python 面对post分页爬虫

分享一则对于网抓中面对post请求访问的页面或者在分页过程中需要post请求才可以访问的内容!
面的post请求的网址是不可以零参访问网址的,所以我们在网抓的过程中需要给请求传表单数据,下面看一下网页中post请求的网址:

post请求状态码和get请求的状态码一致,但是在参数中我们可以看到表单数据有很多的参数:
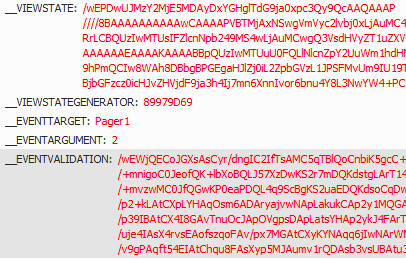
其中的__VIEWSTATE是必须要传的参数,而这个参数是在源码中能获取到的,这个__VIEWSTATE是asp.net中特有的,所以只有在访问asp.net的网站的时候这个参数是必须传的,其他的网站,只要有参数变化的表单数据就需要传到post请求中!
我们在转页的过程中会看到类似于这样的 表单,那后面的数字就是我们转页后的页码!所以我们的这个参数也要传,获取转页的页码的总数,同样可以在源码中获取,如果只显示了1234页,那就需要计算你需要的内容有多少个,每一页的内容个数,做一个取余算法就可以算出来了!
表单,那后面的数字就是我们转页后的页码!所以我们的这个参数也要传,获取转页的页码的总数,同样可以在源码中获取,如果只显示了1234页,那就需要计算你需要的内容有多少个,每一页的内容个数,做一个取余算法就可以算出来了!
现在定义一个post_data:
post_data={"__EVENTTARGET":"Pager1","__EVENTARGUMENT":page_num,"ddlManufacturer":"","Pager1_input":str(page_num-1)}
这是我自定义的post参数,page_num代表着分页的页码。
__VIEWSTATE是在源码中,这里分享的是xpath方法:
a = doc.xpath('//input[@id="__VIEWSTATE"]')
if len(a) > 0:
post_data['__VIEWSTATE'] = a[0].get('value')
使用BeautifulSoup就是:
soup = BeautifulSoup(h,"html.parser")
a = soup.find('input',id='__VIEWSTATE')
if a:
post_data['__VIEWSTATE'] = a['value']
获取到重要的表单数据后,我们就只需要传参访问网页源码了!
r2 = requests.post(url,data=post_data,headers=headers,timeout=20)
ht2 = r2.content #这里就是访问的网页源码!
xpath的解析代码: doc2 = HTML.document_fromstring(网页源码)
网页的简单post请求就是这样来传递参数,访问的!我自己还有很多的学习资料分享在607021567qq群里面了!还有微信飞机大战的源代码分享!
python 面对post分页爬虫的更多相关文章
- Python初学者之网络爬虫(二)
声明:本文内容和涉及到的代码仅限于个人学习,任何人不得作为商业用途.转载请附上此文章地址 本篇文章Python初学者之网络爬虫的继续,最新代码已提交到https://github.com/octans ...
- 零基础入门Python实战:四周实现爬虫网站 Django项目视频教程
点击了解更多Python课程>>> 零基础入门Python实战:四周实现爬虫网站 Django项目视频教程 适用人群: 即将毕业的大学生,工资低工作重的白领,渴望崭露头角的职场新人, ...
- Python - 面对对象(进阶)
目录 Python - 面对对象(进阶) 类的成员 一. 字段 二. 方法 三. 属性 类的修饰符 类的特殊成员 Python - 面对对象(进阶) 类的成员 一. 字段 字段包括:普通字段和静态字段 ...
- 【Python】:简单爬虫作业
使用Python编写的图片爬虫作业: #coding=utf-8 import urllib import re def getPage(url): #urllib.urlopen(url[, dat ...
