java数据结构----哈希表
1.哈希表:它是一种数据结构,可以提供快速的插入操作和查找操作。如果哈希表中有多少数据项,插入和删除操作只需要接近常量的时间。即O(1)的时间级。在计算机中如果需要一秒内查找上千条记录,通常使用哈希表。哈希表的速度明显比树快,编程实现也相对容易。但哈希表是基于数组的,数组创建后难于扩展。某些哈希表被填基本填满后性能下降的非常严重,所以程序员必须清除表中需要存储多少数据,而且也没有简便的方式以任意一种顺序(如由大到小)遍历表中的数据项,如果需要这种能力,只能选择其他数据结构。
2.哈希化:把关键字转化成数组下标的过程称为哈希化。在哈希表中这个转换通过哈希函数来完成。而对于特定的关键字,并不需要哈希函数,关键字的值可以直接作为数组下标。
3.冲突:把巨大的数字空间压缩成较小的数字空间必然要付出代价,即不能保证每个单词都映射到数组的空白单元。假设要在数组中插入单词cat,通过哈希函数得到它的数组下标后,发现那个单元已经有一个单词了,对于特定大小的数组,这种情况称为冲突。冲突使得哈希化的方案无法实施,解决的方案有两种,一种是通过系统的方法找到数组的一个空位,并把单词填入,而不再用哈希函数得到的下标,这种方法称为开放地址法,第二种方案是创建一个存放单词链表的数组,数组不直接用来存储单词,这样发生冲突时,新的数据项就直接插入这个数组下标所指向的链表中,这种方法称为链地址法。
3-1.开放地址法的具体实现有三种不同方案,线性探测,二次探测和再哈希法。
3-1-1.线性探测:在线性探测中,线性的查找空白单元,如果5421是要插入的数据位置,它已被占用,那么就使用5422,然后是5423,依次类推,直到找到这个空位。
3-1-1-1.存在的问题:会出现聚集情况。也叫原始聚集
3-1-2.二次探测:二次探测是防止聚集产生的一种尝试,思想是探测相隔较远的单元。而不知和原始单元相邻的单元。在二次探测中,探测的过程是x+1,x+4,x+9,x+16....
3-1-2-1.问题:存在二次聚集。
3-1-3.再哈希法:为了消除原始聚集和二次聚集,引入了再哈希法,二次聚集产生的原因是,二次探测的算法产生的探测序列步长总是固定的:1,4,9,16...现在需要一 种方法是依赖关键字的探测序列,方法是把关键字用相同的哈希函数再做一次哈希化,用这个结果作为步长,对指定的关键字步长在整个探测过程中是不变的,第二个哈希函数必须具备以下特点:a.和第一个哈希函数不同,b.不能输出0(否则就没有步长,将先入死循环)专家发现类似于stepsize = constant - (key % constant)的形式工作的很好,其中个constant是质数,且小于数组容量。(stepsize = 5 - (key % 5)),这种方案最为常用。
3-2.链地址法图示: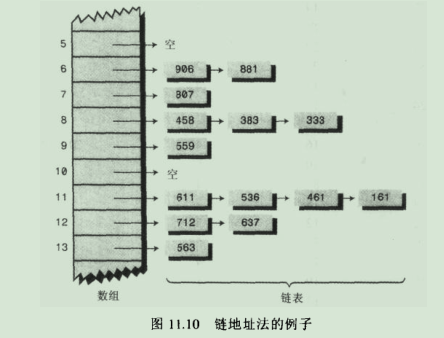
3-2-1.缺点:链地址法在概念上比开放地址法简单,但是代码可能要比其他的长,因为要包含链表机制,这就要求在程序中增加一个类。
4.再哈希法实现代码:
4.1.DataItem.java
package com.cn.hashtable;
/**
* 再哈希法
* @author Administrator
*
*/
public class DataItem {
private int iData;
public DataItem(int id){
iData = id;
}
public int getkey(){
return iData;
}
}
4.2.HashTable.java
package com.cn.hashtable;
/**
* 哈希表算法开放地址法---再哈希实现
* @author Administrator
*
*/
public class HashTable {
private DataItem[] hashArray;
private int arraySize;
private DataItem nonItem;
HashTable(int size){
arraySize = size;
hashArray = new DataItem[arraySize];
nonItem = new DataItem(-1);
}
public void displayTable(){
System.out.print("Table:");
for (int i = 0; i < arraySize; i++) {
if (hashArray[i] != null)
System.out.print(hashArray[i].getkey()+" ");
else
System.out.print("** ");
}
System.out.println("");
}
public int hashFunc1(int key){
return key % arraySize;
}
public int hashFunc2(int key){
return 5 - key % 5;
}
public void insert(int key,DataItem item){
int hashval = hashFunc1(key);
int stepsize = hashFunc2(key);
while (hashArray[hashval] != null && hashArray[hashval].getkey() != 1){
hashval += stepsize;
hashval %= arraySize;
}
hashArray[hashval] = item;
}
public DataItem delete(int key){
int hashval = hashFunc1(key);
int stepsize = hashFunc2(key);
while (hashArray[hashval] != null){
if (hashArray[hashval].getkey() == key){
DataItem temp = hashArray[hashval];
hashArray[hashval] = nonItem;
return temp;
}
hashval += stepsize;
hashval %= arraySize;
}
return null;
}
public DataItem find(int key){
int hashval = hashFunc1(key);
int stepsize = hashFunc2(key);
while (hashArray[hashval] != null){
if (hashArray[hashval].getkey() == key)
return hashArray[hashval];
hashval += stepsize;
hashval %= arraySize;
}
return null;
}
}
4.3.HTTest.java
package com.cn.hashtable;
/**
* 测试类
* @author Administrator
*
*/
public class HTTest {
public static void main(String[] args) {
HashTable t = new HashTable(10);
t.insert(1, new DataItem(1));
t.insert(2, new DataItem(2));
t.insert(4, new DataItem(3));
