Golang 网络爬虫框架gocolly/colly 五 获取动态数据
Golang 网络爬虫框架gocolly/colly 五 获取动态数据
gcocolly+goquery可以非常好地抓取HTML页面中的数据,但碰到页面是由Javascript动态生成时,用goquery就显得捉襟见肘了。解决方法有很多种,一,最笨拙但有效的方法是字符串处理,go语言string底层对应字节数组,复制任何长度的字符串的开销都很低廉,搜索性能比较高;二,利用正则表达式,要提取的数据往往有明显的特征,所以正则表达式写起来比较简单,不必非常严谨;三,使用浏览器控件,比如webloop;四,直接操纵浏览器,比如chromedp。一和二需要goquery提取javascript,然后再提取数据,速度非常快;三和四不需要分析脚本,在浏览器执行JavaScript生成页面后再提取,是比较偷懒的方式,但缺点是执行速度很慢,如果在脚本非常复杂、懒得分析脚本的情况下,牺牲下速度也是不错的选择。
不同的场景,做不同的选择。中证指数有限公司下载中心提供了行业市盈率下载,数据文件的Url在页面的脚本中,脚本简单且特征明显,直接用正则表达式的方式是最好的选择。

下载地址对应一段脚本
<a href="javascript:;" class="ml-20 dl download1">下载<i class="i_icon i_icon_rar ml-5"></i></a>
<script>
$(function() {
//切换
$('.hysyl_con').rTabs({
bind: 'click',
auto: false,
});
tabs($('.snav .tab_item'),$('.sCon .tab-con-item'));
tabs($('.snav2 .tab_item'),$('.sCon2 .tab-con-item'));
tabs($('.snav3 .tab_item'),$('.sCon3 .tab-con-item'));
$("#search_code1").on("click",function(){
var csrc_code = $("#csrc_code1").val();
if (csrc_code == '') {
return false;
}
var url = "http://www.csindex.com.cn/zh-CN/downloads/industry-price-earnings-ratio-detail?date=2018-01-19&class=1&search=1&csrc_code="+csrc_code;
$("#link_1").attr('href', url);
document.getElementById("link_1").click();
})
$("#search_code2").on("click",function(){
var csrc_code = $("#csrc_code2").val();
if (csrc_code == '') {
return false;
}
var url = "http://www.csindex.com.cn/zh-CN/downloads/industry-price-earnings-ratio-detail?date=2018-01-19&class=1&search=1&csrc_code="+csrc_code;
$("#link_2").attr('href', url);
document.getElementById("link_2").click();
})
})
$(".download1").on("click",function(){
var date = $(".date1").val();
date = date.replace(/\-/g, '');
if (date) {
$("#link1").attr('href', 'http://115.29.204.48/syl/'+date+'.zip');
document.getElementById("link1").click();
}
});
$(".download2").on("click",function(){
var date = $(".date2").val();
date = date.replace(/\-/g, '');
if (date) {
$("#link2").attr('href', 'http://115.29.204.48/syl/csi'+date+'.zip');
document.getElementById("link2").click();
}
});
$(".download3").on("click",function(){
var date = $(".date3").val();
date = date.replace(/\-/g, '');
if (date) {
$("#link3").attr('href', 'http://115.29.204.48/syl/bk'+date+'.zip');
document.getElementById("link3").click();
}
});
</script>
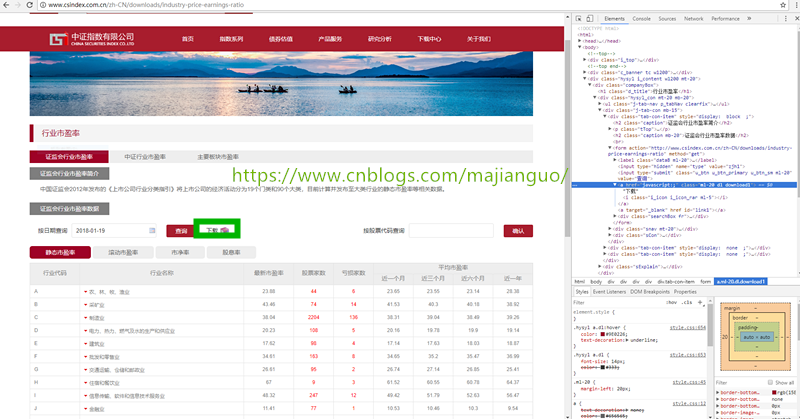
