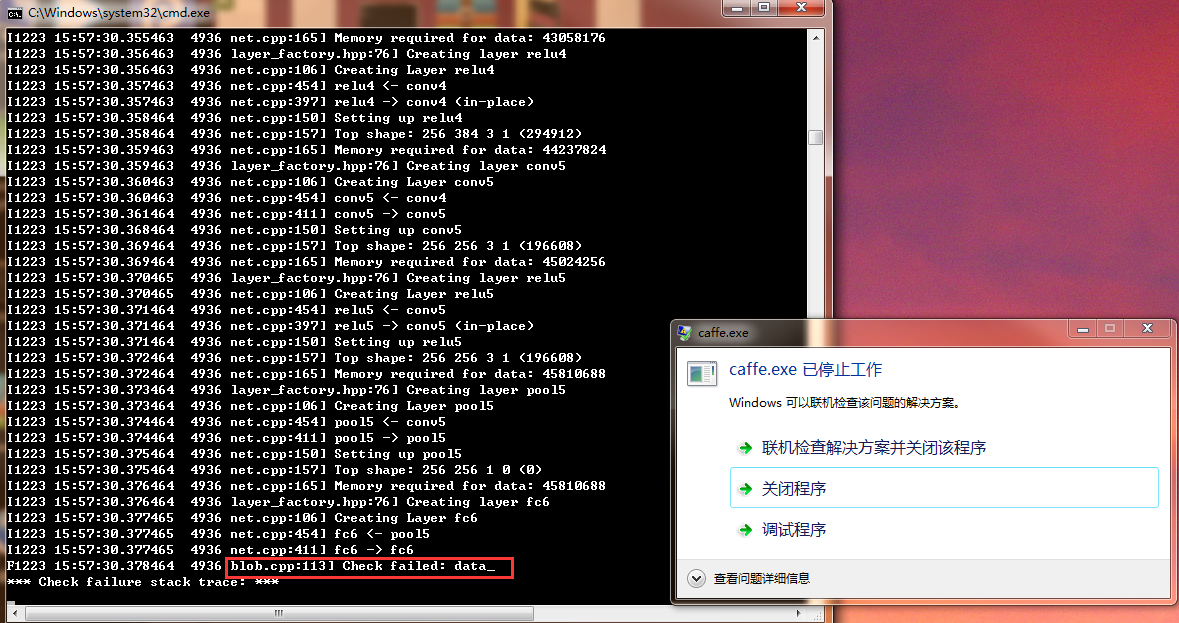
这个问题是由于训练样本的图像尺寸太小了,以至于到pool5池化层的时候输入的尺寸已经小于kernel的大小了,进而下一步输入编程了0x0,因此会报错。
解决的方法是要么在归一化图像尺寸时足够大(小于64*64好像就不行了),要么换用另一种模型(如果图像本身就小,放大图像会丢失图像特征,此时可尝试使用Cifar10模型)
3、caffe训练时遇到loss一直居高不下时:
http://blog.sina.com.cn/s/blog_141f234870102w941.html
我利用caffe训练一个基于AlexNet的三分类分类器,将train_val.prototxt的全连接输出层的输出类别数目改为3,训练一直不收敛,loss很高;当把输出改成4或1000(>3)的时候,网络可以收敛。也就是caffenet结构的输出层的类别数一定要大于我训练集的类别数才可以收敛!后来查了半天才发现原因,让我泪奔。。。
原来我把图像类型的label设置成1,2,3,改成0,1,2后,最后全连接层的输出改为3就OK了。
待更新...!
caffe下训练时遇到的一些问题汇总的更多相关文章
- caffe︱深度学习参数调优杂记+caffe训练时的问题+dropout/batch Normalization
一.深度学习中常用的调节参数 本节为笔者上课笔记(CDA深度学习实战课程第一期) 1.学习率 步长的选择:你走的距离长短,越短当然不会错过,但是耗时间.步长的选择比较麻烦.步长越小,越容易得到局部最优 ...
- 记录:测试本机下使用 GPU 训练时不会导致内存溢出的最大参数数目
本机使用的 GPU 是 GeForce 840M,2G 显存,本机内存 8G. 试验时,使用 vgg 网络,调整 vgg 网络中的参数,使得使用对应的 batch_size 时不会提示内存溢出.使用的 ...