- 使用python/casperjs编写终极爬虫-客户端App的抓取-ZOL技术频道
使用python/casperjs编写终极爬虫-客户端App的抓取-ZOL技术频道 使用python/casperjs编写终极爬虫-客户端App的抓取
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
前面一直强调Python运用到网络爬虫方面很有效,这篇文章也是结合学习的Python视频知识及我研究生数据挖掘方向的知识.从而简介下Python是怎样爬去网络数据的,文章知识很easy ...
- 洗礼灵魂,修炼python(69)--爬虫篇—番外篇之feedparser模块
feedparser模块 1.简介 feedparser是一个Python的Feed解析库,可以处理RSS ,CDF,Atom .使用它我们可从任何 RSS 或 Atom 订阅源得到标题.链接和文章的 ...
- 洗礼灵魂,修炼python(50)--爬虫篇—基础认识
爬虫 1.什么是爬虫 爬虫就是昆虫一类的其中一个爬行物种,擅长爬行. 哈哈,开玩笑,在编程里,爬虫其实全名叫网络爬虫,网络爬虫,又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者 ...
- 使用Python + Selenium打造浏览器爬虫
Selenium 是一款强大的基于浏览器的开源自动化测试工具,最初由 Jason Huggins 于 2004 年在 ThoughtWorks 发起,它提供了一套简单易用的 API,模拟浏览器的各种操 ...
随机推荐
- 【学习】如何用jQuery获取iframe中的元素
(我的博客网站中的原文:http://www.xiaoxianworld.com/archives/292,欢迎遇到的小伙伴常来瞅瞅,给点评论和建议,有错误和不足,也请指出.) 说实在的,以前真的很少 ...
- 文本可视化[二]——《今生今世》人物关系可视化python实现
文本可视化[二]--<今生今世>人物关系可视化python实现 在文本可视化[一]--<今生今世>词云生成与小说分析一文中,我使用了jieba分词和wordcloud实现了,文 ...
- 【转】C语言产生随机数
原文地址:http://www.cnblogs.com/xianghang123/archive/2011/08/24/2152404.html 在C语言中,rand()函数可以用来产生随机数,但是这 ...
- JAVA 编码解码
涉及编码的地方一般都在从字符到字节或是从字节到字符间的转换上 1.在IO中存在的编码,主要是 FileOutputStream 和 FileInputStream,在使用时需要指定字符集,而不是使用系 ...
- 求最小生成树——Kruskal算法
给定一个带权值的无向图,要求权值之和最小的生成树,常用的算法有Kruskal算法和Prim算法.这篇文章先介绍Kruskal算法. Kruskal算法的基本思想:先将所有边按权值从小到大排序,然后按顺 ...
- PHP二分查找算法
思路:递归算法.在一个已经排好序的数组中查找某一个数值,每一次都先跟数组的中间元素进行比较,若相等则返回中间元素的位置,若小于中间元素,则在数组中小于中间元素的部分查找,若大于中间元素,则在数组中大于 ...
- linux root修改密码失败
问题: 当使用root修改密码时,报错passwd:Authentication token manipulation error 解决: 1.查看是否权限问题, /etc/passwd /etc/s ...
- ssh免密码记录
主机器A通过ssh连多台从机器(b1,b2,b3). 1.使用root用户操作,避免权限问题. 2.在主从机器中安装ssh,命令: ssh-keygen –t rsa 然后都回车,生成的文件在/roo ...
- windows 上rsync客户端使用方法
1.1 获取 windows上实现rsync的软件(cwRsync) cwRsync是Windows 客户端GUI的一个包含Rsync的包装.您可以使用cwRsync快速远程文件备份和同步. 1.1. ...
- Java开发必装的IntelliJ IDEA插件
IDEA 插件简介 常见的IDEA插件主要有如下几类: 常用工具支持 Java日常开发需要接触到很多常用的工具,为了便于使用,很多工具也有IDEA插件供开发使用,其中大部分已经在IDEA中默认集成了. ...