点击下载时,为link1元素生成href属性,然后点击link1,这需要用gocolly+goquery提取date,然后获取服务器地址http://115.29.204.48/,根据获取文件的类型拼接字符串生成下载地址。
获取交易日期
sTime := ""
var bodyData []byte
c:= colly.NewCollector()
c.OnResponse(func (resp *colly.Response) {
bodyData = resp.Body
})
c.OnHTML("input[name=date]",func (el *colly.HTMLElement) {
sTime = el.Attr("value")
})
err = c.Visit("http://www.csindex.com.cn/zh-CN/downloads/industry-price-earnings-ratio")
if err != nil {
return
}
获取文件服务器地址,下载zip文件
htmlDoc,err := goquery.NewDocumentFromReader(bytes.NewReader(bodyData))
if err != nil {
return
}
scripts := htmlDoc.Find("script")
destScript := ""
for _,n := range scripts.Nodes {
if n.FirstChild != nil {
if strings.Contains(n.FirstChild.Data,"syl/csi") && strings.Contains(n.FirstChild.Data,".download2"){
destScript = n.FirstChild.Data
break
}
}
}
re,err := regexp.Compile("http://[0-9]+.[0-9]+.[0-9]+.[0-9]+/syl/csi")
if err != nil {
log.Fatal(err)
}
result := re.FindString(destScript)
pos := strings.LastIndex(result,"/")
parentUrl := result[0:pos+1]
link := parentUrl
sTime = strings.Replace(sTime,"-","",-1)
fileName := ""
if t == ZhengJjianHuiHangYePERatio {
fileName = fmt.Sprintf("%s.zip",sTime)
link += fileName
fileName = "zjh"+fileName
}else if t == ZhongZhengHangYePERatio {
fileName = fmt.Sprintf("csi%s.zip",sTime)
link += fileName
}else {
fileName = fmt.Sprintf("bk%s.zip",sTime)
link += fileName
}
fmt.Println(link)
cli:=http.Client{}
resp,err := cli.Get(link)
if err != nil {
return
}
defer resp.Body.Close()
fullFileName := fmt.Sprintf("%s/%s",filePath,fileName)
if resp.StatusCode == 200 {
allBody,err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
err = ioutil.WriteFile(fullFileName,allBody,0666)
if err != nil {
return err
}
}else{
err = fmt.Errorf("bad resp.%d",resp.StatusCode)
return
}
err = archiver.Zip.Open(fullFileName, filePath)
在脚本里匹配服务器ip地址用 http://[0-9]+.[0-9]+.[0-9]+.[0-9]+/syl/csi
,因为前后都有限定元素,所以写得比较简单;如果没有前后限定条件,设计正则表达式就得多费心了,复杂的正则表达式会吓跑很多人。不过没关系,稍微了解一些正则表达式的知识,就可以用在爬虫上了。
下载的文件是excel(.xls格式)的zip压缩包,解压缩操纵及xls读取后面再介绍。
转载请注明出处:https://www.cnblogs.com/majianguo/
Golang 网络爬虫框架gocolly/colly 五 获取动态数据的更多相关文章
- Golang 网络爬虫框架gocolly/colly 四
Golang 网络爬虫框架gocolly/colly 四 爬虫靠演技,表演得越像浏览器,抓取数据越容易,这是我多年爬虫经验的感悟.回顾下个人的爬虫经历,共分三个阶段:第一阶段,09年左右开始接触爬虫, ...
- Golang 网络爬虫框架gocolly/colly 一
Golang 网络爬虫框架gocolly/colly 一 gocolly是用go实现的网络爬虫框架,目前在github上具有3400+星,名列go版爬虫程序榜首.gocolly快速优雅,在单核上每秒可 ...