- CAFFE中训练与使用阶段网络设计的不同
神经网络中,我们通过最小化神经网络来训练网络,所以在训练时最后一层是损失函数层(LOSS), 在测试时我们通过准确率来评价该网络的优劣,因此最后一层是准确率层(ACCURACY). 但是当我们真正要使 ...
- caffe 如何训练自己的数据图片
申明:此教程加工于caffe 如何训练自己的数据图片 一.准备数据 有条件的同学,可以去imagenet的官网http://www.image-net.org/download-images,下载im ...
- Windows平台上Caffe的训练与学习方法(以数据库CIFAR-10为例)
Windows平台上Caffe的训练与学习方法(以数据库CIFAR-10为例) 在完成winodws平台上的caffe环境的搭建之后,亟待掌握的就是如何在caffe中进行训练与学习,下面将进行简单的介 ...
- DenseNet算法详解——思路就是highway,DneseNet在训练时十分消耗内存
论文笔记:Densely Connected Convolutional Networks(DenseNet模型详解) 2017年09月28日 11:58:49 阅读数:1814 [ 转载自http: ...
- caffe 下一些参数的设置
weight_decay防止过拟合的参数,使用方式:1 样本越多,该值越小2 模型参数越多,该值越大一般建议值:weight_decay: 0.0005 lr_mult,decay_mult关于偏置与 ...
- faster r-cnn 在CPU配置下训练自己的数据
因为没有GPU,所以在CPU下训练自己的数据,中间遇到了各种各样的坑,还好没有放弃,特以此文记录此过程. 1.在CPU下配置faster r-cnn,参考博客:http://blog.csdn.net ...
- caffe绘制训练过程的loss和accuracy曲线
转自:http://blog.csdn.net/u013078356/article/details/51154847 在caffe的训练过程中,大家难免想图形化自己的训练数据,以便更好的展示结果.如 ...
随机推荐
- windows2012 iis配置
1.打开“组策略” 单击任务栏里的“windows powershell”, 键入 gpedit.msc,然后按 Enter. 2.修改windows 更新源为未配置.“计算机配置”---“管理模板” ...
- 分布式数据库Hbase
HBase – Hadoop Database,是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群. HBase是Goog ...
- deepin 15.3 安装配置nginx
1.安装nginx sudo apt-get install nginx 2.配置nginx sudo gedit /etc/nginx/sites-enabled/default 找到:index ...
- 鼠标拖动在picturebox上画圆时
注意MouseDown MouseMove MouseUp三个事件: MouseMove事件中要实现实时绘制和下次绘制时自动清除重绘 需要: pictureBox1.Invalidate(); pi ...
- 【Beta】第四次任务发布
PM 日常管理&dev版宣传(周日开始). 后端 #99 服务发布 验收条件:使dev版能在www.buaaphylab.com下运行. 前端 #87 登录后能够查看与下载用户收藏的报告.生成 ...
- python面向对象进阶(八)
上一篇<Python 面向对象初级(七)>文章介绍了面向对象基本知识: 面向对象是一种编程方式,此编程方式的实现是基于对 类 和 对象 的使用 类 是一个模板,模板中包装了多个“函数”供使 ...
- 挣值管理(PV、EV、AC、SV、CV、SPI、CPI) 记忆
挣值管理法中的PV.EV.AC.SV.CV.SPI.CPI这些英文简写相信把大家都搞得晕头转向的.在挣值管理法中,需要记忆理解的有三个参数:PV.AC.EV. PV:计划值,在即定时间点前计划 ...
- C# 调用WebService的3种方式 :直接调用、根据wsdl生成webservice的.cs文件及生成dll调用、动态调用
1.直接调用 已知webservice路径,则可以直接 添加服务引用--高级--添加web引用 直接输入webservice URL.这个比较常见也很简单 即有完整的webservice文件目录如下图 ...
- Linux lsof命令 以及 恢复删除的文件
1.简介 lsof(list open files)是一个列出当前系统打开文件的工具.在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件.所以如传 ...
- EF 增删改
一.新增 UserInfo user = new UserInfo() { UserName = "jamsebing", UserPass = " }; db.User ...