t.insert(3, new DataItem(4));
t.insert(2, new DataItem(5));
t.insert(9, new DataItem(6));
t.displayTable();
t.delete(9);
System.out.println(t.find(9));
}
}
5.链地址法实现:
5.1.Link.java
package com.cn.hashtable;
/**
* 链地址法实现
* @author Administrator
*
*/
public class Link {
public int iData;
public Link next;
public Link(int it){
iData = it;
}
public int getkey(){
return iData;
}
public void displayLink(){
System.out.print(iData+" ");
}
}
5.2.SortedList.java
package com.cn.hashtable;
public class SortedList {
private Link first;
public void insert(Link thelink){
int key = thelink.getkey();
Link previous = null;
Link current = first;
while (current != null && key > current.getkey()){
previous = current;
current = current.next;
}
if (previous == null)
first = thelink;
else
previous.next = thelink;
thelink.next = current;
}
public void delete(int key){
Link previous = null;
Link current = first;
while (current != null && key != current.getkey()){
previous = current;
current = current.next;
}
if (previous == null)
first = first.next;
else
previous.next = current.next;
}
public Link find(int key){
Link current = first;
while (current != null && current.getkey() <= key){
if (current.getkey() == key)
return current;
current = current.next;
}
return null;
}
public void displayList(){
System.out.print("list:first-->last: ");
Link current = first;
while (current != null){
current.displayLink();
current = current.next;
}
System.out.println("");
}
}
5.3.LHashTable.java
package com.cn.hashtable;
/**
* 链地址法实现哈希表类
* @author Administrator
*
*/
public class LHashTable {
private SortedList[] hashArray;
private int arraySize;
public LHashTable(int size){
arraySize = size;
hashArray = new SortedList[arraySize];
for (int i = 0; i < arraySize; i++) {
hashArray[i] = new SortedList();
}
}
public void display(){
for (int i = 0; i < arraySize; i++) {
System.out.print(i+". ");
hashArray[i].displayList();
}
System.out.println("");
}
public int hashFunc(int key){
return key % arraySize;
}
public void insert(Link thelink){
int key = thelink.getkey();
int hashval = hashFunc(key);
hashArray[hashval].insert(thelink);
}
public void delete(int key){
int hashval = hashFunc(key);
hashArray[hashval].delete(key);
}
public Link find(int key){
int hashval = hashFunc(key);
Link thelink = hashArray[hashval].find(key);
return thelink;
}
}
5.4.LHTTest.java
package com.cn.hashtable;
/**
* 链地址法实现测试类
* @author Administrator
*
*/
public class LHTTest {
public static void main(String[] args) {
LHashTable lt = new LHashTable(10);
for (int i = 0; i < 5; i++) {
lt.insert(new Link(i));
}
lt.display();
}
}
6.哈希化的效率:在哈希表中执行插入和搜索操作可以达到O(1)的时间级,如果没有遇到冲突,就只需要使用一次哈希函数和数组的引用。这是最小的存取时间级。如果发生冲突,存取时间就依赖后边的探测长度。因此,一次的查找或插入操作与探测长度成正比,平均探测长度取决于装填因子(表中项数和表长的比率),随着填装因子变大,探测长度也越来越长。
6.1.线性探测时,探测序列(p)和填装因子(L)的关系:成功查找:P = (1 + 1/(1 - L)^2)/2;不成功查找:(1 + 1/(1 - L))/2,随着装填因子变小,存储效率下降而速度上升。
6.2.二次探测和再哈希法:对成功的搜索公式是:-log2(1 - loadfactor)/loadfactor;不成功的查找:1/(1-loadfactor)
6.3.假设哈希表含有arraySize个数据项,每个数据项有一个链表,在表中有N个数据项:averageListLength = N/arraySize;成功查找:1+loadfactor/2;不成功的查找:1+loadfactor
java数据结构----哈希表的更多相关文章
- JAVA数据结构--哈希表的实现(分离链接法)
哈希表(散列)的定义 散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构.也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度 ...