- Golang 网络爬虫框架gocolly/colly 三
Golang 网络爬虫框架gocolly/colly 三 熟悉了<Golang 网络爬虫框架gocolly/colly一>和<Golang 网络爬虫框架gocolly/colly二& ...
- Golang 网络爬虫框架gocolly/colly 二 jQuery selector
Golang 网络爬虫框架gocolly/colly 二 jQuery selector colly框架依赖goquery库,goquery将jQuery的语法和特性引入到了go语言中.如果要灵活自如 ...
- 试验一下Golang 网络爬虫框架gocolly/colly
参考:http://www.cnblogs.com/majianguo/p/8186429.html 框架源码在 github.com/gocolly/colly 代码如下(github源码中的dem ...
- 基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库)
原文地址http://blog.csdn.net/qy20115549/article/details/52203722 本文为原创博客,仅供技术学习使用.未经允许,禁止将其复制下来上传到百度文库等平 ...
- 网络爬虫框架Scrapy简介
作者: 黄进(QQ:7149101) 一. 网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本:它是一个自动提取网页的程序,它为搜索引擎从万维 ...
- [原创]一款基于Reactor线程模型的java网络爬虫框架
AJSprider 概述 AJSprider是笔者基于Reactor线程模式+Jsoup+HttpClient封装的一款轻量级java多线程网络爬虫框架,简单上手,小白也能玩爬虫, 使用本框架,只需要 ...
- Python爬虫框架Scrapy实例(三)数据存储到MongoDB
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中. items.py文件复制代码# -*- coding: utf-8 ...
随机推荐
- WebAPI返回JSON
web api写api接口时默认返回的是把你的对象序列化后以XML形式返回,那么怎样才能让其返回为json呢,下面就介绍两种方法: 方法一:(改配置法) 找到Global.asax文件,在Applic ...
- 【python】函数返回值
- npm发布vue组件流程
初始化项目vue init webpack-simple XXX 定义组件略 发布配置1.package.json 2.webpack.config.js(注释部分为原配置) 发布1.登录 2.发布n ...
- 豹哥嵌入式讲堂:ARM开发中有用的文件(1)- source文件
大家好,我是豹哥,猎豹的豹,犀利哥的哥.今天豹哥给大家讲的是嵌入式开发里的source文件种类. 众所周知,嵌入式开发属于偏底层的开发,主要编程语言是C和汇编.所以本文要讲的source文件主要指的就 ...
- Linux(CentOS6.5)下编译安装Nginx1.10.1
首先在特权账号(root)下安装编译时依赖项: yum install gcc gcc-c++ perl -y 首先以非特权账号(本文以账号comex为例)登陆OS: 进入data目录下载相关安装 ...
- K:java中序列化的两种方式—Serializable或Externalizable
在java中,对一个对象进行序列化操作,其有如下两种方式: 第一种: 通过实现java.io.Serializable接口,该接口是一个标志接口,其没有任何抽象方法需要进行重写,实现了Serializ ...
- oracle 处理时间和金额大小写的相关函数集合
CREATE OR REPLACE FUNCTION MONEY_TO_CHINESE(MONEY IN VARCHAR2) RETURN VARCHAR2 IS C_MONEY ); M_STRIN ...
- think queue 消息队列初体验
使用的是tp5 自带的消息队列 thinkphp top里的 消息队列框架 think-queue 这是thinkphp官方团队开发的一个专门支持队列服务的扩展包 消息队列应用场景: 消息队列适用于 ...
- Tablayout ViewPage 使用示例
上一篇文章介绍了使用 FragmenttabHost 来使用 tab 导航:到 Android 5.0 的时候,又推出了 TabLayout.因此,有必要对tablayout 进行了解下. 首先我们来 ...
- jquery.cookie的path坑
在使用jquery.cookie设置cookie的时候,通常都是直接设置,没有针对path,domain和expires等进行具体的设置,这会导致,同一个cookie的key对应多个value. 1. ...