- java数据结构——哈希表(HashTable)
哈希表提供了快速的插入操作和查找操作,每一个元素是一个key-value对,其基于数组来实现. 一.Java中HashMap与Hashtable的区别: HashMap可以接受null键值和值,而Ha ...
- Java数据结构——哈希表
- Java中哈希表(Hashtable)是如何实现的
Java中哈希表(Hashtable)是如何实现的 Hashtable中有一个内部类Entry,用来保存单元数据,我们用来构建哈希表的每一个数据是Entry的一个实例.假设我们保存下面一组数据,第一列 ...
- (js描述的)数据结构[哈希表1.1](8)
(js描述的)数据结构[哈希表1.1](8) 一.数组的缺点 1.数组进行插入操作时,效率比较低. 2.数组基于索引去查找的操作效率非常高,基于内容去查找效率很低. 3.数组进行删除操作,效率也不高. ...
- openssl lhash 数据结构哈希表
哈希表是一种数据结构,通过在记录的存储位置和它的关键字之间建立确定的对应关系,来快速查询表中的数据: openssl lhash.h 为我们提供了哈希表OPENSSL_LHASH 的相关接口,我们可以 ...
- Java数据结构之线性表(2)
从这里开始将要进行Java数据结构的相关讲解,Are you ready?Let's go~~ java中的数据结构模型可以分为一下几部分: 1.线性结构 2.树形结构 3.图形或者网状结构 接下来的 ...
- Java数据结构之线性表
从这里开始将要进行Java数据结构的相关讲解,Are you ready?Let's go~~ java中的数据结构模型可以分为一下几部分: 1.线性结构 2.树形结构 3.图形或者网状结构 接下来的 ...
- java数据结构之hash表
转自:http://www.cnblogs.com/dolphin0520/archive/2012/09/28/2700000.html Hash表也称散列表,也有直接译作哈希表,Hash表是一种特 ...
随机推荐
- Shell中括号的作用
Shell中括号的作用 作者:Danbo 时间:2015-8-7 单小括号() ①.命令组.括号中的命令将会断开一个子Shell顺序执行,所以括号中的变量不能被脚本余下的部分使用.括号中多个命令之间用 ...
- Vue.js的动态组件模板
组件并不总是具有相同的结构.有时需要管理许多不同的状态.异步执行此操作会很有帮助. 实例: 组件模板某些网页中用于多个位置,例如通知,注释和附件.让我们来一起看一下评论,看一下我表达的意思是什么.评论 ...
- 动态注册BroadcastReceiver
1. [代码][Java]代码 package com.zjt.innerreceiver; import android.app.Service; import android.con ...
- Idea中的插件-列出Java Bean的所有set方法
插件的git 地址: https://github.com/yoke233/genSets 将插件jar导入idea中,使用方式是对象后加.allset,然后回车.
- 限制远程桌面登录IP的方法
转自:http://www.cnblogs.com/vaexi/articles/2106623.html 限制远程桌面登录IP的方法 第一种方法: 1.打开Windows自带的防火墙2.开放允许例外 ...
- 进程优先级、nice值
进程cpu资源分配就是指进程的优先权(priority).优先权高的进程有优先执行权利.配置进程优先权对多任务环境的linux很有用,可以改善系统性能.还可以把进程运行到指定的CPU上,这样一来,把不 ...
- 快速沃尔什变换(FWT)学习笔记 + 洛谷P4717 [模板]
FWT求解的是一类问题:\( a[i] = \sum\limits_{j\bigoplus k=i}^{} b[j]*c[k] \) 其中,\( \bigoplus \) 可以是 or,and,xor ...
- C/C++获取Windows系统CPU和内存及硬盘使用情况
//1.获取Windows系统内存使用率 //windows 内存 使用率 DWORD getWin_MemUsage(){ MEMORYSTATUS ms; ::GlobalMemoryStatus ...
- vue render函数使用jsx语法 可以使用v-model语法 vuex实现数据持久化
render函数使用jsx语法: 安装插件 transform-vue-jsx 可以使用v-model语法安装插件 jsx-v-model .babelrc文件配置: vuex实现数据持久化 安装插 ...
- 利用python数据分析panda学习笔记之Series
1 Series a:类似一维数组的对象,每一个数据与之相关的数据标签组成 b:生成的左边为索引,不指定则默认从0开始. from pandas import Series,DataFrame imp ...